
CVPR'24 Highlight|一个框架搞定人物动作生成,精细到手部运动
CVPR'24 Highlight|一个框架搞定人物动作生成,精细到手部运动近年来,人物动作生成的研究取得了显著的进展,在众多领域,如计算机视觉、计算机图形学、机器人技术以及人机交互等方面获得广泛的关注。然而,现有工作大多只关注动作本身,以场景和动作类别同时作为约束条件的研究依然处于起步阶段。
来自主题: AI技术研报
10488 点击 2024-07-11 20:31
 搜索
搜索
近年来,人物动作生成的研究取得了显著的进展,在众多领域,如计算机视觉、计算机图形学、机器人技术以及人机交互等方面获得广泛的关注。然而,现有工作大多只关注动作本身,以场景和动作类别同时作为约束条件的研究依然处于起步阶段。

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力

文生图也有自己的prompt优化工具了。

本文将为大家介绍CVPR 2024 Highlight的论文LangSplat: 3D Language Gaussian Splatting(三维语义高斯泼溅)。LangSplat在开放文本目标定位和语义分割任务上达到SOTA性能。在1440×1080分辨率的图像上,查询速度比之前的SOTA方法LERF快了199倍。代码已开源。

入选CVPR 2024 Highlight的三维语义高斯泼溅最新成果,查询速度比之前的SOTA方法LERF快了199倍!

3D场景理解让人形机器人「看得见」周身场景,使汽车自动驾驶功能能够实时感知行驶过程中可能出现的情形,从而做出更加智能化的行为和反应。而这一切需要大量3D场景的详细标注,从而急剧提升时间成本和资源投入。
按部就班 vs. 好奇心驱动,哪个更容易出研究成果?
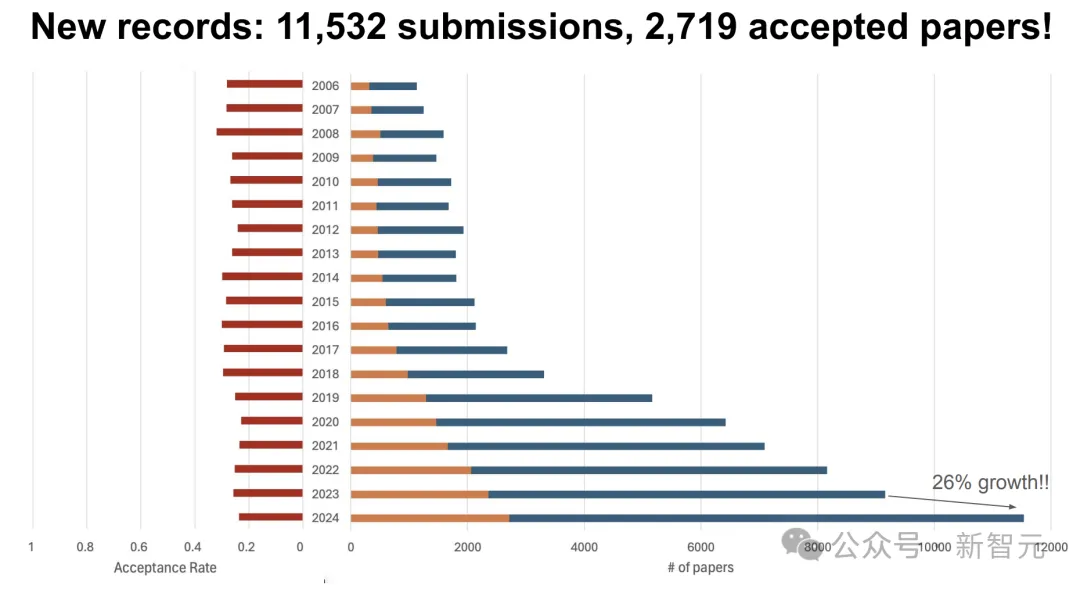
一年一度CVPR最佳论文放榜了!刚刚结束开幕演讲上,公布了2篇最佳论文、2篇最佳学生论文、荣誉提名等奖项。值得一提的是,今年北大上交摘得最佳论文提名桂冠,上科大夺得最佳学生论文。

为了实现高精度的区域级多模态理解,本文提出了一种动态分辨率方案来模拟人类视觉认知系统。

拯救4bit扩散模型精度,仅需时间特征维护——以超低精度量化技术重塑图像内容生成!