
WAIC直击:200家机器人企业同场竞技,但物理AI的入场券属于闭环玩家
WAIC直击:200家机器人企业同场竞技,但物理AI的入场券属于闭环玩家在今天上午结束的「AI 进入物理世界」京东分论坛上,其对外集中展示了这套布局。除了首次集体亮相的 JoyAI 全系列大模型矩阵,具身数据采集体系、JoyInside 智能硬件和京东云 AI 基础设施也一同亮相,它们连同全链路业务场景组成了京东的物理 AI 闭环。
来自主题: AI资讯
9916 点击 2026-07-19 10:13
 搜索
搜索
在今天上午结束的「AI 进入物理世界」京东分论坛上,其对外集中展示了这套布局。除了首次集体亮相的 JoyAI 全系列大模型矩阵,具身数据采集体系、JoyInside 智能硬件和京东云 AI 基础设施也一同亮相,它们连同全链路业务场景组成了京东的物理 AI 闭环。
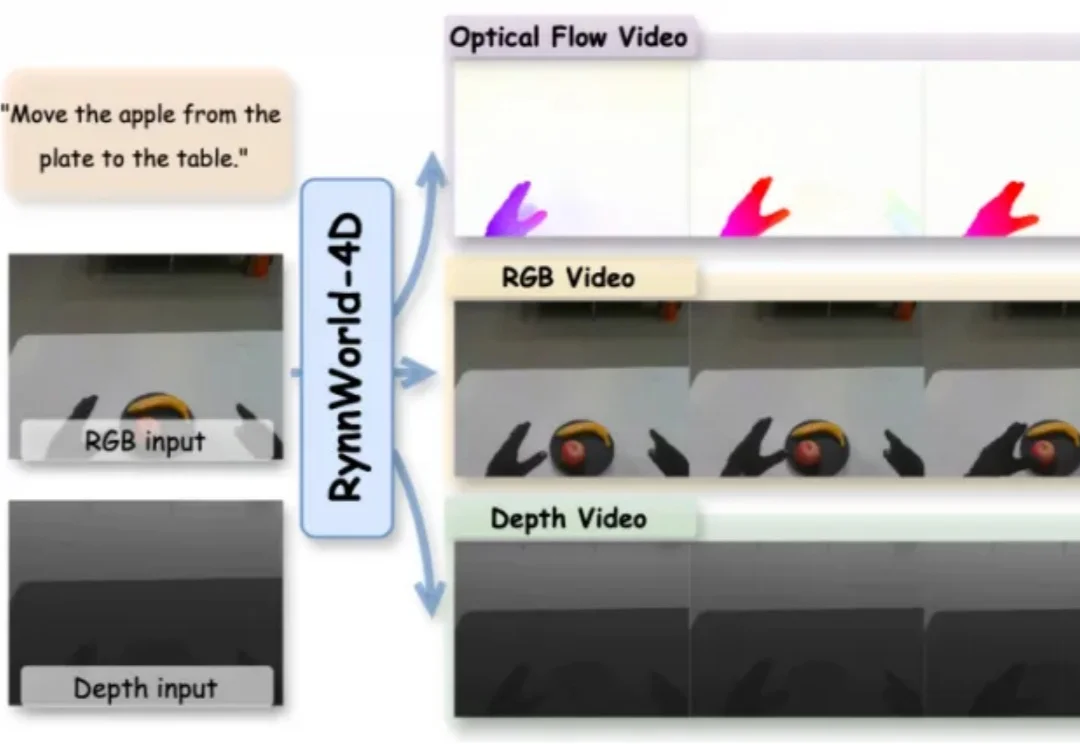
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。

前阶跃 Agent 产品负责人钟十六最近的一篇文章,尝试从产品视角回答这个问题。他描绘了一个 Loop 成熟后的未来图景,Agent 将成为自行运转的项目中心,人只需要在关键时刻现身拍板。在他看来,Loop 真正的价值不在于会重复跑任务,而在于它会带着你的每一次判断持续成长,一轮轮变成更懂你的系统,最终沉淀为长期运转的资产。

本文发现图生视频(I2V)模型天然适合重构动态交互过程,并提出 SCPE(Self-Correcting Process Editing) 多智能体系统自纠错框架:利用视频生成过程暴露失败原因,再通过分析、反思和工具书更新迭代增强提示,使 I2V 模型在复杂 HOI 编辑中显著提升交互准确性与推理能力。

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。
7月7日,Fable 5没下线!就在凌晨,Anthropic突然官宣, 最强Claude Fable 5限时免费,延长到了7月12日。比原计划,又多了足足五天的「白嫖」时间。具体用法,和之前一模一样,每周使用限额50%,超出之后想继续用,就得买credits了。

两年后,Fable 5 级 AI,可能就躺在你的笔记本里。就在昨天,全球最大的本地大模型社区r/LocalLLaMA,一张图刷屏了整个AI圈——标题简单粗暴:如果趋势持续,Mythos级能力可能在2年内运行在高端消费级硬件上。

Kimi、智谱和 MiniMax 幕后的 “财务管家”Airwallex 空中云汇,正尝试回答 “AI 时代钱如何在全球丝滑流动” 这一难题。近期,Airwallex 完成 3.2 亿美元 H 轮融资,成为估值 110 亿美元超级独角兽。本轮融资由 Addition 领投,Baillie Gifford、 Amex Ventures 等几家欧美资本跟投

近日,西班牙AI机器人公司 Theker 宣布完成7300万欧元(约合8500万美元)的A轮融资。这是欧洲机器人领域史上规模最大的A轮融资。时尚巨头Zara的母公司Inditex不仅是公司早期投资方,公司机器人已在Inditex的实际生产设施中运行。

近日,《金融时报》报道称AI for Science企业CuspAI将完成一轮4亿美元融资,投资方包含亚马逊创始人杰夫・贝佐斯家族办公室Bezos Expeditions与知名风投凯鹏华盈(Klein