ICLR 2026|CMU等团队让AI生成的3D场景真正「站得住」:PAT3D把文生3D从能看推进到能模拟、能交互
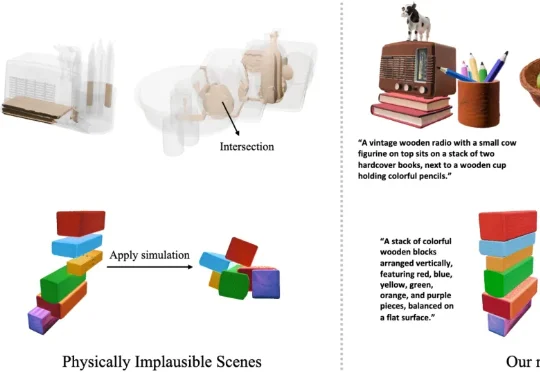
ICLR 2026|CMU等团队让AI生成的3D场景真正「站得住」:PAT3D把文生3D从能看推进到能模拟、能交互现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。
来自主题: AI技术研报
9014 点击 2026-05-02 13:35