刚刚,DeepSeek-V3.1「终极版」重磅发布!最大提升超36%,V4/R2还远吗?
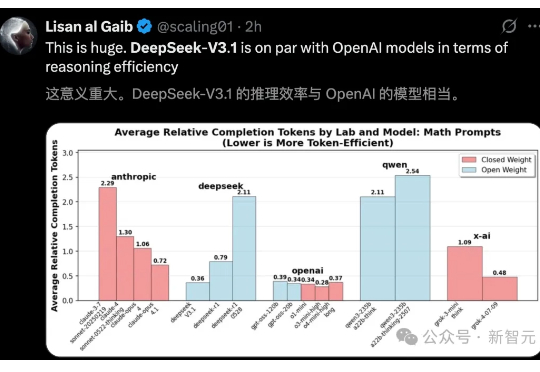
刚刚,DeepSeek-V3.1「终极版」重磅发布!最大提升超36%,V4/R2还远吗?DeepSeek最新模型DeepSeek-V3.1-Terminus来了!此前在输出中随机掺入「极」字的问题得到显著缓解,Humanity's Last Exam成绩也较V3.1提升1/3!Terminus这个名字是否在暗示DeepSeek-V4也快要来了?
来自主题: AI资讯
10558 点击 2025-09-23 01:25