2026 国内新增独角兽全梳理:3 天一家、AI 和机器人占了一半,DeepSeek 估值最高
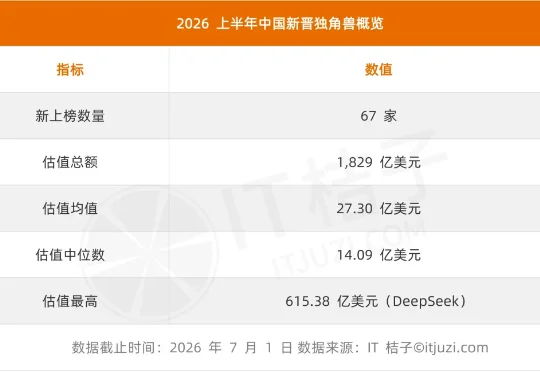
2026 国内新增独角兽全梳理:3 天一家、AI 和机器人占了一半,DeepSeek 估值最高截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家:
来自主题: AI资讯
8449 点击 2026-07-11 11:19