
刚刚,全球首个加密AI产品完成保险签约!你敢用,它敢赔
刚刚,全球首个加密AI产品完成保险签约!你敢用,它敢赔保险、AI、资本、媒体——四个圈子的人同时出现在一个签约仪式上,只因为一件从没人干过的事:给用户上传给AI的数据上保险。荆华密算与人保北京市分公司、AI原点社区,签下了北京市首单、也是保险行业首个AI企业数据损害赔偿责任保险。
来自主题: AI资讯
8904 点击 2026-07-08 09:47
 搜索
搜索
保险、AI、资本、媒体——四个圈子的人同时出现在一个签约仪式上,只因为一件从没人干过的事:给用户上传给AI的数据上保险。荆华密算与人保北京市分公司、AI原点社区,签下了北京市首单、也是保险行业首个AI企业数据损害赔偿责任保险。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。
针对这一问题,openJiuwen社区正式发布Skill-Omni——业界最早工程化落地的多模态Skill范式。 它让Agent的经验从“读得懂”升级为“看得见”,把网页和视频中的视觉知识,沉淀为Agent可复用的多模态Skill。

袁语2016年清明节后在九合创投拿到第一份投资工作,跟着王啸干,投的第一个项目就是VUE——一个帮普通人拍出好视频的创作工具。他说自己一直对"像钢琴一样的东西"着迷,那种能激发创造力的工具。
7月7日,Fable 5没下线!就在凌晨,Anthropic突然官宣, 最强Claude Fable 5限时免费,延长到了7月12日。比原计划,又多了足足五天的「白嫖」时间。具体用法,和之前一模一样,每周使用限额50%,超出之后想继续用,就得买credits了。
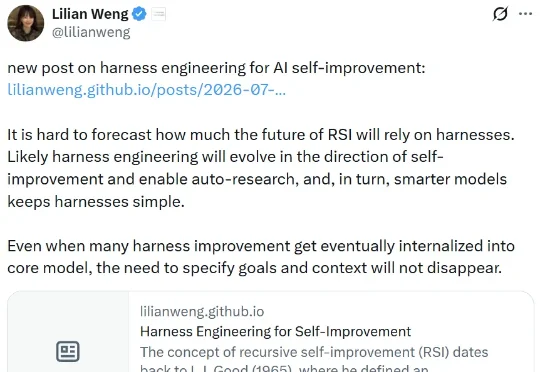
刚刚,翁荔(Lilian Weng)又更新博客了!距离她上一次更新《谨慎对待 Scaling Law》还不到 10 天。这一次,她书写的主题是当前大热的 Harness Engineering,聚焦的正是当下 AI 研究最前沿一个环节:当模型本身的智能已经足够强大时,真正决定它能走多远的,或许是包裹在模型外面的那层「Harness」也就是负责编排模型思考、调用工具、管理上下文、评估结果的那套系统。

今天,据路透社报道,三位知情人士透露,DeepSeek正在自研AI推理芯片,以减少对英伟达以及华为芯片的依赖。知情人士称,DeepSeek自研芯片的工作大约在一年前启动,其研发仍处于早期阶段。目前,DeepSeek正在接触外部合作伙伴,并与芯片设计企业、晶圆代工厂以及存储企业展开讨论。

近日,北京月之暗面科技有限公司发生工商变更,联合创始人汪箴退出股东序列。公开工商信息显示,退出前,汪箴持有公司约0.075%的股份。原因并不在于股份,而在于身份。公开资料显示,汪箴不仅是月之暗面的联合创始人,也是公司现任总裁张予彤的丈夫。
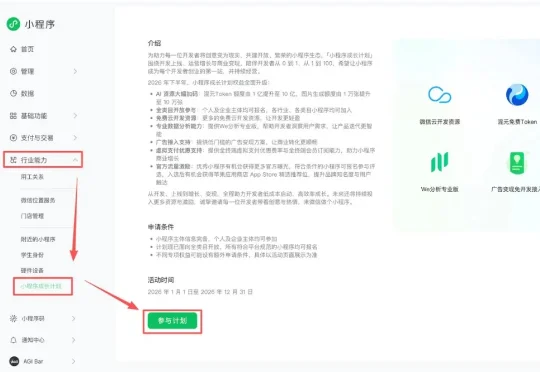
昨天,腾讯混元 Hy3 正式版上线,小程序更新了「成长计划」:小程序开发者的可以获得 10 亿的文本 Token,和 10 万张生图额度→ 10 亿 token 按官方 API 价折算,约 1000~4000 块

今天,Synthetic Sciences直接发布一款OpenScience的开源替代项目。团队表示,Open Science比 Claude Science 更好用,且完全开源。Open Science支持30个可用的数据库,超250个研究skills。这些数据和技能,让Open Science具备实验假设、消融实验、结果溯源、论文撰写等全套科研能力。