# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。
直接在视频内容中插入多个无关的图像或文本“针”,严格评估模型对时间理解的能力。
来看下面的栗子。
比如插入密码词“Alice”,让模型找到这个密码词;插入苹果图片,让模型解答这个水果是什么;又或者插入多个“针”,询问模型插入针的顺序是什么。
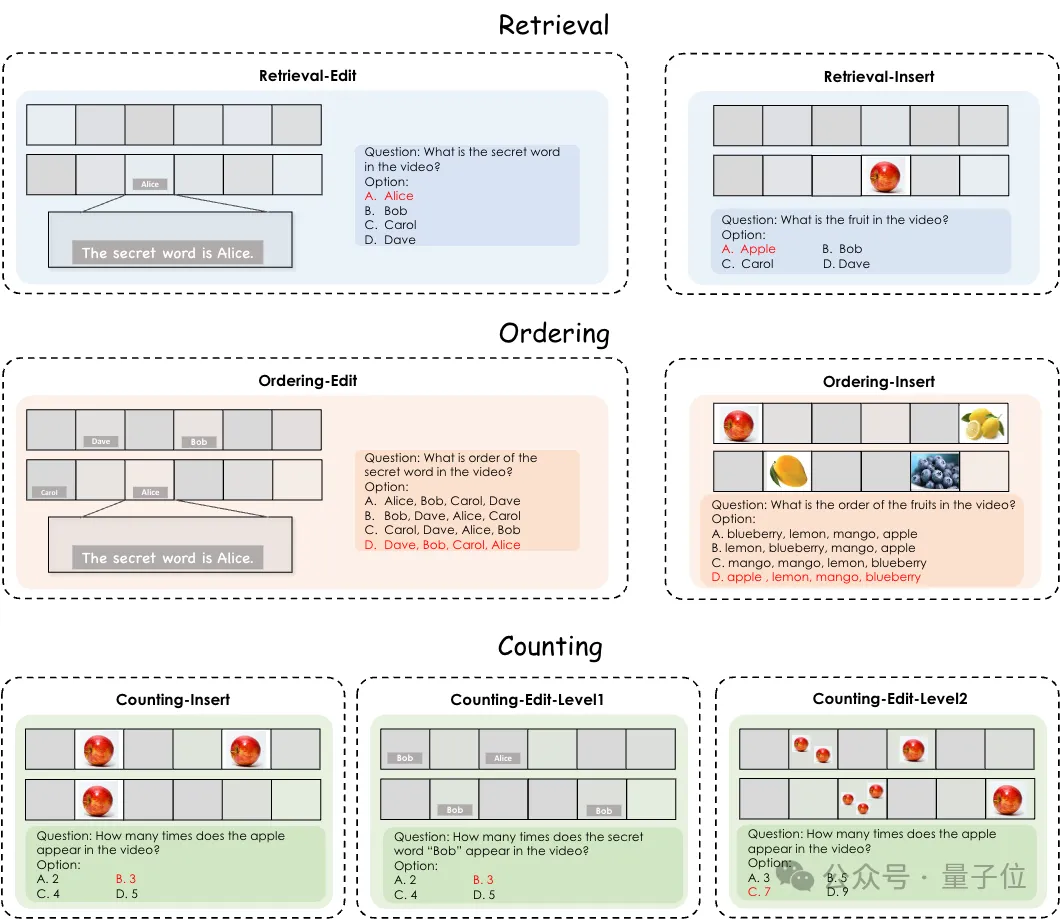
这就是来自中科院、人大、百川的研究团队联合提出的利用合成视频构建视频理解测试基准的方法。
该方法名为VideoNIAH,可以解耦视频内容与其对应的查询-响应对,通过插入无关的图像或文本“针”来生成测试数据,既保证了视频来源的多样性和查询响应的多样性,还通过插入多个针来严格评估模型对时间理解的能力。
此外,使用与现实视频内容相对应的查询-响应对可能存在数据泄露风险,影响基准测试的公平性,使用合成视频生成方法可以有效避免这一问题。
研究团队利用VideoNIAH方法制作了一个能够有效评估视频模型的细粒度理解能力和时空建模能力,同时支持长上下文评估的合成视频理解基准VNBench,包含1350个样本。
随后对Gemini1.5 Pro、GPT-4o、GPT-4-turbo以及其它开源模型进行了测试,并分析了一系列结果。
研究团队发现,即使是GPT-4o等最先进的专有模型,在需要检测和追踪视频中特定空间区域内的“针”等计数任务上的表现也不理想;在排序任务上,专有模型与开源模型之间的性能差距尤为显著……

VNBench更多细节以及更多实验结果我们接着往下看。
随着视频中心的MLLMs模型的提出,需要有更全面的基准测试来评估这些模型在视频理解方面的能力,包括细粒度理解、时空建模以及长上下文处理等。
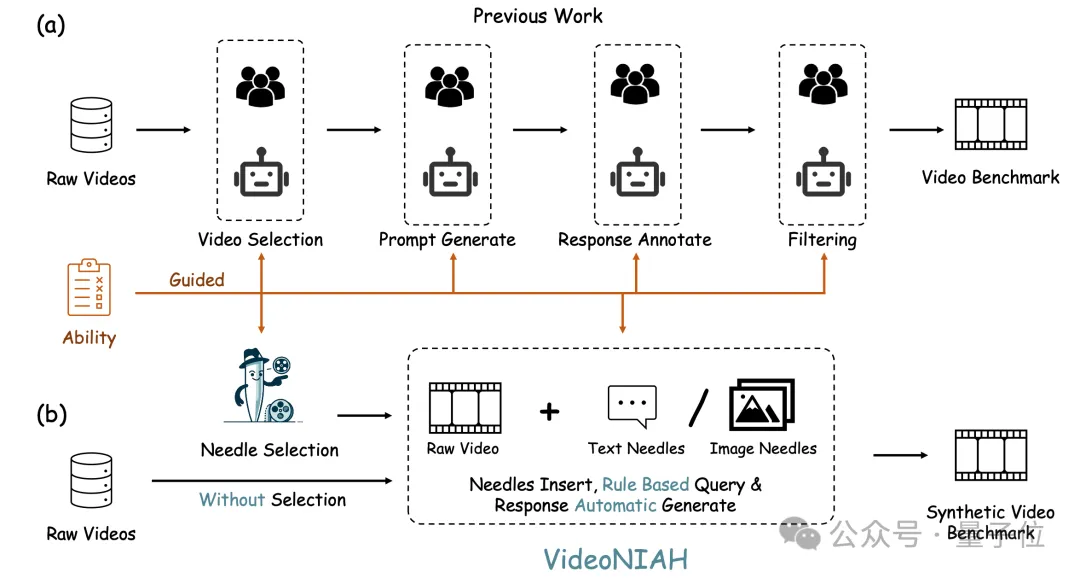
传统的视频基准测试通常需要基于目标能力精心选择视频,并进行繁琐的查询-响应对标注,以匹配特定视频内容。这个过程不仅挑战重重,而且资源消耗巨大。
为了开发和评估视频理解模型,需要一个既能够扩展到不同视频源和长度,又能够高效运行的基准测试框架。
研究团队提出了VideoNIAH。
如前文所述,VideoNIAH(Video Needle In A Haystack)创新性地将测试视频内容与其查询-响应对解耦,通过在原始视频中插入无关的图像/文本“针”(needles),并仅从这些针生成注释。
这种方法不仅确保了视频来源的多样性和查询响应的多样性,还通过插入多个针来严格评估模型对时间理解的能力。
利用VideoNIAH,研究者们构建了一个全面的视频基准测试VNBench,包括检索、排序和计数等任务。VNBench能够有效评估视频模型的细粒度理解能力和时空建模能力,同时支持长上下文评估。
VNBench的特点主要表现在以下三个方面:
“针”类型(Needle Type)的多样性
视频”干草堆”(Video Haystack)的多样性
查询(Query)的多样性
通过这些设计,VNBench能够全面地评估视频理解模型在多样化的视频内容和查询条件下的性能,为视频理解技术的研究提供了一个有力的基准测试工具。
在论文中,通过VNBench对视频理解多模态大语言模型(MLLMs)进行了一系列评估,分析结果揭示了以下几个关键点:
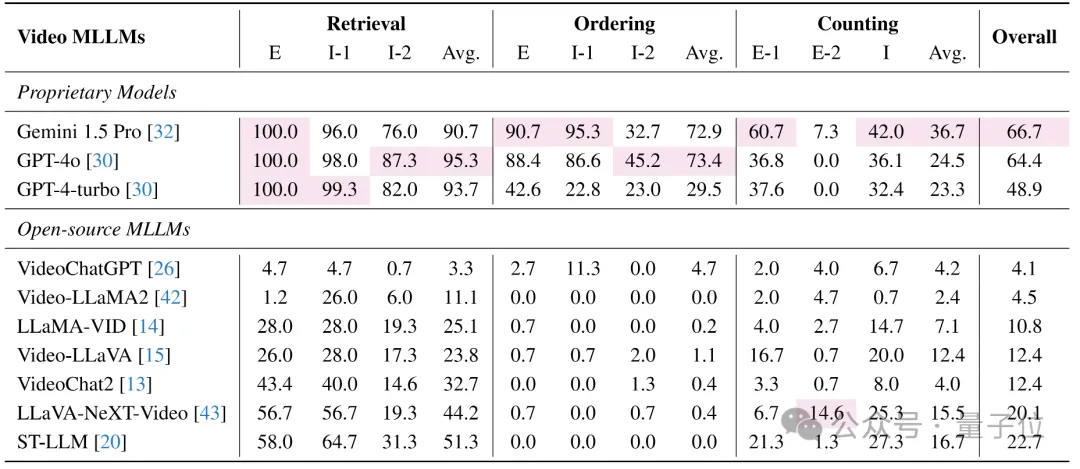
首先是专有模型与开源模型的性能差异。
专有模型(如Gemini 1.5 Pro和GPT-4系列)在大多数VNBench任务上的表现优于开源模型。这表明专有模型可能拥有更优越的视频理解能力,这可能归功于更大的模型参数和更全面的训练过程。
其次是任务难度与模型表现。
模型在单针短依赖任务(检索任务)上的表现普遍优于多针长依赖任务(排序和计数任务)。这表明当前的视频模型在处理需要长期依赖信息的任务时仍然面临挑战。
排序任务的性能差距方面,在排序任务上,专有模型与开源模型之间的性能差距尤为显著。大多数开源模型在排序任务上几乎无法完成任务,这可能是由于它们在训练过程中忽视了时间序列建模的能力。
然后是计数任务的困难。即使是最先进的专有模型,在计数任务上的表现也不理想。特别是在需要检测和追踪视频中特定空间区域内的“针”时(Counting-E-2任务),所有模型的表现都很差,这表明当前的视频模型在理解和建模视频中的细粒度时空关系方面仍有不足。
此外,视频上下文长度的影响方面,随着视频处理时长的增加,开源模型的性能显著下降,而专有模型由于具有更长的上下文处理窗口,性能波动不大。这表明当前模型在处理长视频内容时的能力有限。
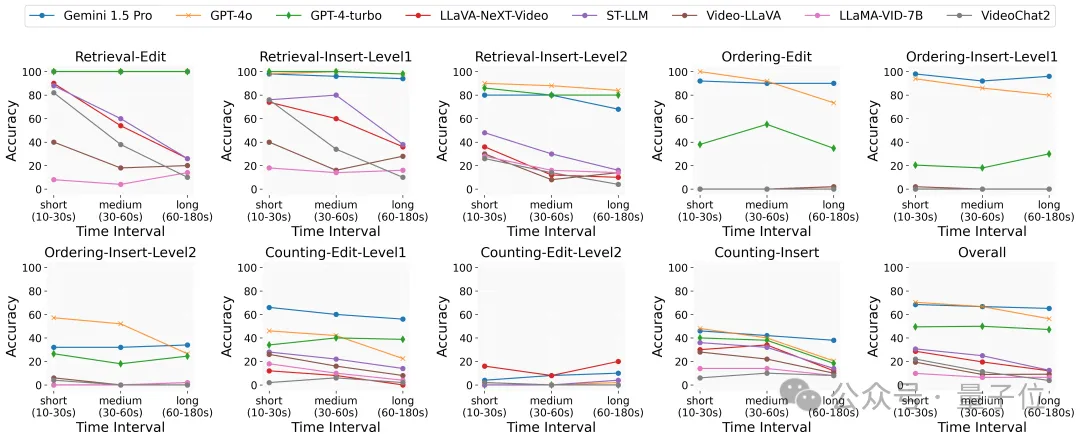
“针”位置的影响方面,通过改变“针”在视频中的位置,研究发现专有模型由于其较长的上下文窗口,能够准确回忆所有插入的信息,而开源模型则表现出在长序列中对中间信息的回忆不足。
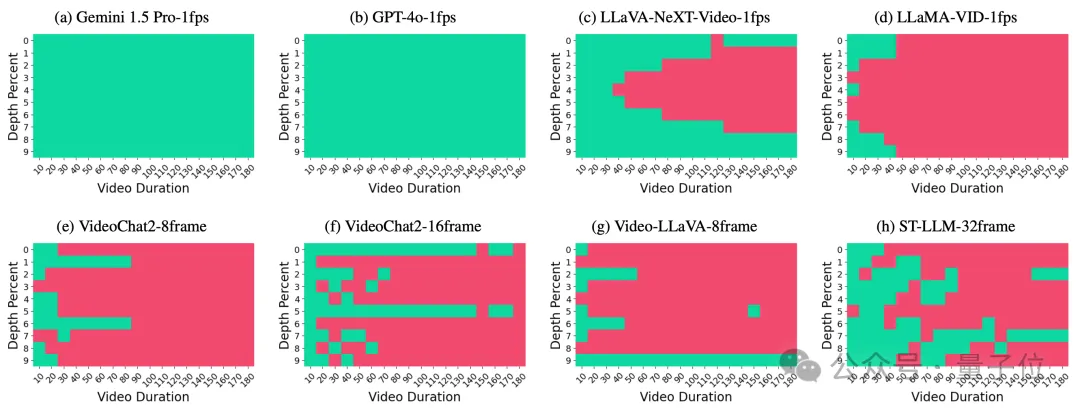
这些分析结果不仅揭示了当前视频理解模型的优势和局限性,而且为未来的研究提供了宝贵的见解,有助于指导视频理解技术的发展和改进。
论文链接:https://arxiv.org/abs/2406.09367
项目链接:https://videoniah.github.io/
文章来源于:微信公众号量子位



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
