杭州95后学霸坐C位,Grok 3登顶App Store!Hinton高徒、多伦多华人博士领衔
杭州95后学霸坐C位,Grok 3登顶App Store!Hinton高徒、多伦多华人博士领衔官宣免费后,Grok火速登顶美区App Store榜首,同时,xAI也放出官方博文,秀了一把模型的数学、代码、ASCII Art演示。最引人瞩目的两位C位华人,均来自多伦多大学,分别和Hinton、Bengio有交集。
来自主题: AI技术研报
8005 点击 2025-02-21 16:17
 搜索
搜索
官宣免费后,Grok火速登顶美区App Store榜首,同时,xAI也放出官方博文,秀了一把模型的数学、代码、ASCII Art演示。最引人瞩目的两位C位华人,均来自多伦多大学,分别和Hinton、Bengio有交集。

知名博主 Ben Thompson 在使用 Deep Research 后写的一篇 Deep Research and Knowledge Value[1],谈到了在信息搜索上带来的价值。
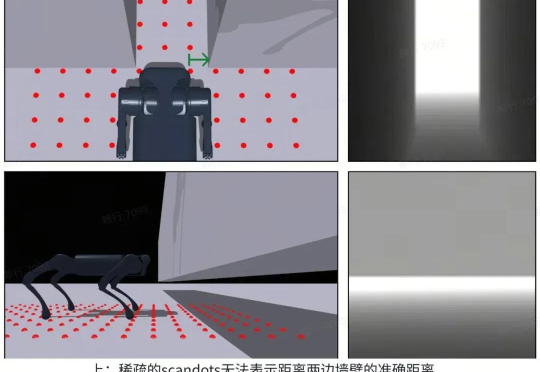
世界模型(World Model)作为近年来机器学习和强化学习的研究热点,通过建立智能体对其所处环境的一种内部表征和模拟,能够加强智能体对于世界的理解,进而更好地进行规划和决策。

近日,美国知名播客Invest Like the Best再次访谈了Andreessen Horowitz的联合创始人Marc Andreessen,在访谈中,Marc和主播Patrick深入探讨了AI正在重塑技术和地缘政治的重大变革,并讨论了DeepSeek的开源人工智能以及其大国技术竞争中的意义,此外,他们还分享了对全球权力结构演变的看法,以及风险投资行业整体的转型。
想象这样一个特别的“直播平台”,主播从来不担心冷场、没人气,因为根本没有真人观众,而是 AI 充当气氛组,他们始终热烈回应主播的一举一动、一言一行,只要开播,即刻能过一把当网红的瘾。你可能还在疑问到底谁是这个奇怪产品的受众,「Parallel Live」则已经能用不俗的营收表现回应一切。上个月,其幕后开发者 Ethan Keiser 通过推特宣布,该产品赚了超过百万美元。
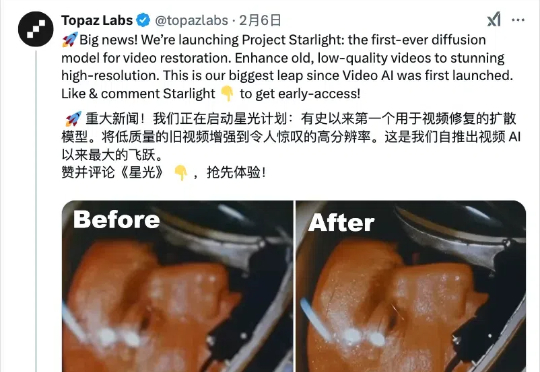
经常有群友问我有没有什么把视频修复的工具。而我过去最推荐的,也是我心中目前最牛逼的视频修复工具,自然就是TopazVideoAI了。但,斗转星移,日月如梭,现在已经2025年了。我们在进化,而Topaz他们家,自然也再进化,前两天他们家又整了个新活,搞了个叫Starlight的新东西。

在今年1月《Journal of Supercomputing》上开源的「开源类脑芯片」二代(Polaris 23)完整版本源代码,基于RISC-V架构,支持脉冲神经网络(SNN)和反向传播STDP。该芯片通过并行架构显著提升神经元和突触处理能力,带宽和能效大幅提升,MNIST数据集准确率达91%。
最初,查询扩展是为那些靠关键词匹配来判断相关性的搜索系统设计的,比如 tf-idf 或其他稀疏向量方案。这类方法有些天然的缺陷:词语稍微变个形式,像 "ran" 和 "running",或者 "optimise" 和 "optimize",都会影响匹配结果。虽然可以用语言预处理来解决一部分问题,但远远不够。技术术语、同义词和相关词就更难处理了。
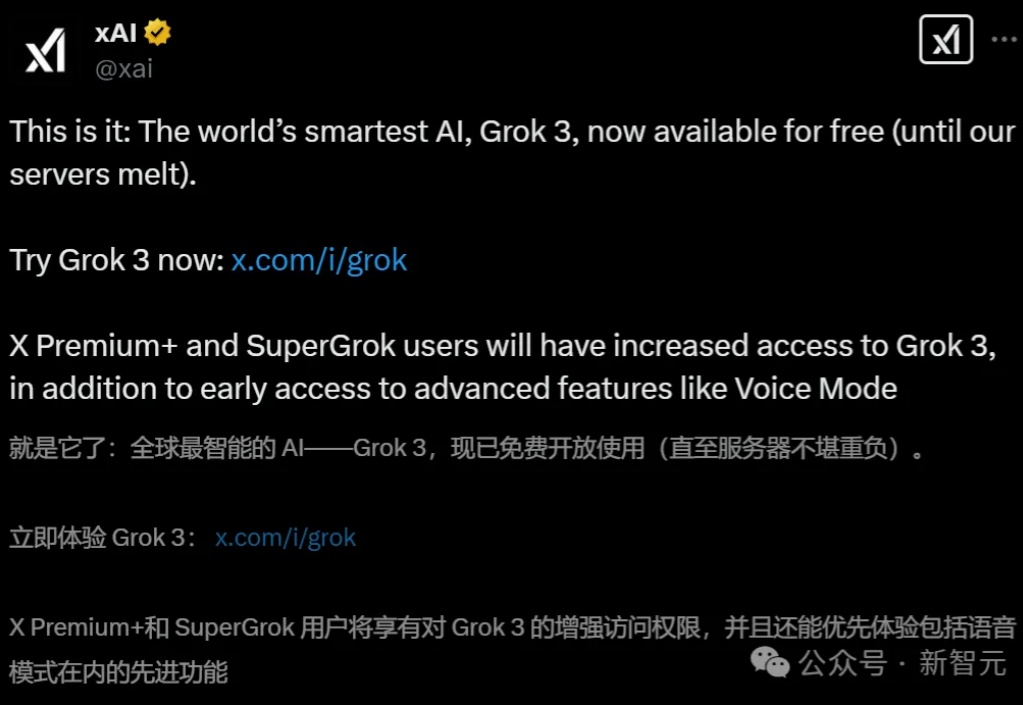
刚刚Grok-3免费开放了!DeepSearch和Think两大模式加持,刚上了热搜的「9.11和9.9哪个大」终于能做对了(但没全对),甚至1分钟秒解MIT积分赛题。然而,它刚一亮相就遭OpenAI研究员「打假」,被对方质疑作弊。

零一万物AI视频混剪项目负责人蓝雨川,新项目SparkView方向为AI视频剪辑工具。对上述信息,零一万物回复《智能涌现》:零一万物去年有一个多亿的收入,今年会有快速增长。零一万物不仅在不断上线更多的应用发掘价值,这个过程中,零一万物也会根据市场PMF对项目进行快速调整,包括加强投资部分业务、鼓励有商业化潜力的项目进行独立融资,也包括关停部分项目。