
ISSTA 2026|LAVE:面向扩散语言模型的约束解码
ISSTA 2026|LAVE:面向扩散语言模型的约束解码推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
来自主题: AI技术研报
9010 点击 2026-07-16 10:09
 搜索
搜索
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
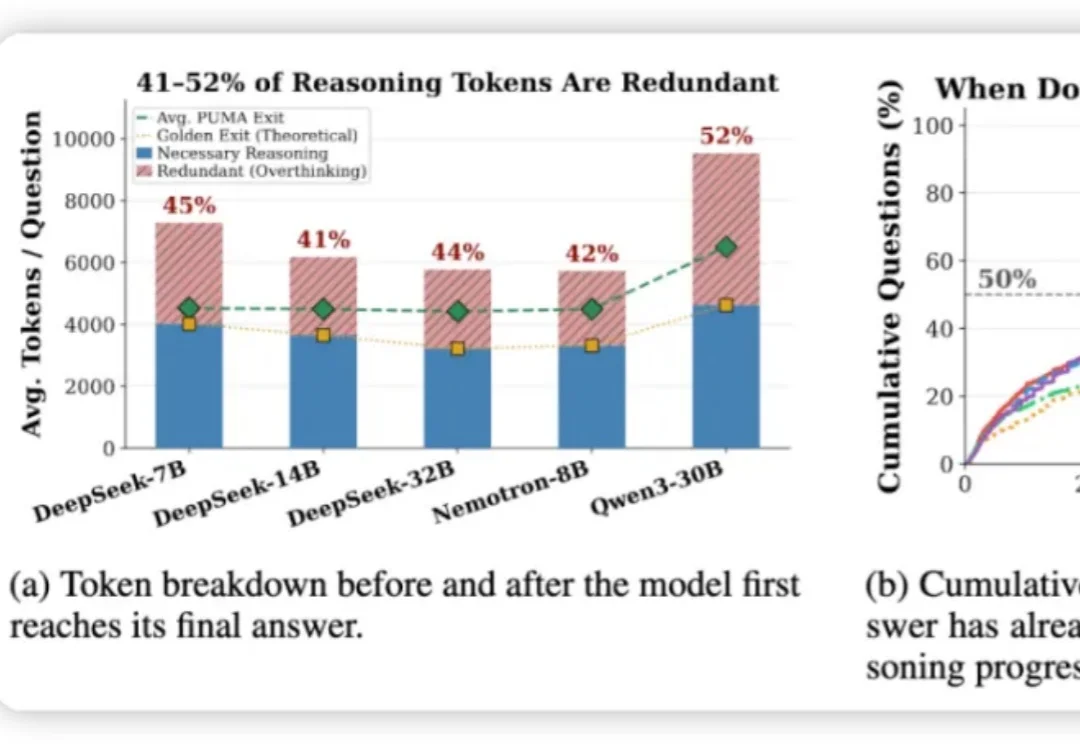
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。
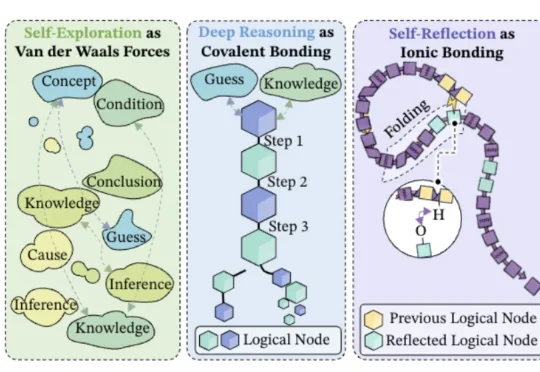
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。