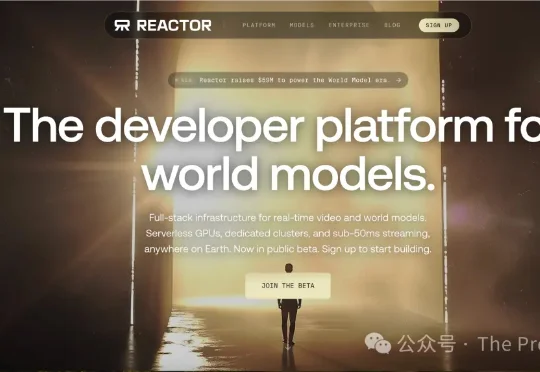
前沿|光速创投领投5900万美元,Reactor剑指世界模型基础设施,做实时AI世界的“AWS”
前沿|光速创投领投5900万美元,Reactor剑指世界模型基础设施,做实时AI世界的“AWS”核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo
来自主题: AI资讯
10039 点击 2026-06-01 10:44
 搜索
搜索
核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。
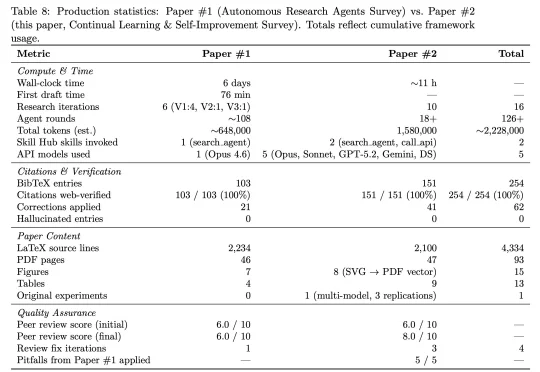
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。
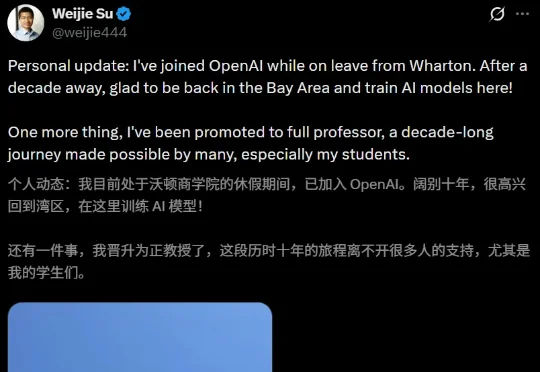
继清华姚班陈立杰之后,OpenAI又迎来一位重量级华人学者:北大数院「黄金二代」苏炜杰。今年,他刚刚摘下有「统计学诺奖」之称的COPSS Presidents' Award。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。
SophiaPro 成立于 2025 年 6 月。 最早,他们做的是一款叫 Karis.im 的 ToB 产品,给出海企业提供市场营销数字员工。后来转向 C 端产品,先是做了浏览器插件 TryClico,最近又推出了桌面端产品 Invoko.ai,一个长在 Mac 灵动岛位置的 notch 工具,帮用户在不同 app 之间自由切换上下文。
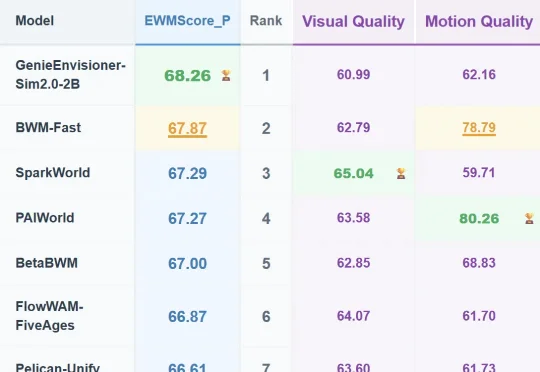
WorldArena 世界模型赛道从来都是竞争异常激烈,在经历了前几次比赛过程中的放榜之后,CVPR 2026 WorldArena 世界模型赛道锁定总成绩,智元自研的世界模型 Genie Envisioner-Sim 2.0(以下简称 GE 2.0)拿下了最终的冠军,成为了 “强者中的强者”。

过去一年,AI 出海应用,集中爆发:Gartner 预测 2026 年全球 AI 相关支出将达到 2.53 万亿美元,预计比去年增长 44%。IDC 预测未来五年的复合增速是 31.9%,届时全球 AI IT 投资将突破万亿美元大关。
编辑|Panda 数学正在迎来 AI 革命。 最近几个月尤为明显。比如,就在前几天,Google DeepMind 新论文宣布其最新系统 AlphaProof Nexus 在一次自主运行中,解决了 3