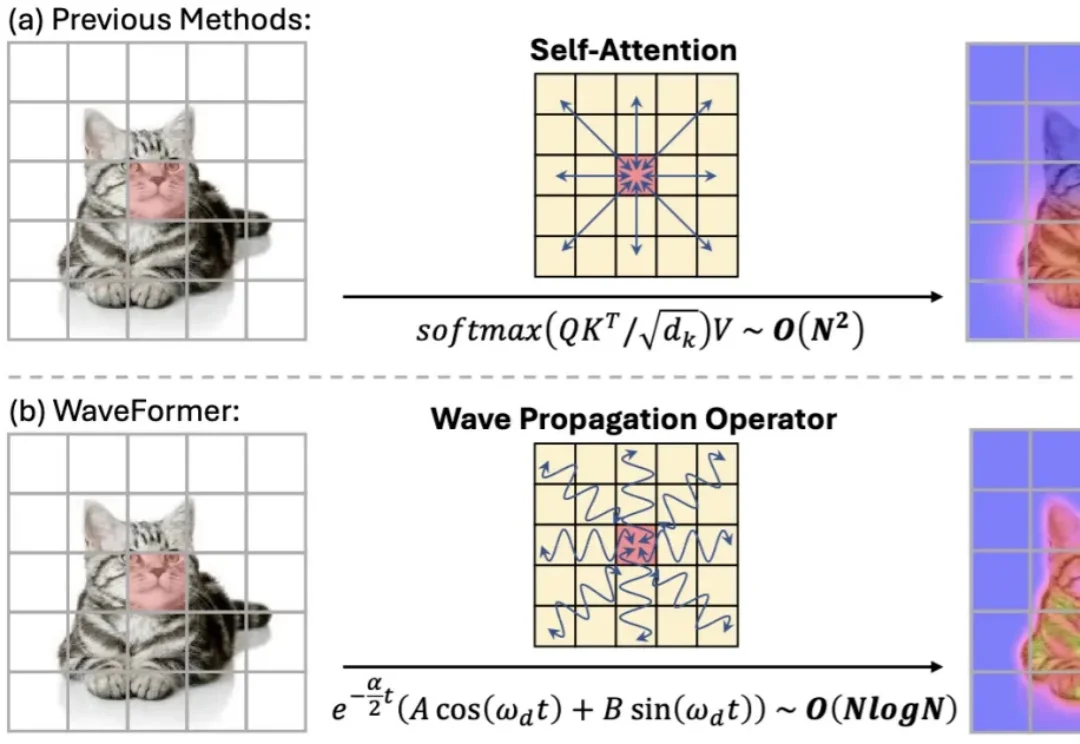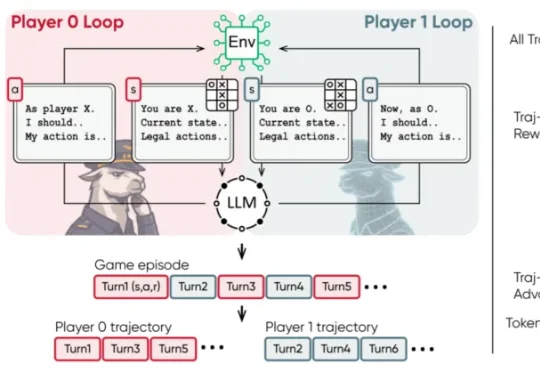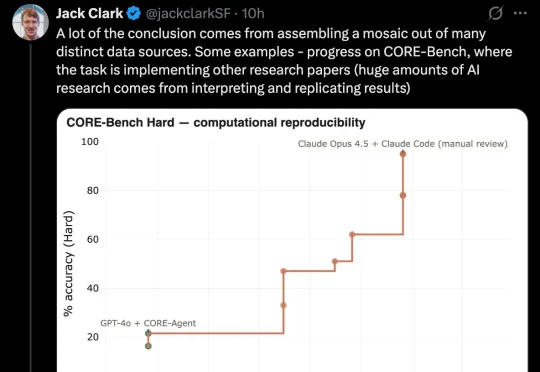
Anthropic联创定下deadline:2028年AI实现自我进化,没有人类了
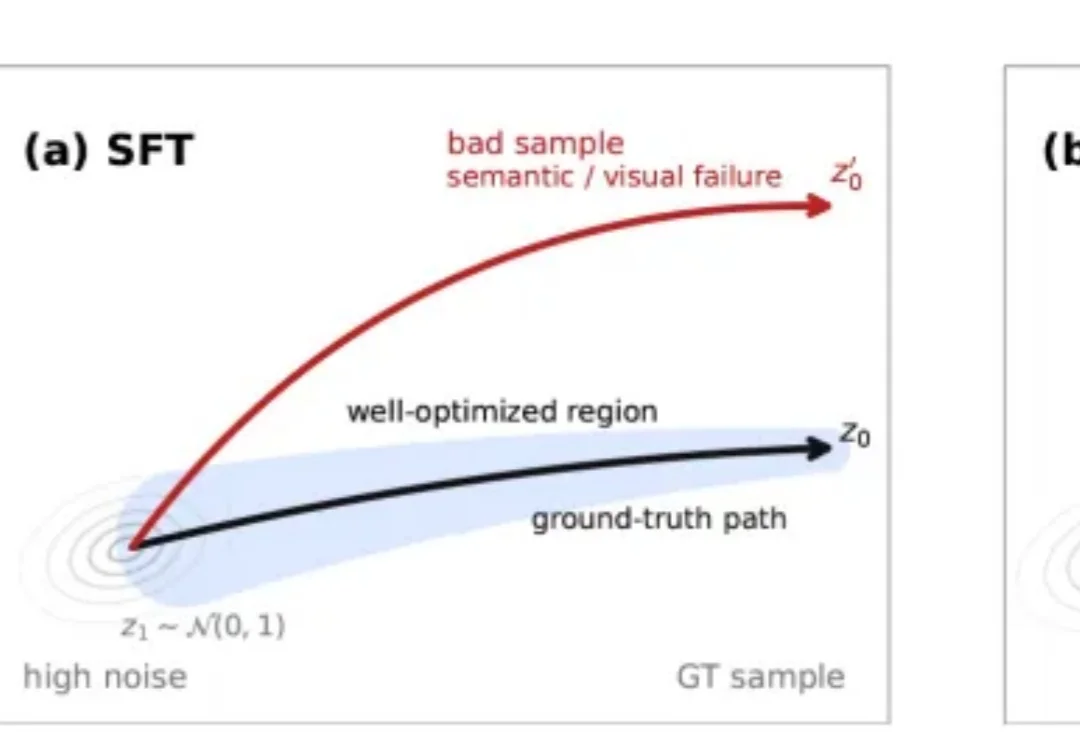
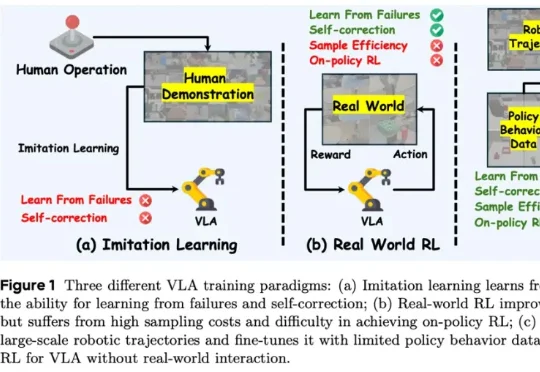
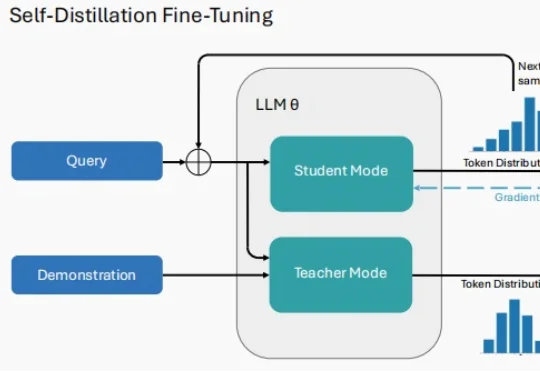
Anthropic联创定下deadline:2028年AI实现自我进化,没有人类了AI 很快就能自己改造自己了?Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。
来自主题: AI资讯
10106 点击 2026-05-05 13:20