让机器人动作流畅丝滑如「连音」,千寻智能高阳团队提出Legato,入选RSS 2026
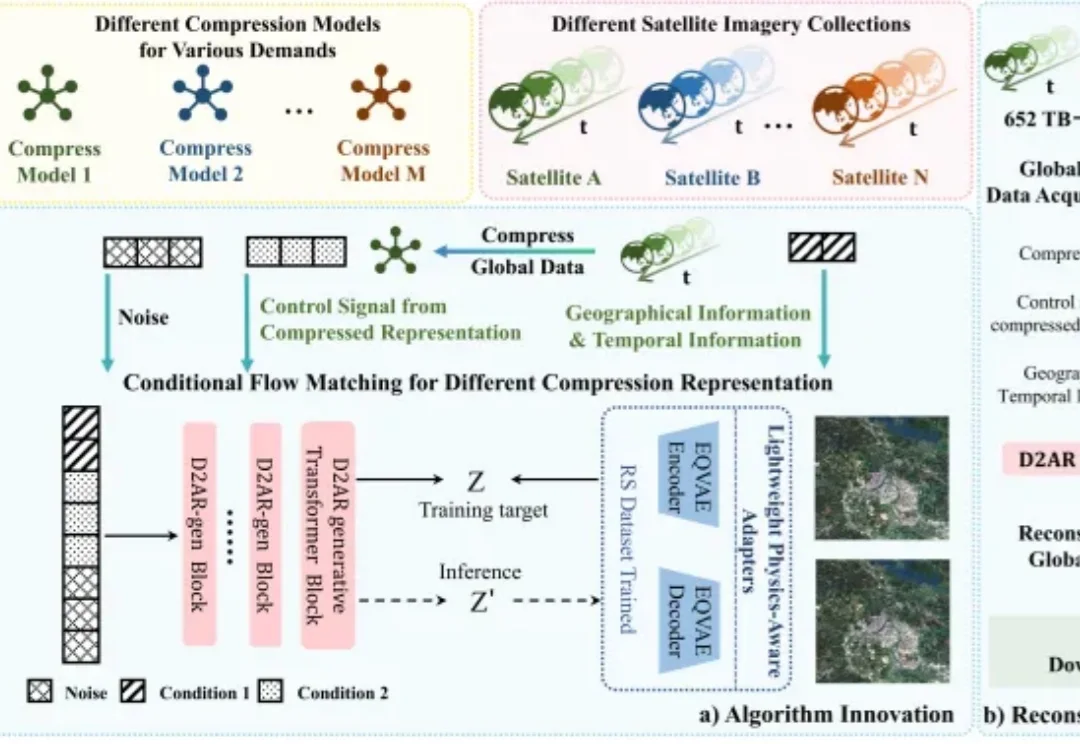
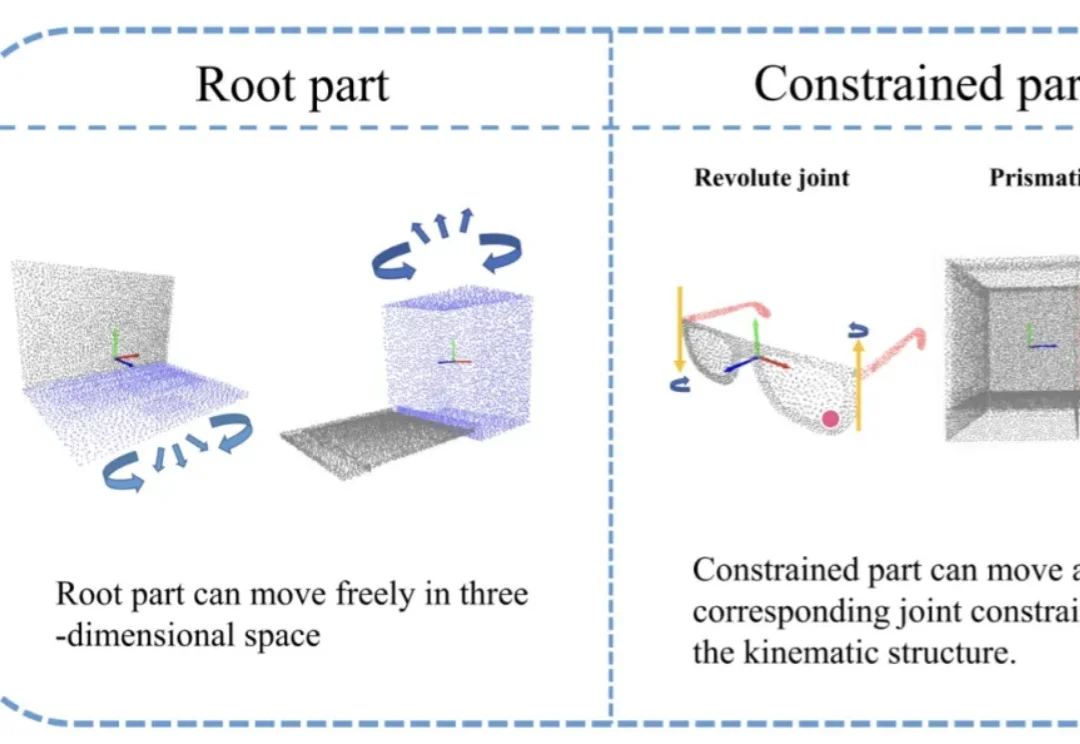
让机器人动作流畅丝滑如「连音」,千寻智能高阳团队提出Legato,入选RSS 2026近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。
来自主题: AI技术研报
8025 点击 2026-05-29 15:10