首个,专攻点云上下文学习自适应采样!支持点级、提示级|CVPR 2025
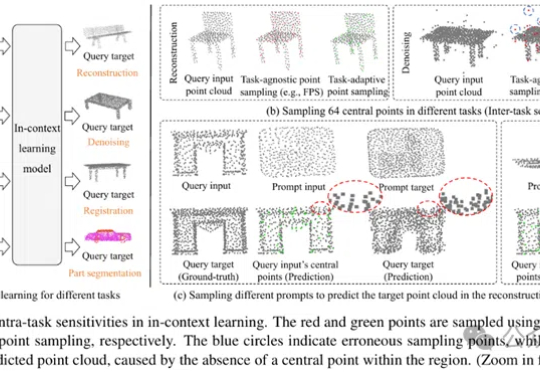
首个,专攻点云上下文学习自适应采样!支持点级、提示级|CVPR 2025MICAS是一种专为3D点云上下文学习设计的多粒度采样方法,通过任务自适应点采样和查询特定提示采样,提升模型在点云重建、去噪、配准和分割等任务中的稳健性和适应性,显著优于现有技术。
来自主题: AI技术研报
9684 点击 2025-05-14 14:28
 搜索
搜索
MICAS是一种专为3D点云上下文学习设计的多粒度采样方法,通过任务自适应点采样和查询特定提示采样,提升模型在点云重建、去噪、配准和分割等任务中的稳健性和适应性,显著优于现有技术。

近年来,生成式人工智能(Generative AI)技术的突破性进展,特别是文本到图像 T2I 生成模型的快速发展,已经使 AI 系统能够根据用户输入的文本提示(prompt)生成高度逼真的图像。从早期的 DALL・E 到 Stable Diffusion、Midjourney 等模型,这一领域的技术迭代呈现出加速发展的态势。
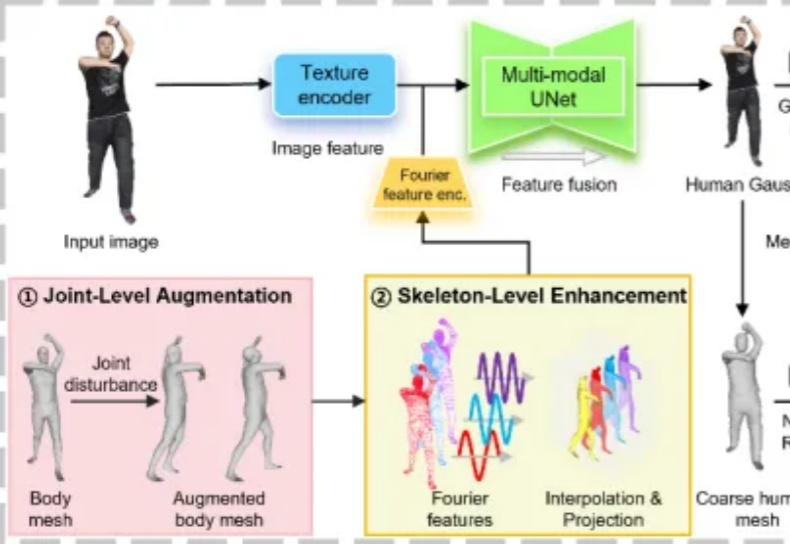
从人体单图变身高保真3D模型,不知道伤害了多少程序猿头发的行业难题,竟然被港科广团队一招破解了!

从单张低分辨率(LR)图像恢复出高分辨率(HR)图像 —— 即 “超分辨率”(SR)—— 已成为计算机视觉领域的重要挑战。

扩散模型(Diffusion Models, DMs)如今已成为文本生成图像的核心引擎。凭借惊艳的图像生成能力,它们正悄然改变着艺术创作、广告设计、乃至社交媒体内容的生产方式。
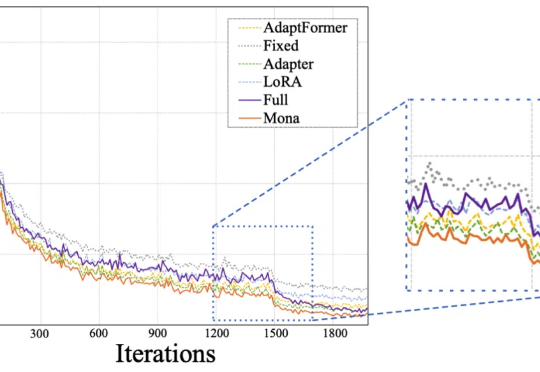
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。
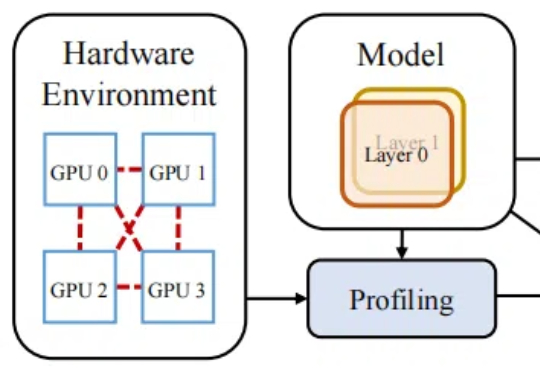
训练成本高昂已经成为大模型和人工智能可持续发展的主要障碍之一。
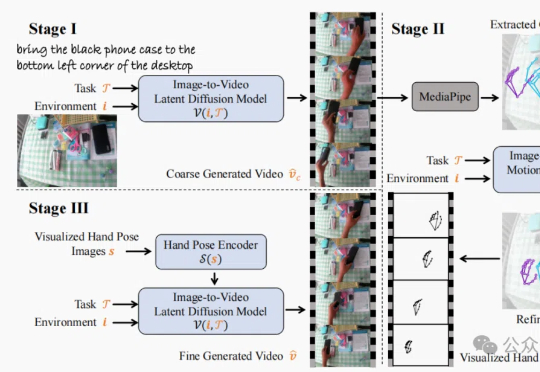
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
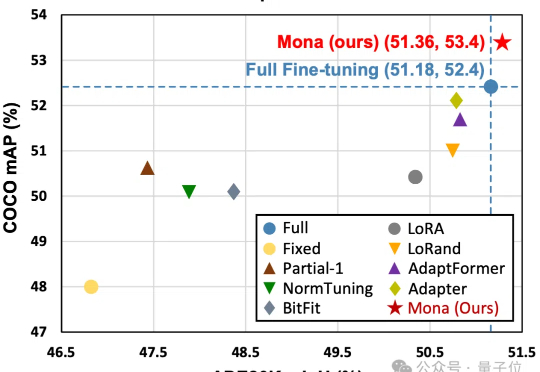
仅调整5%的骨干网络参数,就能超越全参数微调效果?!
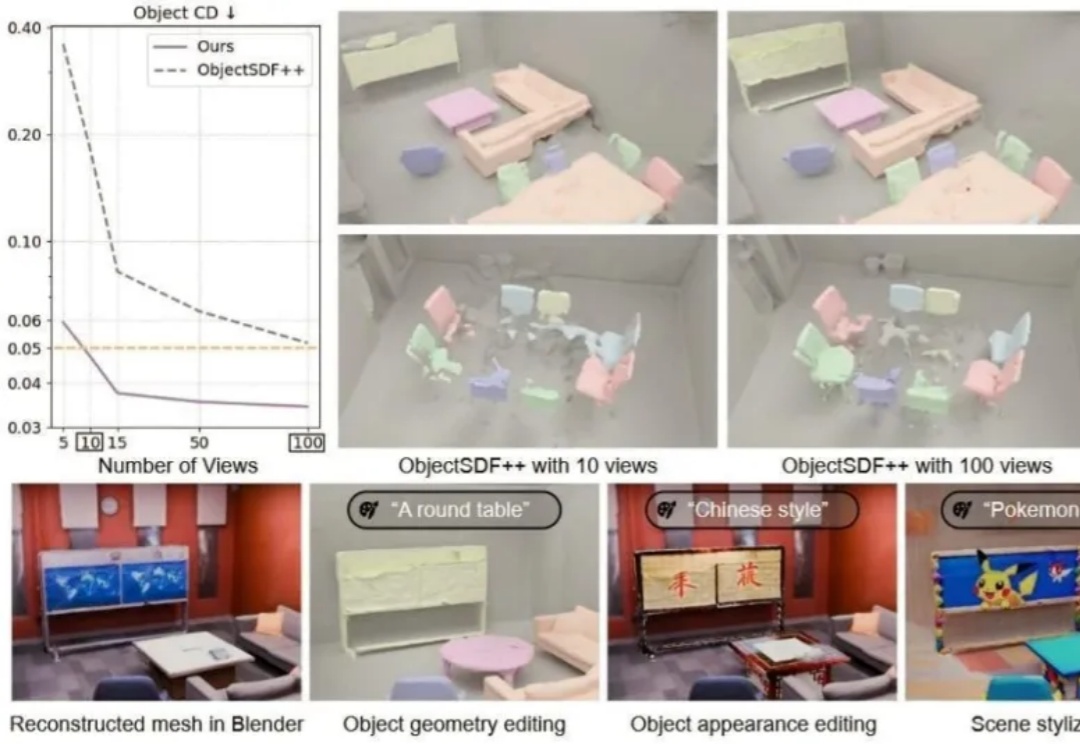
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?