
更美图像生成、直出分钟级视频,国产自研DiT架构的越级之旅
更美图像生成、直出分钟级视频,国产自研DiT架构的越级之旅一转眼,2024 年已经过半。我们不难发现,AI 尤其是 AIGC 领域出现一个越来越明显的趋势:文生图赛道进入到了稳步推进、加速商业落地的阶段,但同时仅生成静态图像已经无法满足人们对生成式 AI 能力的期待,对动态视频的创作需求前所未有的高涨。
来自主题: AI资讯
11137 点击 2024-07-06 18:56
 搜索
搜索
一转眼,2024 年已经过半。我们不难发现,AI 尤其是 AIGC 领域出现一个越来越明显的趋势:文生图赛道进入到了稳步推进、加速商业落地的阶段,但同时仅生成静态图像已经无法满足人们对生成式 AI 能力的期待,对动态视频的创作需求前所未有的高涨。

该文章的作者团队来自于斯坦福大学,共同第一作者团队Mert Yuksekgonul,Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang

只要把推理和感知能力拆分,2B大模型就能战胜20B?!
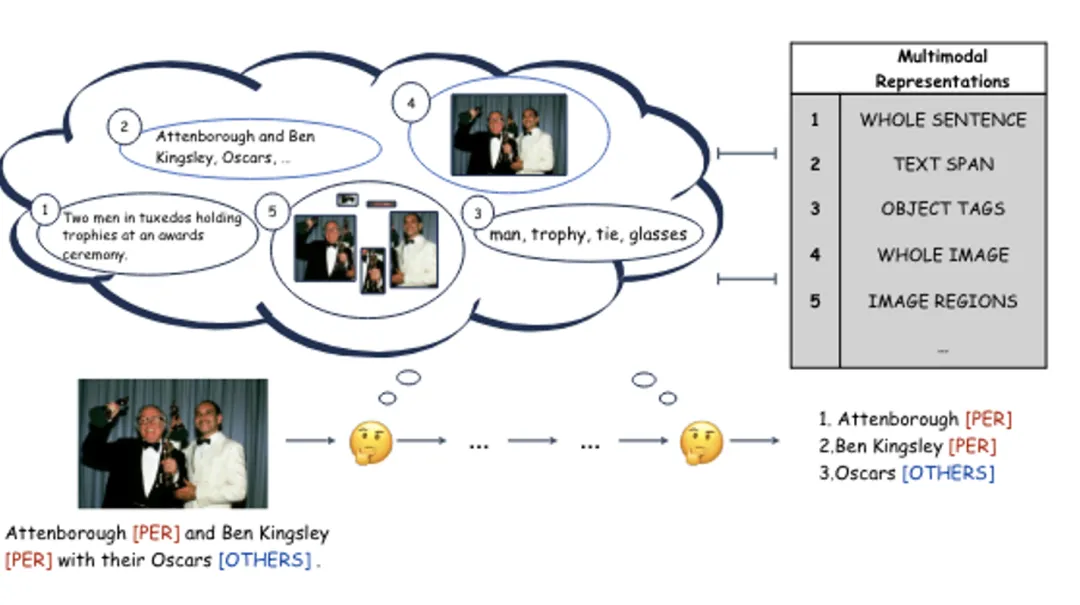
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。

只要将注意力切块,就能让大模型解码提速20倍。

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。
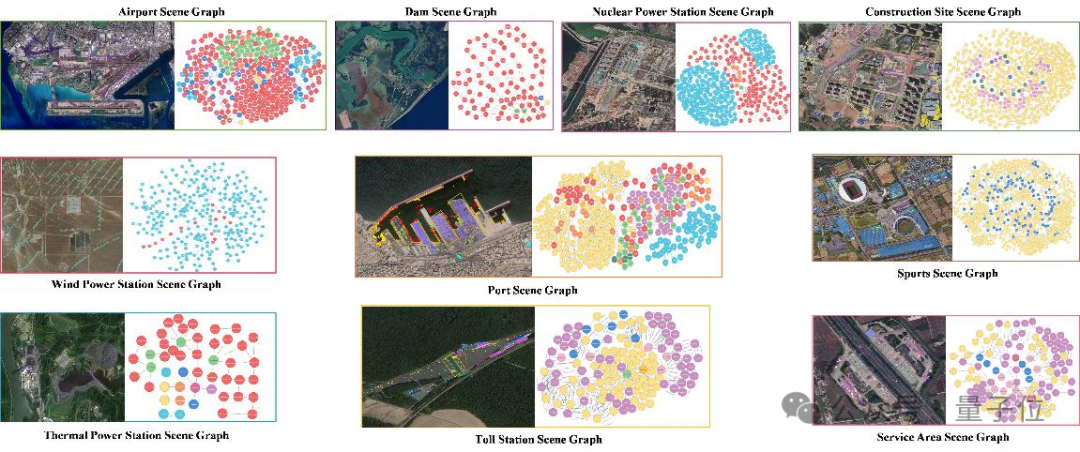
AI卫星影像知识生成模型数据集稀缺的问题,又有新解了。
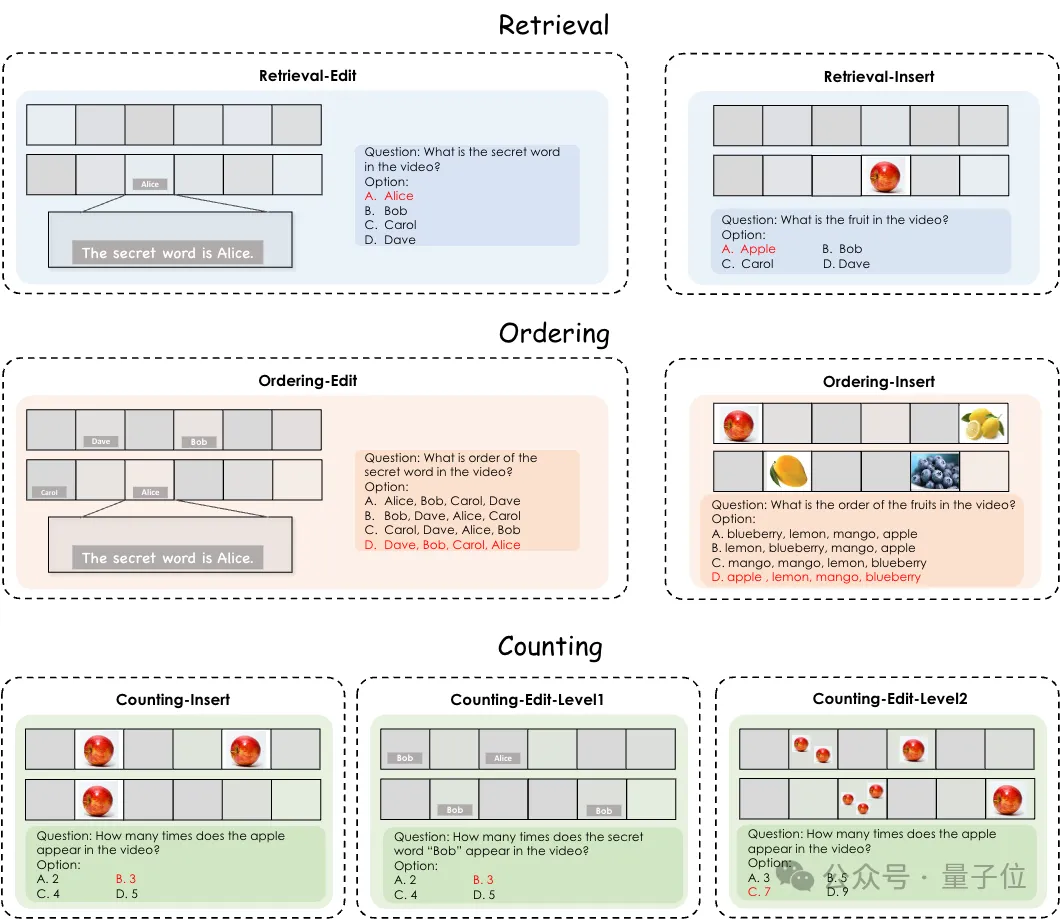
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。

360 度场景生成是计算机视觉的重要任务,主流方法主要可分为两类,一类利用图像扩散模型分别生成 360 度场景的多个视角。由于图像扩散模型缺乏场景全局结构的先验知识,这类方法无法有效生成多样的 360 度视角,导致场景内主要的目标被多次重复生成,如图 1 的床和雕塑。

24点游戏、几何图形、一步将死问题,这些推理密集型任务,难倒了一片大模型,怎么破?北大、UC伯克利、斯坦福研究者最近提出了一种全新的BoT方法,用思维模板大幅增强了推理性能。而Llama3-8B在BoT的加持下,竟多次超越Llama3-70B!