
黄仁勋力挺中国开源模型,马斯克:True
黄仁勋力挺中国开源模型,马斯克:True最近硅谷有点魔幻。一边被中国开源模型吓得不轻,专门造了个词叫「Kimi panic」;另一边,美国最大的模型托管平台刚被自家模型攻击,救场的偏偏又是一个中国开源模型。就在这个节骨眼上,老黄又整活了。
来自主题: AI资讯
8079 点击 2026-07-23 09:48
 搜索
搜索
最近硅谷有点魔幻。一边被中国开源模型吓得不轻,专门造了个词叫「Kimi panic」;另一边,美国最大的模型托管平台刚被自家模型攻击,救场的偏偏又是一个中国开源模型。就在这个节骨眼上,老黄又整活了。
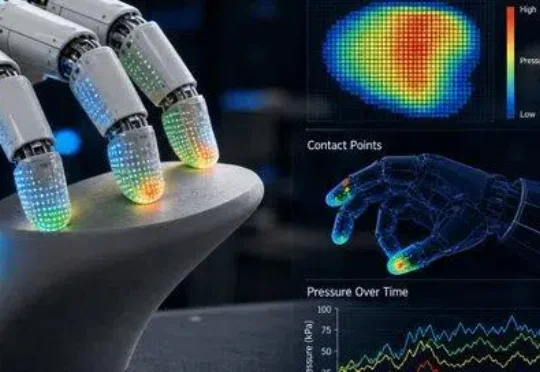
瞄准这类 “看起来做对了,物理上却没完成” 的失败。破晓智能(PHANES AI)创始人、哈工大(深圳)长聘教授杨朔及其团队发布了最新论文 TouchWorld: A Predictive and Reactive Tactile Foundation Model for Dexterous Manipulation。
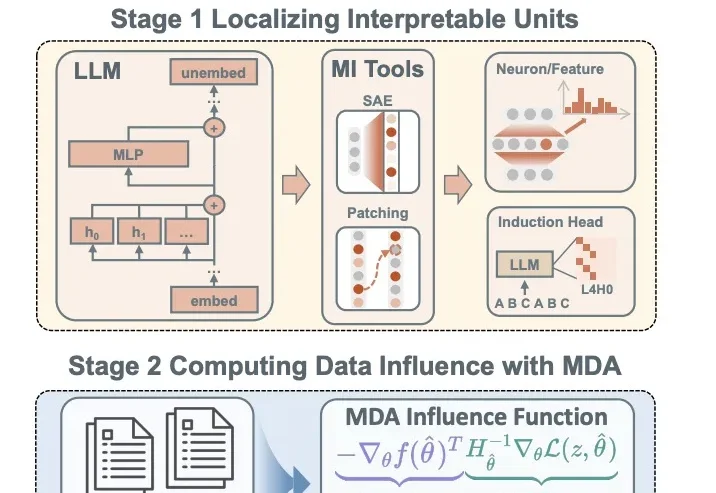
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

近日,皮特·弗洛伦斯创办的具身智能公司Generalist AI完成了一轮新融资,总规模为4亿美元(约合人民币27亿元),估值为20亿美元(约合人民币135.5亿元)。本轮投资方包括英伟达旗下的NVentures、知名天使投资人纳特·弗里德曼(Nat Friedman)和丹尼尔·格罗斯(Daniel Gross)共同管理的NFDG

Waniwani宣布完成了800万美元的种子轮融资,由Seedcamp领投,Redstone、Zone II Ventures、Plug & Play、OPRTRs Club、Kima Ventures以及一批知名天使投资人跟投。
今天,流形空间宣布完成新一轮数亿元融资。本轮投资方包括中国国新旗下国新基金,淡马锡旗下毅峰资本,产业资本北汽产投、芯能创投等。流形空间成立于2025年5月,一年以来已经累计完成6轮融资,Pre-A轮累计近10亿元,

从v0.7开始,我先给 Humanize PPT 划了一条边界。把渲染PPT页面外包给下游的Skill。Humanize PPT负责把大纲,逐页意图,视频和图片素材的坑位和演讲稿,整理成结构化的 JSON 与 Markdown,再交给下游 Skill 原生渲染。

这家专注数字人和AIGC视频生成技术的公司,刚刚迎来一次关键资本加码——旗下AI短剧协作平台AniShort完成近亿元融资,由北京泰中合领投,多家机构跟投,老股东全线加码。而这,也是2026年国内AI短剧工具类产品最大单笔融资纪录。
一直以来,各大主流AI公司都严禁用户生成颜色内容,甚至连擦边球都不允许,以防外界对于AI产生什么不好的印象。