
我们开源了一个可以降低 AIGC 率的模型
我们开源了一个可以降低 AIGC 率的模型最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
来自主题: AI技术研报
9284 点击 2026-05-27 09:24
 搜索
搜索
最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
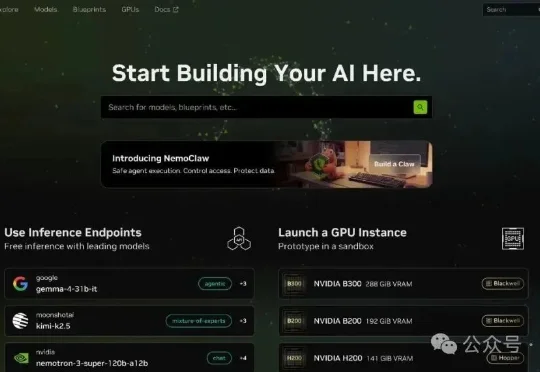
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。
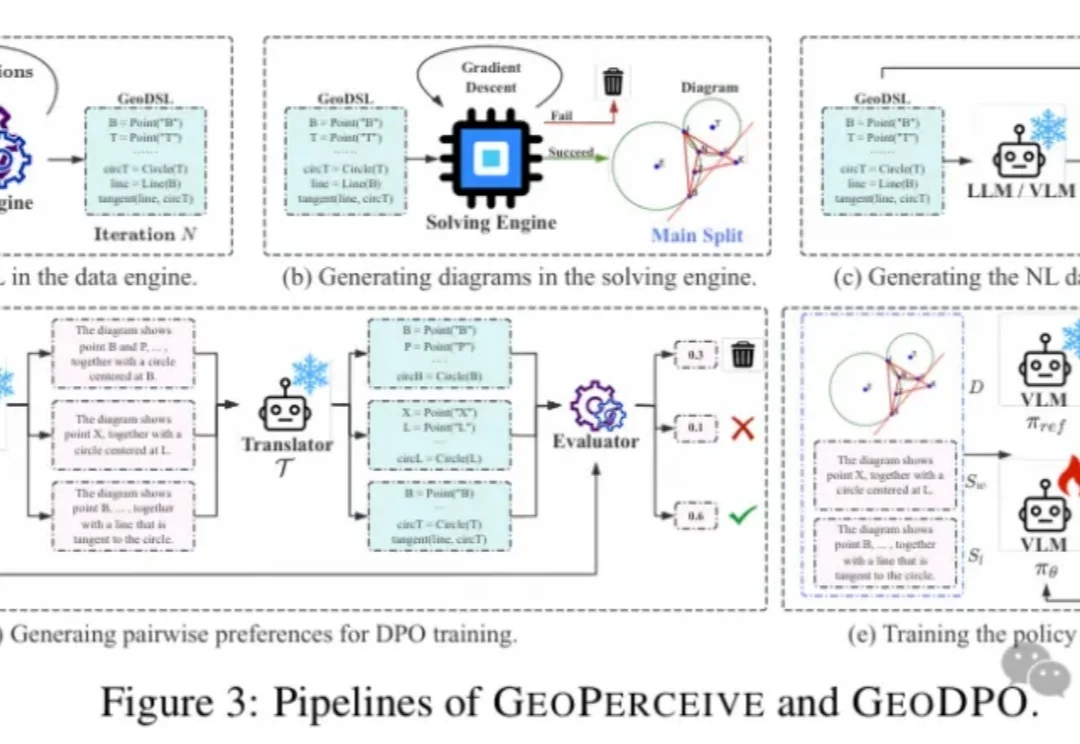
几何问题,真的只是“推理难”吗?
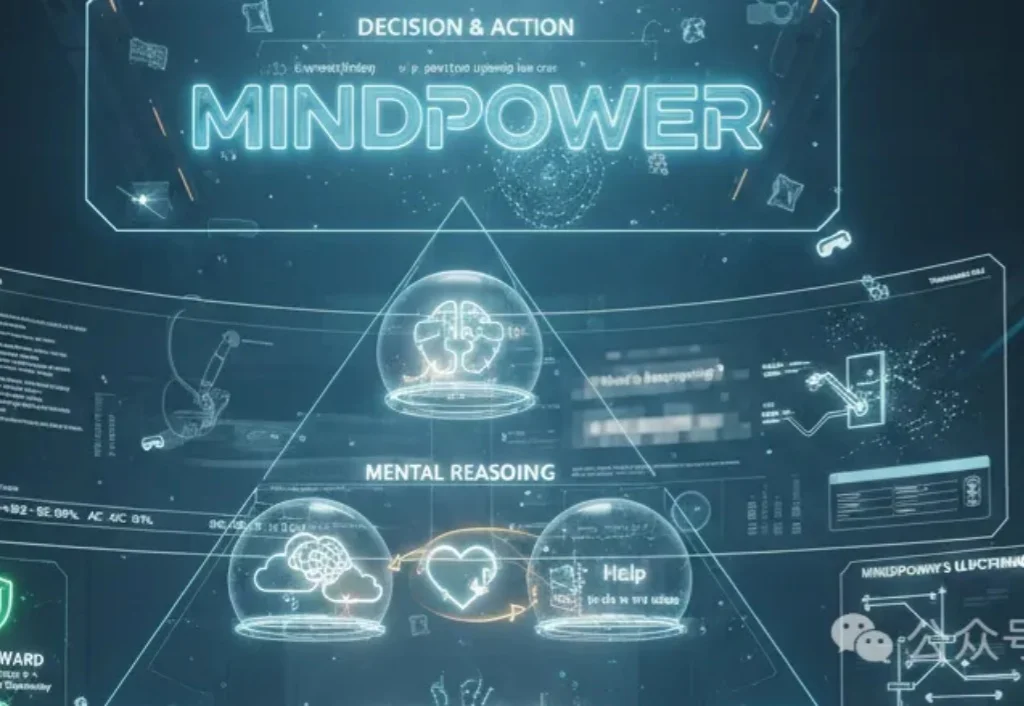
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。
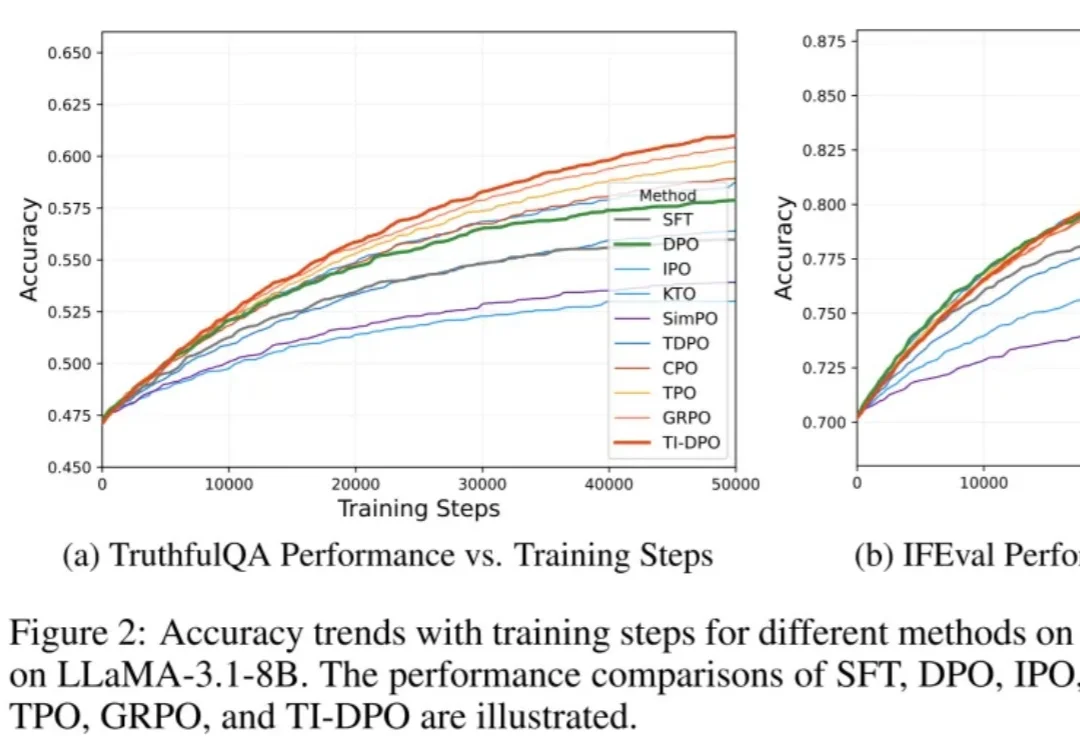
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
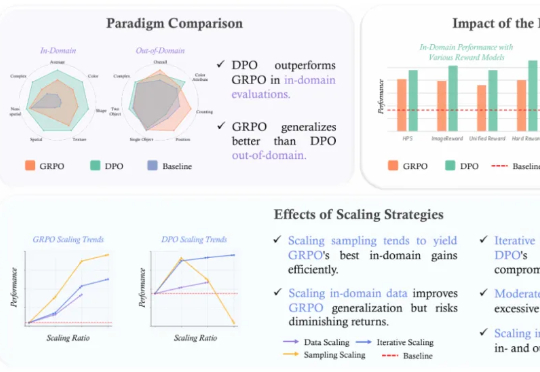
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。
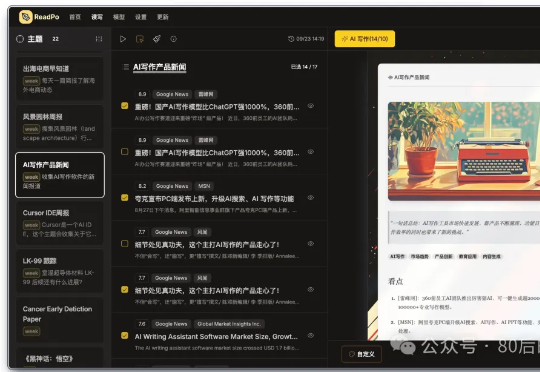
最近在WaytoAGI社区,留意到有朋友在用一款海报,发送最新的咨询信息,并且信息整理详尽,你可以从无序的新闻热点里,跳出来了。 那么今天介绍的,ReadPo 是 AI 驱动的读写助手。以闪电般的速度帮你完成信息的收集和筛选,并创建引人入胜的新内容。
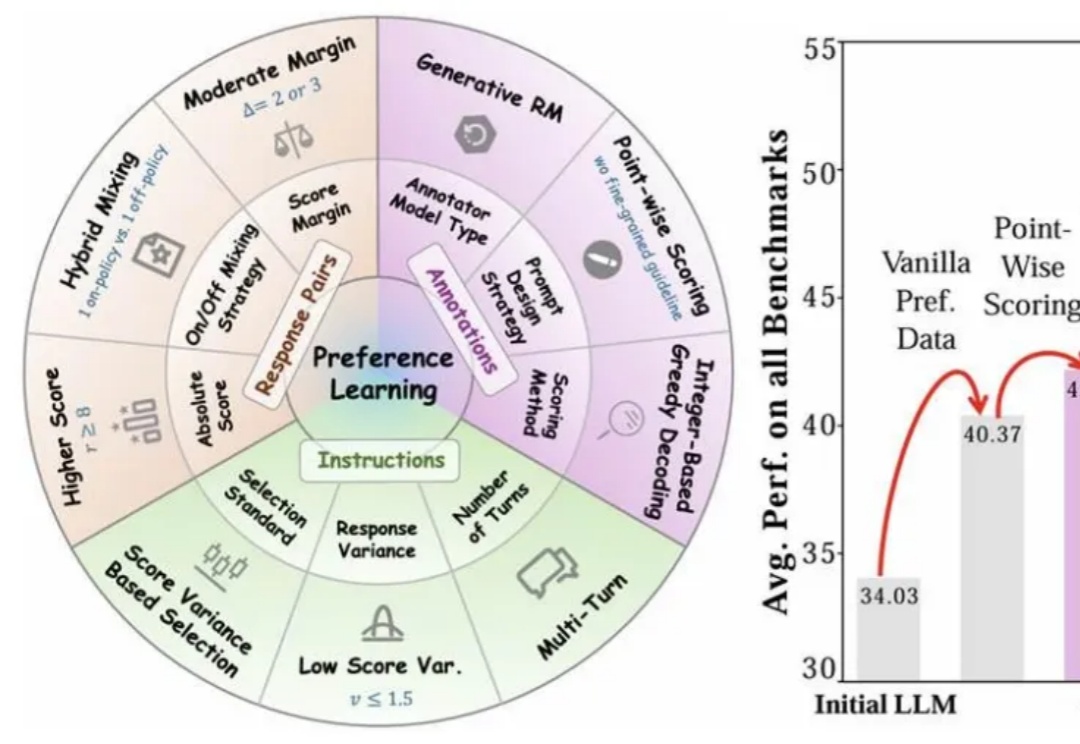
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。

近日,在红点创投(Redpoint Venture)的播客“Unsupervised Learning”上,红点创投合伙人Jacob Effron与David Luan进行了一次访谈。他们从技术视角出发,探讨了DeepSeek给大模型领域的研究和实践带来的启示,并围绕AI模型当下瓶颈的思考和潜在的突破方向做了分享。