142页重磅,DeepSeek-R1的"甜蜜点",开创了一个崭新的研究领域“思维学”。 | 最新
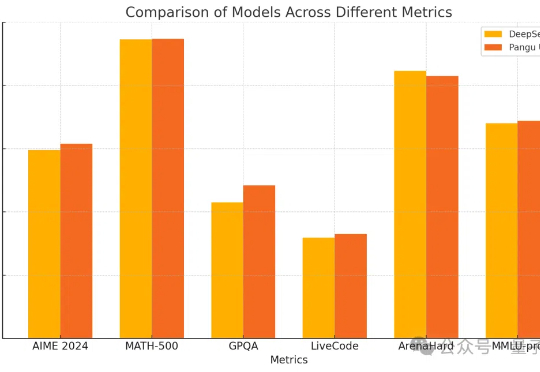
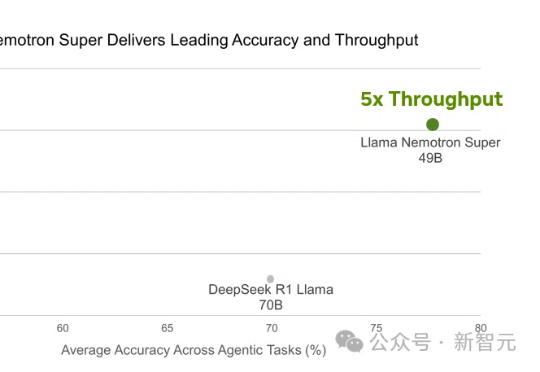
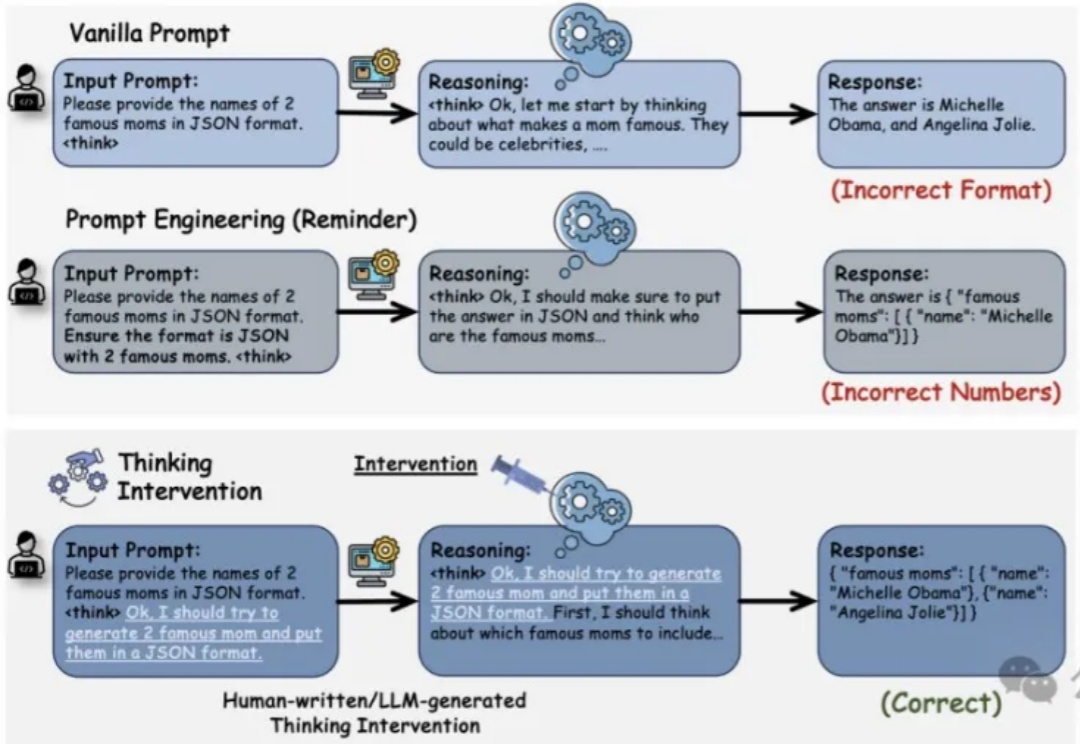
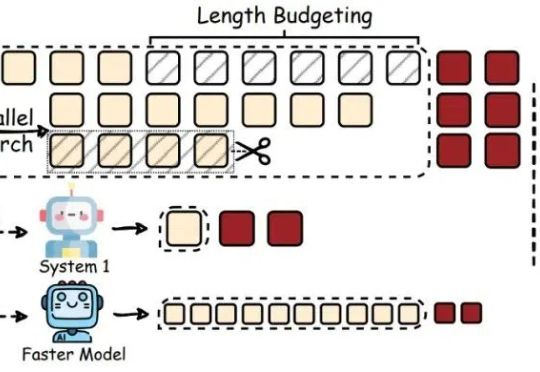
142页重磅,DeepSeek-R1的"甜蜜点",开创了一个崭新的研究领域“思维学”。 | 最新这是一份142页的研究论文,本文深入解析了大型推理模型DeepSeek-R1如何通过"思考"解决问题。研究揭示了模型思维的结构化过程,以及每个问题都存在甜蜜点"最佳推理区间"的惊人发现。这标志着"思维学"这一新兴领域的诞生,为我们理解和优化AI推理能力提供了宝贵框架。
来自主题: AI技术研报
8845 点击 2025-04-17 14:26