2026年,1800个DeepSeek跟我一起守护艾泽拉斯
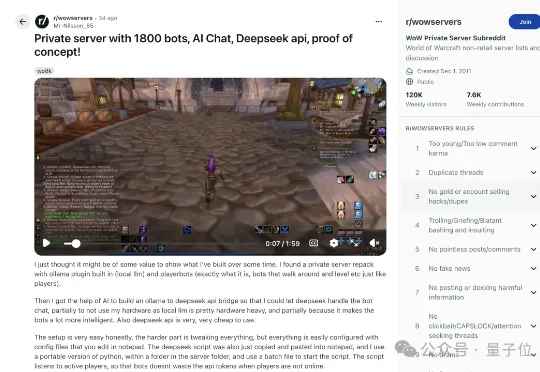
2026年,1800个DeepSeek跟我一起守护艾泽拉斯最近,一位Reddit老哥手搓了一个《魔兽世界》私服——里面活跃着1800个AI玩家,而且全都接入了DeepSeek API,能像真人一样聊天、组队、于是,暴风城的聊天频道突然变成了DeepSeek广场,画风大概是这样的:
来自主题: AI资讯
9103 点击 2026-06-21 11:32
 搜索
搜索
最近,一位Reddit老哥手搓了一个《魔兽世界》私服——里面活跃着1800个AI玩家,而且全都接入了DeepSeek API,能像真人一样聊天、组队、于是,暴风城的聊天频道突然变成了DeepSeek广场,画风大概是这样的:

PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
CVPR 2026全部奖项揭晓!最佳学生论文荣誉提名颁给了ChordEdit,一作和通讯都是广东工业大学本科在读生。他们用一块7年半前的老Titan,跑完了全部实验。
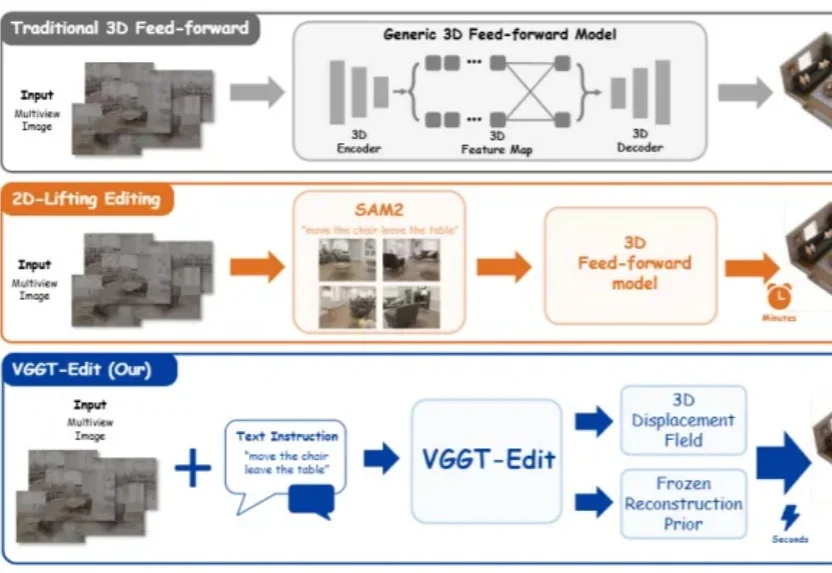
3D世界“会看”了,但还不会“改”。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
TRAE Editor for Unity 是一款专为 TRAE IDE 开发的,并内嵌于 Unity 编辑器的插件。它打通了 TRAE IDE 与 Unity 编辑器之间的协作链路,将 TRAE IDE 的基础功能、AI 辅助编码能力以及对 Unity 项目的深度理解融为一体,让你能够通过 Unity 编辑器直接唤起 TRAE IDE 编写代码,并便捷地回到 Unity 编辑器进行预览与调试。
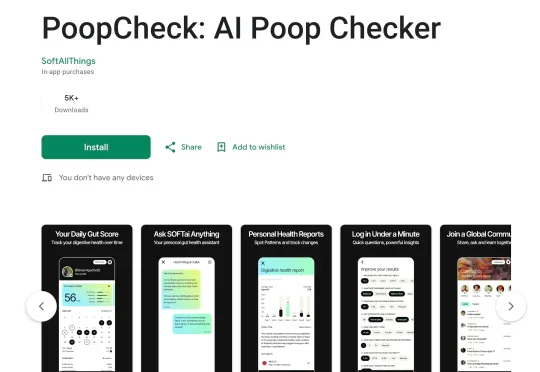
Reddit 上的 r/DHExchange 板块从来都不缺奇怪的交易。但月初的一个帖子,还是让见多识广的我打了个问号。「我囤积了一个非常有价值的大型数据库,只是不是你想的那种……15 万张粪便图像。」
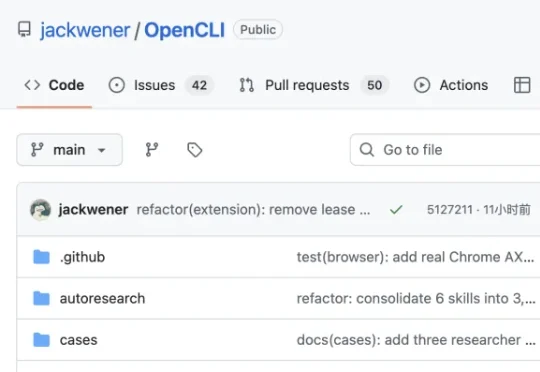
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。
我一直全程关注他打假的全过程,也一直有个想法:耿同学做的这些,能不能让 AI 分担一部分?这几天我琢磨了很久,也 Vibe Coding 了很久,最后做出来一个初版的 「学术打假 Skill——research-integrity-auditor」。