
英伟达华人硬核AI神器,「描述一切」秒变细节狂魔!仅3B逆袭GPT-4o
英伟达华人硬核AI神器,「描述一切」秒变细节狂魔!仅3B逆袭GPT-4o视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。
来自主题: AI资讯
11724 点击 2025-04-27 10:47
 搜索
搜索
视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。

5月19-23日,ICRA 2025将在美国亚特兰大举行。届时,第一届“探索机器人能力边界双臂机器人挑战赛(WBCD,What Bimanual Can Do)”决赛也将在ICRA 2025现场拉开帷幕。

2025年4月25日,百度Create大会上,百度集团创始人、董事长兼CEO李彦宏的答案是:“你只要找对场景,选对基础模型,有时候可能还要学一点调模型的方法,那么在这个基础上做出来的应用,它是不会过时的,应用才是真正创造价值的。”
就在刚刚,在Create 2025百度AI开发者大会上,李彦宏又一口气官宣了两款新模型:分别是主打深度思考和多模态的X1 Turbo/4.5 Turbo。据介绍,它们是百度在3月发布的旗舰模型X1、4.5的升级版,推理和多模态能力双双更跃Level。

今天,微软重磅官宣:「AI同事时代」正式来临!Microsoft 365 Copilot今天又迎来一波重大更新,Researcher、Analyst等智能体强势登场。同时发布的2025工作趋势报告预言:2025将成人机混合的「前沿公司」年。

,2025年,大模型计算效率的提升并未给AI基建按下暂停键,微软、亚马逊、谷歌、Meta四大科技巨头2025年在AI技术与数据中心的资本支出将达3200亿美元(约合人民币2.33万亿元);OpenAI、软银等企业总投资5000亿美元(约合人民币3.66万亿元)的“星际之门”项目也已动工。在这波AI大基建浪潮中,提供硬件与算力服务的“卖铲人”们正赚得盆满钵满。

“关系”永远是人才管理的关键。ConverzAI专注于发展AI驱动的招聘解决方案,其推出的虚拟招聘助手(Virtual Recruiter)能够自主管理从人才搜索、互动到关系搭建全流程,并帮助企业做出数据驱动的招聘决策。据ConverzAI官网数据,客户企业可以在5天内快速搭建一个虚拟招聘助手,将招聘周期缩短90%。
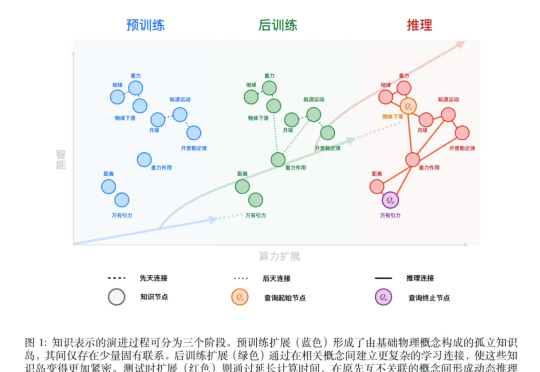
无论你是技术创造者还是使用者,理解这场认知革命都至关重要。我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。
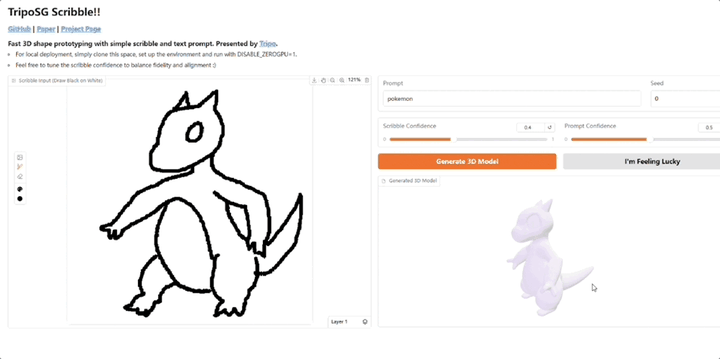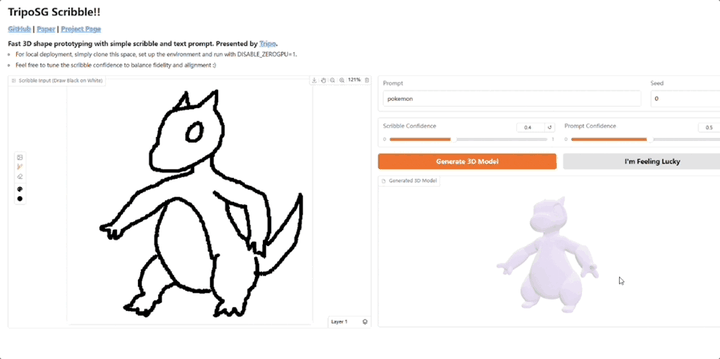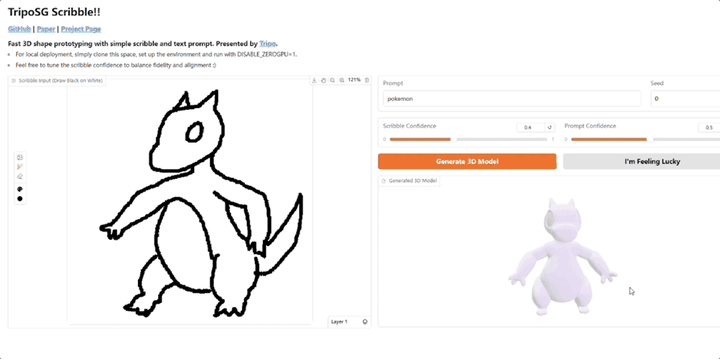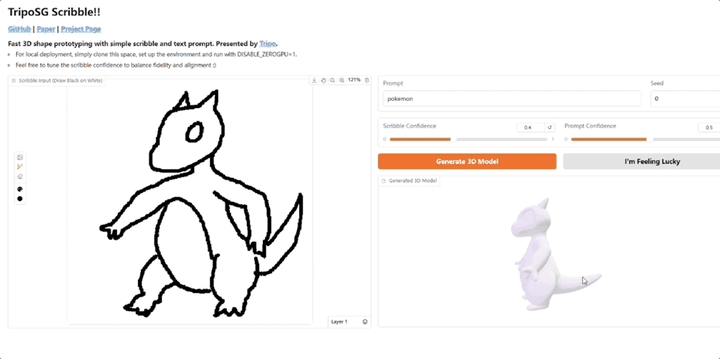
3D生成明星玩家VAST,又又又又又开源了!Tripo Doodle(内部代号TripoSG Scribble) ,能够将简单的2D草图和文本提示(Text Prompt)实时转化为精细的3D模型。它改进了传统3D建模学习曲线陡峭、耗时耗力的痛点,尤其是在初期“打形”阶段。

「真格十问」是一个快问快答栏目。我们希望用十个问题,拆解可实操的产品成长方法,力求呈现「非共识但正确」的真知灼见。