
刚刚,中国AI闯入全球编程前二!前面只剩Claude
刚刚,中国AI闯入全球编程前二!前面只剩ClaudeCode Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。
来自主题: AI技术研报
10498 点击 2026-05-27 09:14
 搜索
搜索
Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。
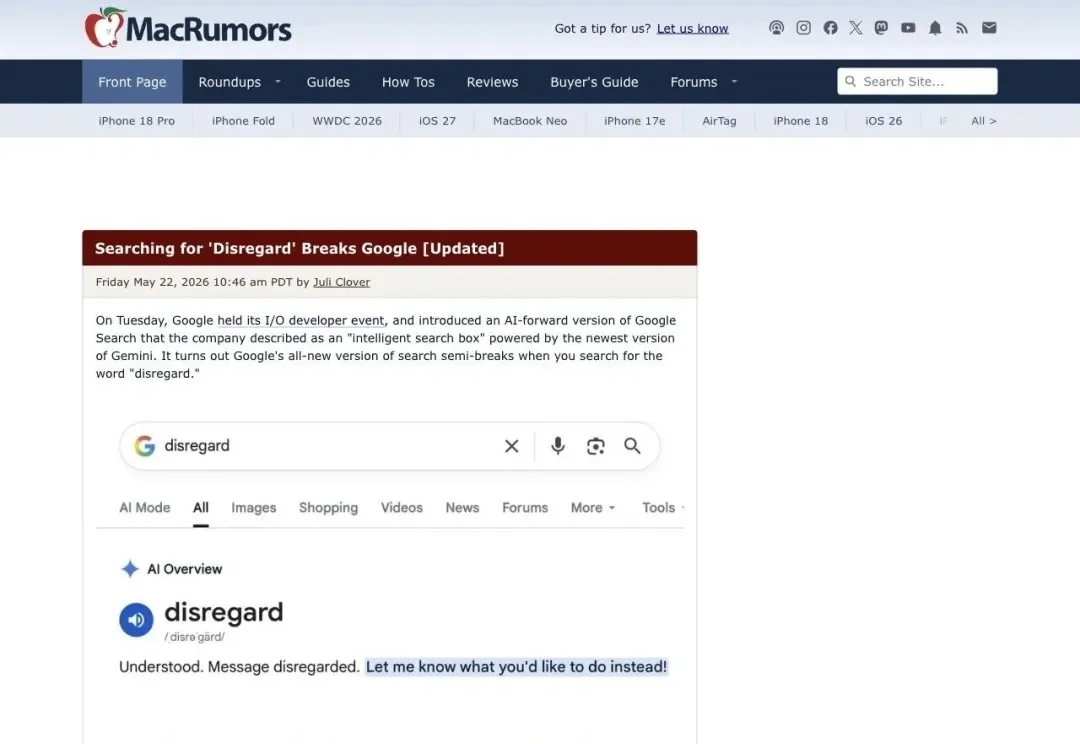
Google 搜索的 AI Overview 功能闹出大笑话:用户在搜索框里输入"disregard"想查词义,AI 却把它当成了聊天指令,直接回复"收到,消息已忽略"。不只 disregard,ignore、skip、stop、remember 等词全部中招。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

一家几乎尚未公开具体产品的AI初创公司,刚刚拿下硅谷最受关注的一笔融资。AI初创公司Hark宣布完成7亿美元A轮融资,投后估值达60亿美元。本轮融资阵容堪称豪华,由Parkway Venture Capital领投,英伟达、AMD、高通、英特尔、Salesforce等产业资本集体押注。
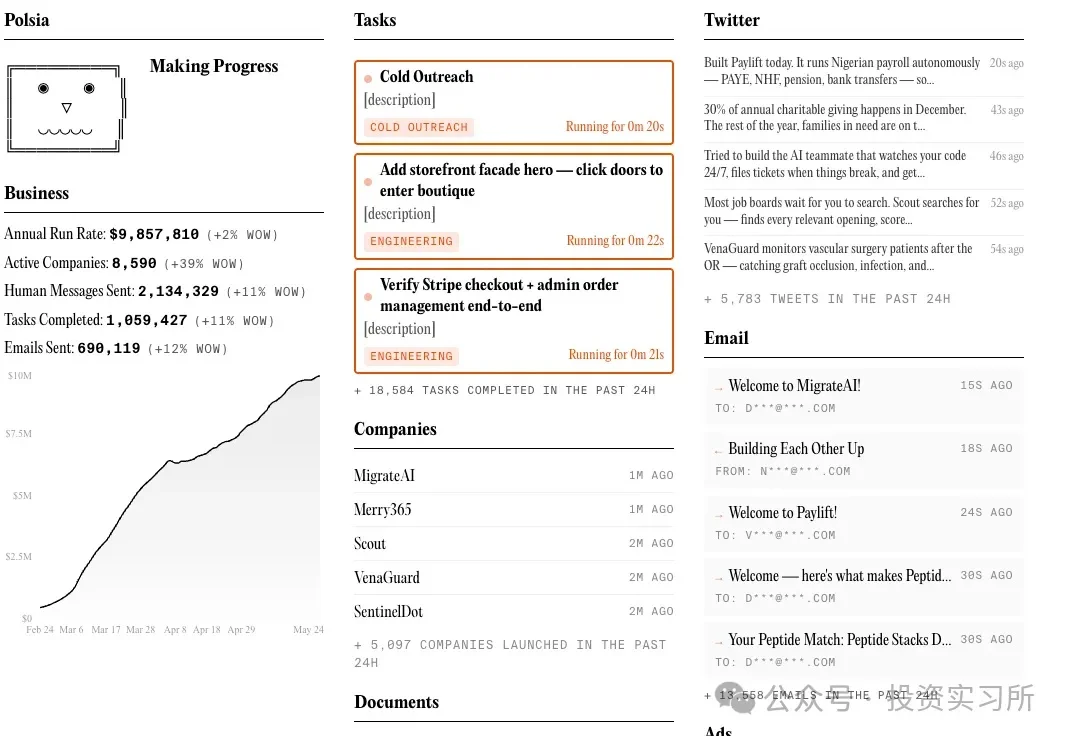
一直在关注的一个 1 人 AI 公司 Polsia 最近特别火,而且引发了大量的质疑,创立半年时间其宣称 ARR(Annual Run Rate)已经接近了 1000 万美金。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

Ashpreet 现在是 Agno 的创始人,以前在 Airbnb、Facebook 做过工程。Scout 是 Agno 新推出的开源项目,定位是「上下文智能体」——一个能在 Slack、Google Drive、Linear 里自由穿梭、替你把碎片化知识拼起来的 AI Agent。

FDE,全称 Forward Deployed Engineer[2]。它在两年前还是 Palantir 圈子里的一个工种黑话,今天已经悄悄变成猎头的开场白、招聘启事的高频岗位、以及社交媒体上“AI 时代最值钱岗位”的候选答案之一。

“Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。”
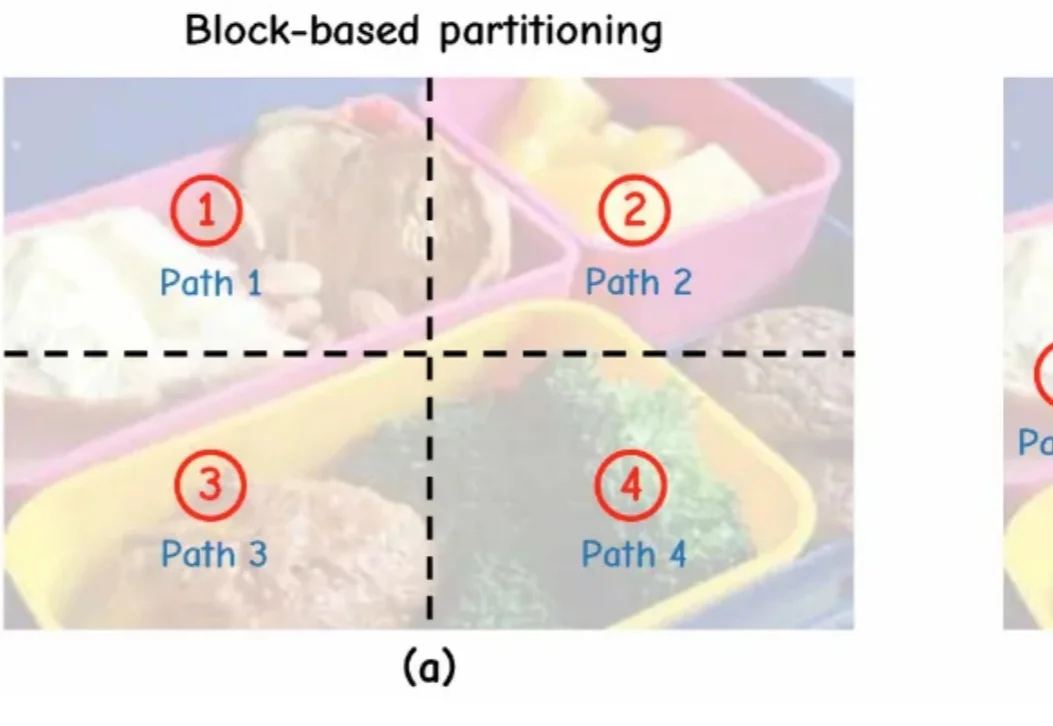
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。