# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“DeepSeek-V3是在Mistral提出的架构上构建的。”
欧洲版OpenAI CEO此言一出,炸了锅了。
网友们的反应be like:

这还是温和派,还有更直接的吐槽:Mistral在胡说八道些什么……

还没吃上瓜的家人们别着急,咱们从头捋一捋这事儿:
在最近一次访谈中,当被问到如何看待中国开源AI的强势发展时,Mistral联合创始人、CEO Arthur Mensch这样回应:
中国在AI领域实力强劲。我们是最早发布开源模型的公司之一,而他们发现这是一个很好的策略。
开源不是真正的竞争,大家在彼此的基础上不断进步。
比如我们在2024年初发布了首个稀疏混合专家模型(MoE),DeepSeek-V3以及之后的版本都是在此基础上构建的。它们采用的是相同的架构,而我们把重建这种架构所需的一切都公开了。

Arthur Mensch很自信,但网友们听完表示:桥豆麻袋,这不对劲。
且不说DeepSeek MoE论文的发布时间和Arthur Mensch提到的Mixtral论文相差仅3天:


认真细扒起来,两种架构实际上思路也并不相同。
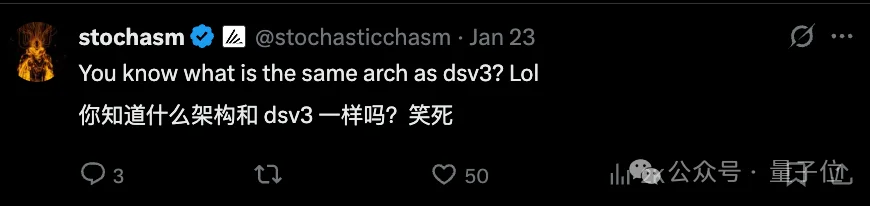
并且此前,Mistral 3 Large还曾被扒出基本上照搬了DeepSeek-V3采用的架构……
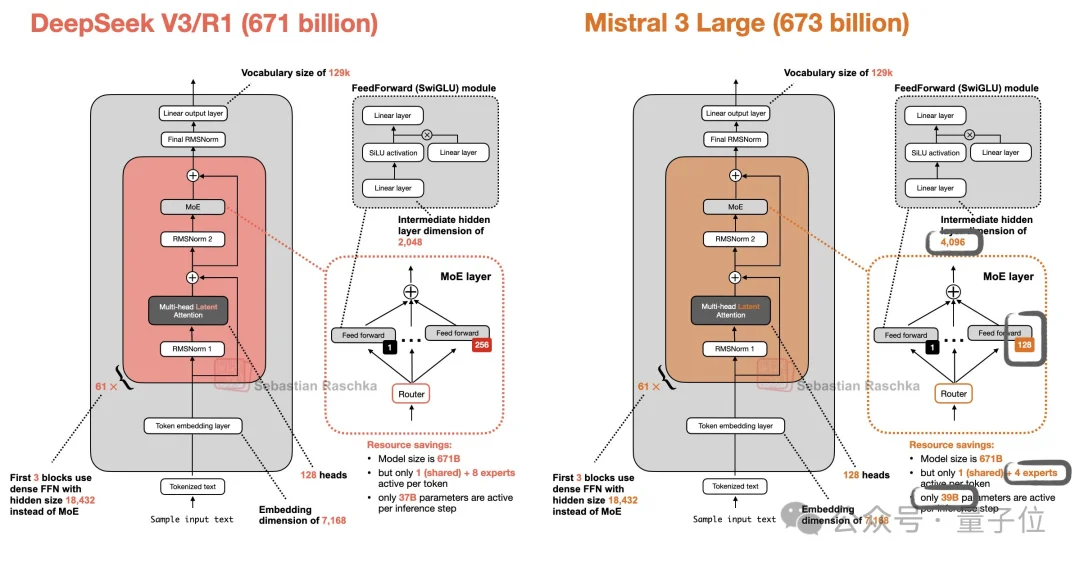
△图源:𝕏@Sebastian Raschka
甭管怎么说,Mistral这发言一出来,严谨的网友们第一反应还是精准论证。
两篇论文都在arXiv上立等可看,那么就是一手直接开扒。
Arthur Mensch说的没错的一点是,这两篇发表时间相差3天的论文,研究的都是稀疏混合专家系统(SMoE),目的都是通过稀疏激活来降低计算成本并提升模型能力。
但两者在出发点上就有所不同——
Mixtral偏向于工程思维,重点放在证明强大的基础模型+成熟的MoE技术,可以实现超越更大稠密模型的效果。
而DeepSeek的核心在于算法创新。论文试图解决传统MoE中专家“学得太杂”和“重复学习”的问题,本质上是对MoE架构的重新设计。

数学公式可以更直观地反映区别。
Mixtral:
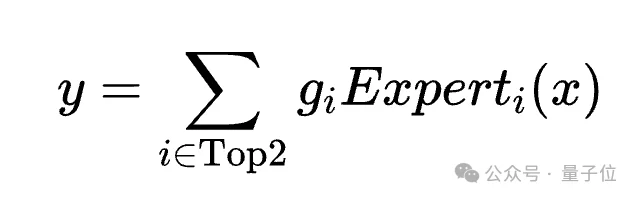
DeepSeek:
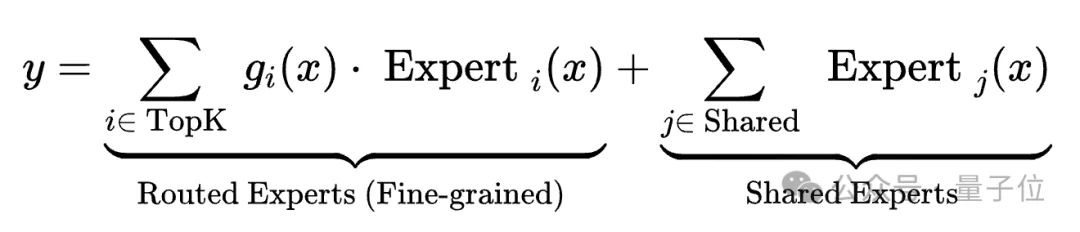
两者的采用了GShard风格的Top-K router。但DeepSeek改变了传统MoE架构中的门控机制和专家结构。
在专家粒度和数量方面,Mixtral沿用了标准的MoE设计,每个专家都是一个完整的FFN块。
DeepSeek则提出了细粒度专家分割,在保持总参数量不变的情况下,将大专家切分成了许多个小专家。通过更细的切分,不同的专家可以更灵活地组合,从而实现更精准的知识习得。
在路由机制上,Mixtral中所有专家地位平等,路由网络根据输入动态选择专家。
DeepSeek引入了共享专家,共享专家不参与路由,总是被激活,而路由专家参与Top-K竞争。
这就使得Mixtral的知识分布是扁平的,通用知识和特定知识混杂在同一个专家内;而DeepSeek的知识分布是解耦的,共享专家负责通用知识,路由专家负责特定知识。
另外,有网友提到,Mixtral of Experts这篇论文实际上完全没讲训练细节,只是提到“我们采用了Google GShard架构,采用了更简单的路由,并且每一层都使用了MoE”,至于数据、超参数、训练token、消融实验……一概没提。
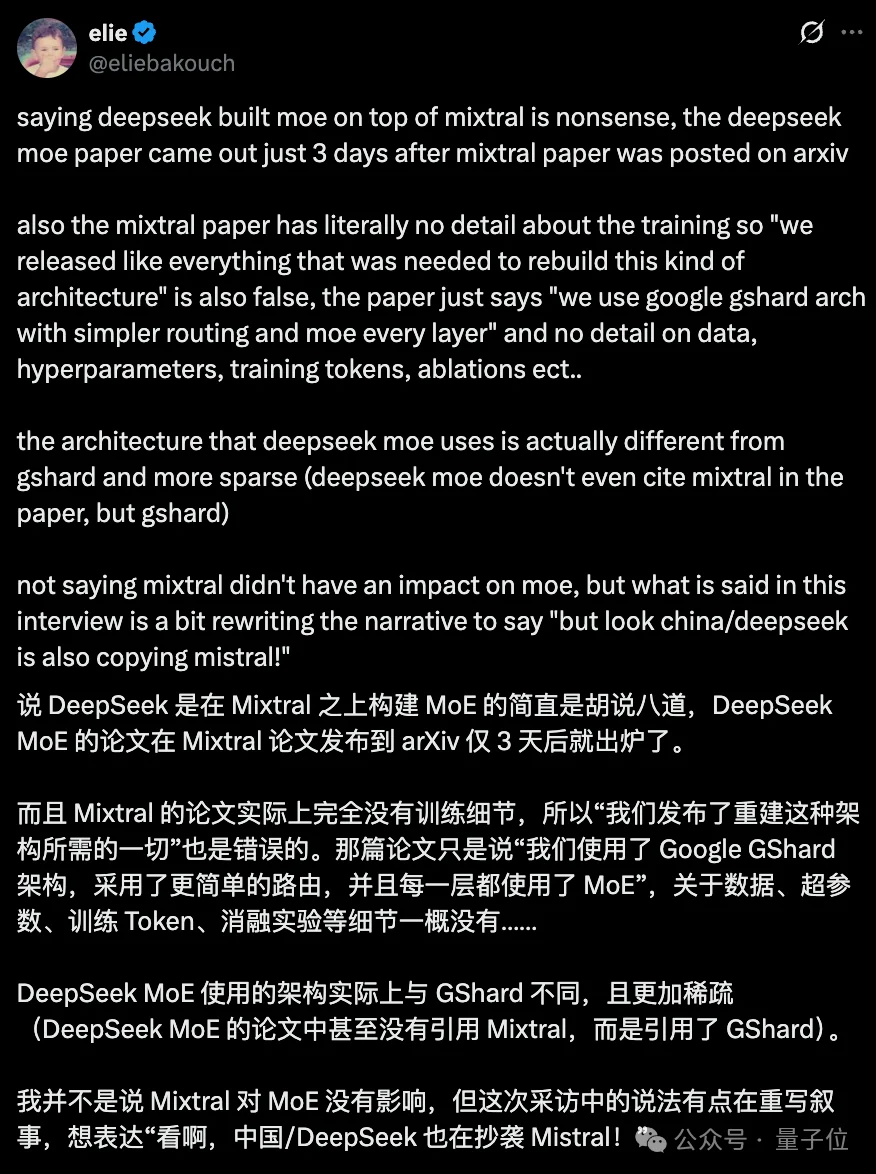
因崔斯汀的一点是,倒是2025年12月发布的Mistral 3 Large,被发现直接沿用了DeepSeek-V3的架构。

倒不是说Mistral对MoE的推广没有贡献,但诚如网友所言,不可否认的是,DeepSeek最终在稀疏MoE、MLA等技术上获得了更大的影响力。

于是Arthur Mensch就显得有点“逆天”了:
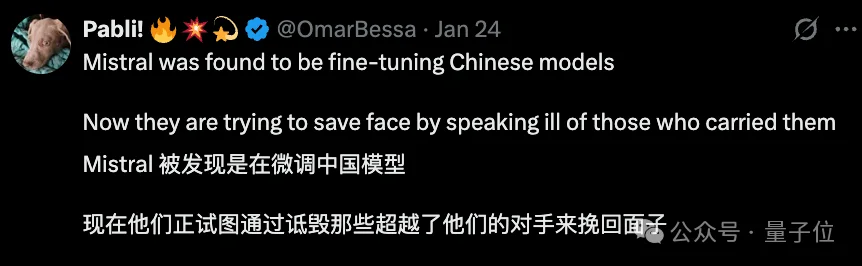
Mistral被发现用了DeepSeek的架构。现在他们试图通过岁月史书来挽回面子。
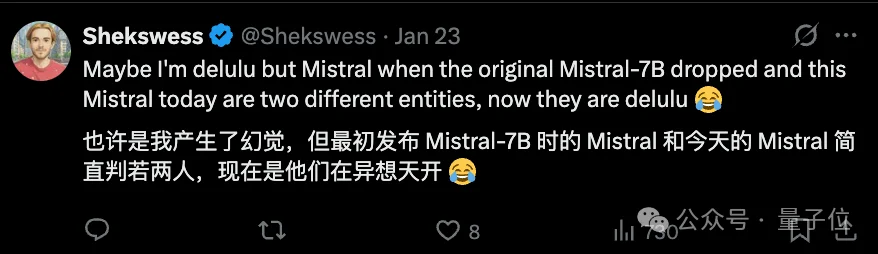
还有网友吐槽屠龙者终成恶龙,现在的Mistral,已经不是曾经惊艳大模型开源圈的那个Mistral了。
Anyway,嘴炮无用,接下来,围绕基础模型的竞逐,已经预告了精彩继续。
DeepSeek就被曝已经瞄准了春节档……

论文链接:
Mixtral:https://arxiv.org/abs/2401.04088
DeepSeek:https://arxiv.org/abs/2401.06066
参考链接:
[1]https://x.com/eliebakouch/status/2014575628675092845
[2]https://x.com/gm8xx8/status/2014676490797842907
文章来自于“量子位”,作者 “鱼羊”。


