CVPR论文一网打尽!科研神器Papers with Code满血复活
CVPR论文一网打尽!科研神器Papers with Code满血复活科研神器Papers with Code,满血复活!
来自主题: AI资讯
10374 点击 2026-06-03 15:27
 搜索
搜索
科研神器Papers with Code,满血复活!
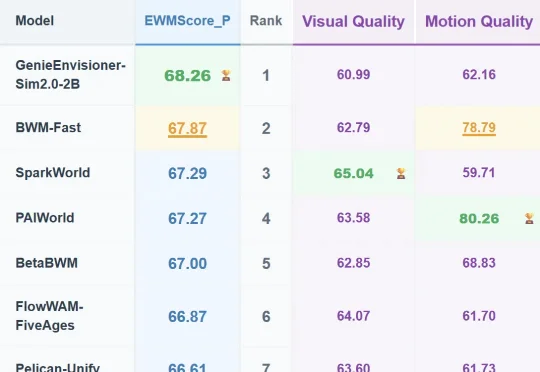
WorldArena 世界模型赛道从来都是竞争异常激烈,在经历了前几次比赛过程中的放榜之后,CVPR 2026 WorldArena 世界模型赛道锁定总成绩,智元自研的世界模型 Genie Envisioner-Sim 2.0(以下简称 GE 2.0)拿下了最终的冠军,成为了 “强者中的强者”。
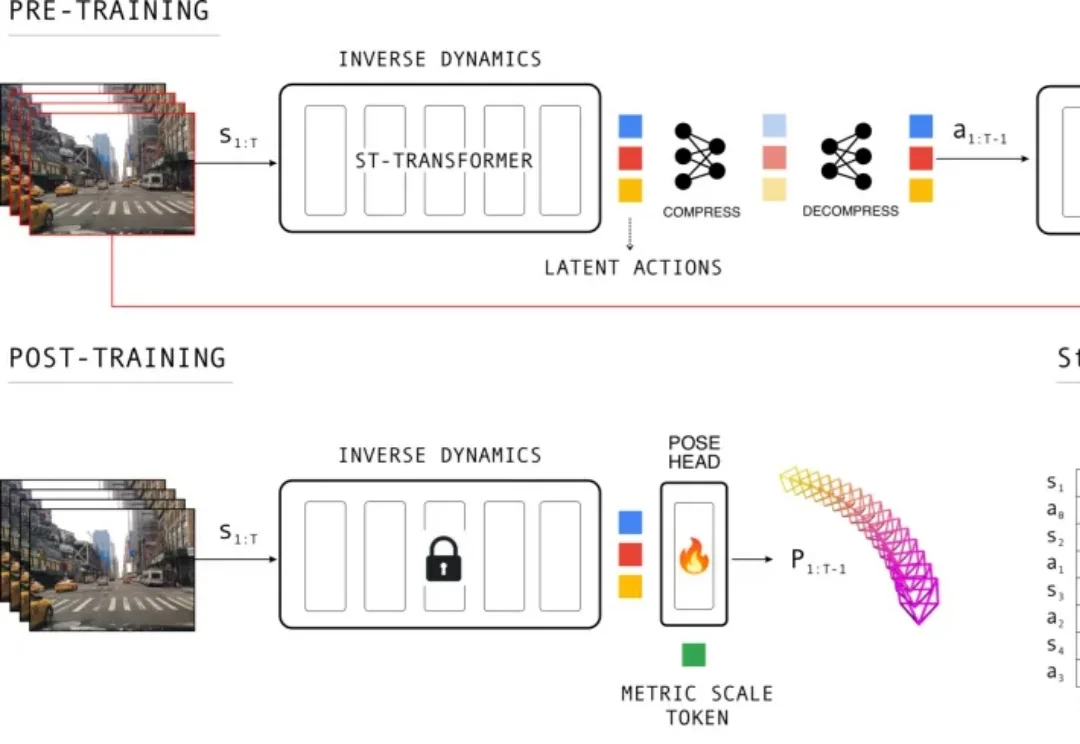
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。
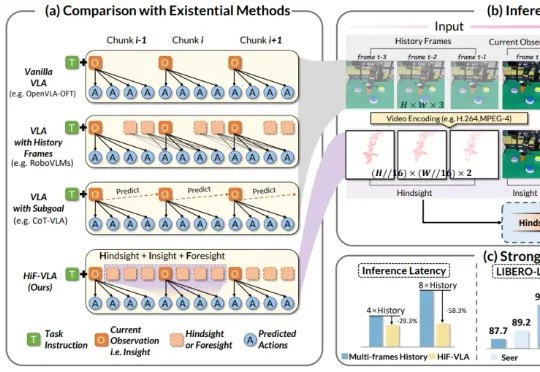
来自西湖大学、浙江大学、西湖机器人等机构的研究团队提出了一种以运动(Motion)为中心的全新双向时空推理框架 HiF-VLA。抛弃冗余的像素级输入,HiF-VLA 巧妙提取低维紧凑的 Motion 向量作为动态先验,在一个创新的「联合专家」模块中,同步完成未来视觉运动的预测与高精度动作序列的生成。
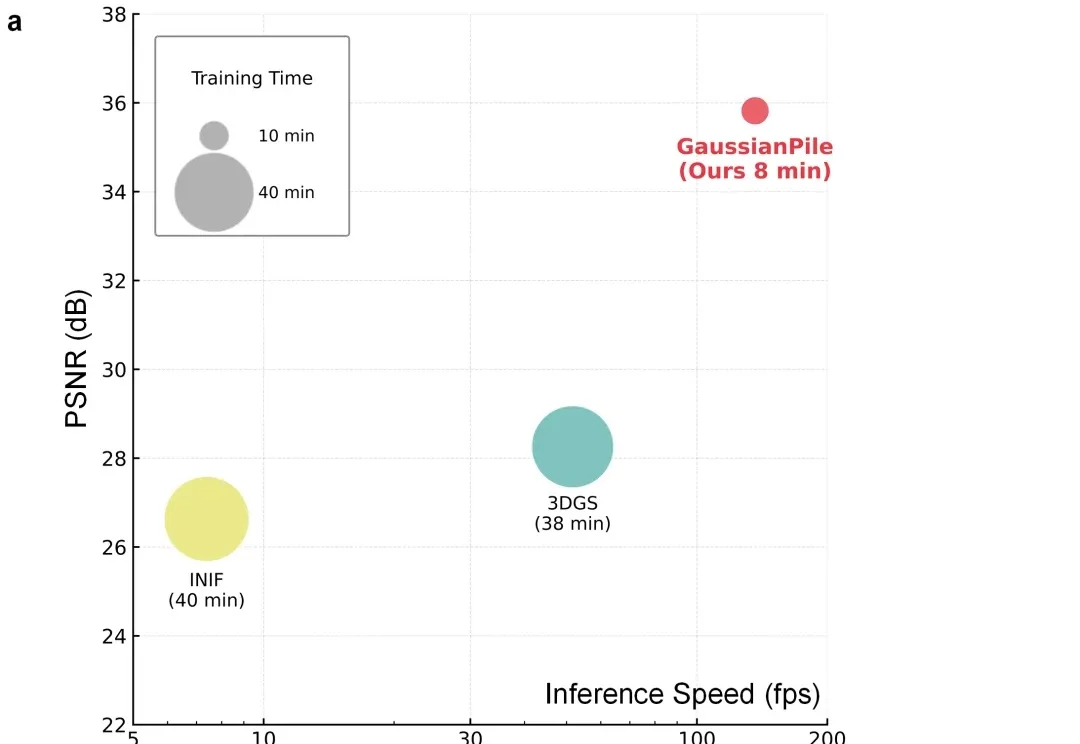
近年来,3D Gaussian Splatting(3DGS)在三维视觉和图形学中展现出很强的表示与渲染能力。相比传统体素或神经辐射场,它用一组可优化的各向异性高斯来表示三维场景,既能保留连续空间结构,又能实现高速渲染。
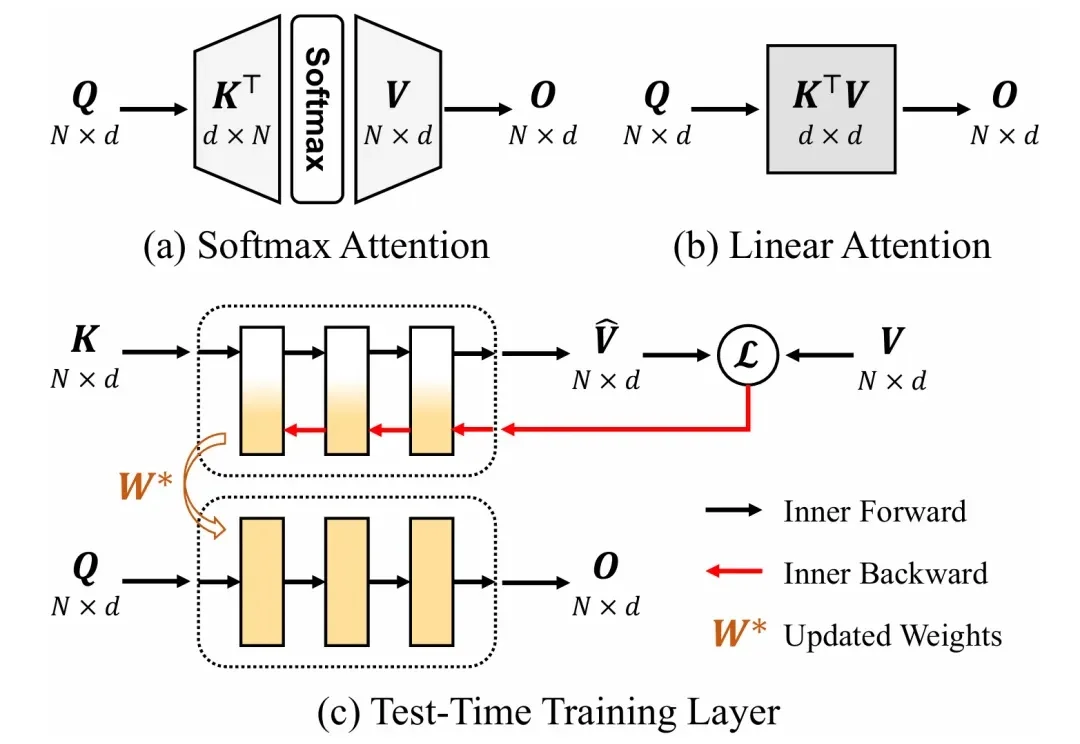
序列建模是大语言模型、计算机视觉等领域的基础共性问题。当前通用的 Transformer 模型计算复杂度随序列长度平方增长,在长序列任务中面临显著的计算挑战。因此,研究者们一直在探索具有线性计算复杂度的高效序列建模方法。
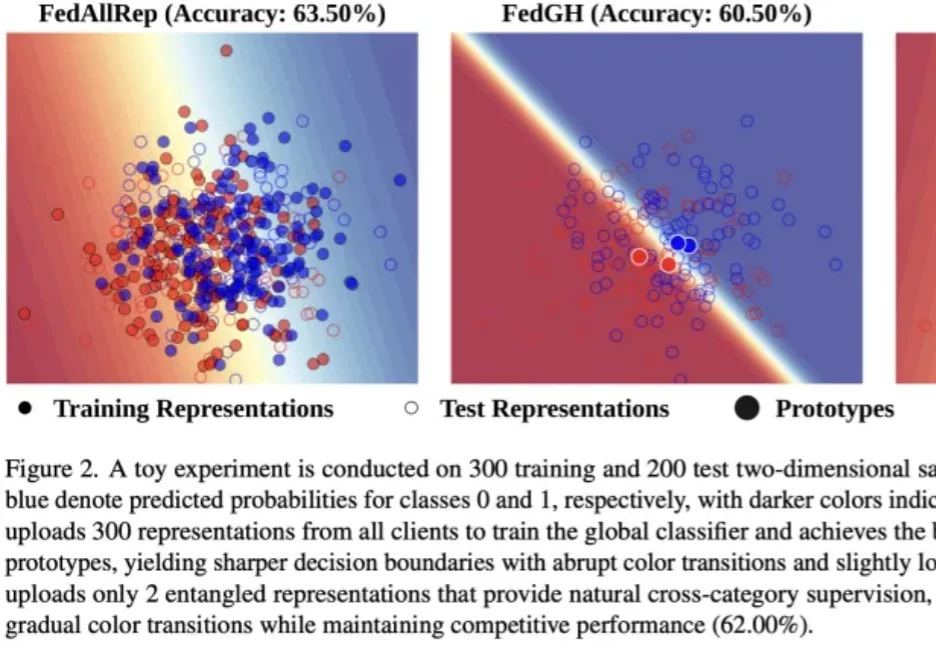
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。

家用电器是家庭服务机器人最难啃的一类任务对象。与桌面物体操作相比,家电操作不仅涉及按钮、旋钮、门体等多种异构部件,还受到模式切换、状态约束和程序逻辑的共同支配。真正完成一次家电任务,机器人往往既要「看得见」,也要「读得懂」,还要「按说明书做对」。
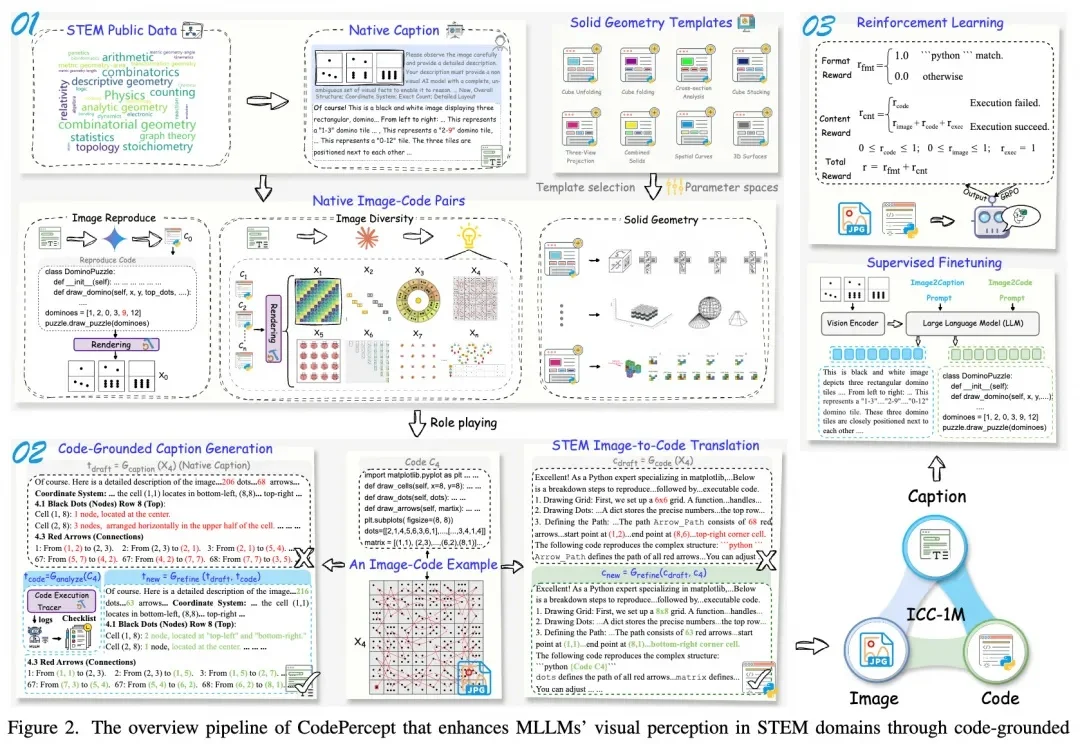
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。