
AI中转站正在「裸奔」:清华团队提出首个可信原生中转基础设施TrustedARI
AI中转站正在「裸奔」:清华团队提出首个可信原生中转基础设施TrustedARI当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。
来自主题: AI技术研报
8980 点击 2026-06-23 09:35
 搜索
搜索
当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。

近日,《金融时报》报道称AI for Science企业CuspAI将完成一轮4亿美元融资,投资方包含亚马逊创始人杰夫・贝佐斯家族办公室Bezos Expeditions与知名风投凯鹏华盈(Klein
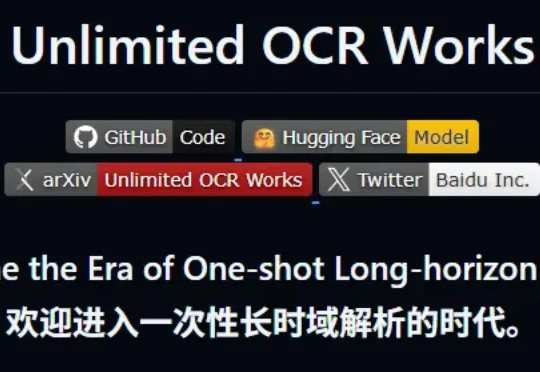
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。
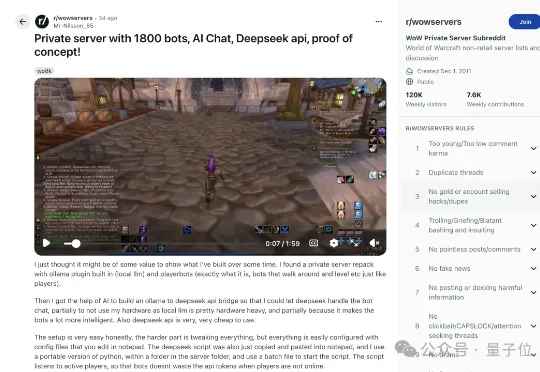
最近,一位Reddit老哥手搓了一个《魔兽世界》私服——里面活跃着1800个AI玩家,而且全都接入了DeepSeek API,能像真人一样聊天、组队、于是,暴风城的聊天频道突然变成了DeepSeek广场,画风大概是这样的:
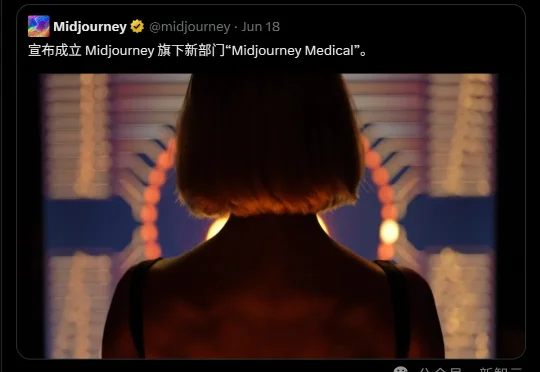
AI画图巨头突然杀入医疗圈!60秒泡个澡就能完成全身扫描,0.5毫米精度碾压CT和MRI,4PFlops的算力怪兽,让医疗行业今夜无眠。最惊人的是,Midjourney的终极目标竟是延长人类寿命,消灭全球30%的死亡。

近日,皮特·弗洛伦斯创办的具身智能公司Generalist AI完成了一轮新融资,总规模为4亿美元(约合人民币27亿元),估值为20亿美元(约合人民币135.5亿元)。本轮投资方包括英伟达旗下的NVentures、知名天使投资人纳特·弗里德曼(Nat Friedman)和丹尼尔·格罗斯(Daniel Gross)共同管理的NFDG

Waniwani宣布完成了800万美元的种子轮融资,由Seedcamp领投,Redstone、Zone II Ventures、Plug & Play、OPRTRs Club、Kima Ventures以及一批知名天使投资人跟投。
真正把灵动岛推上风口的,是 6 月以来接连发生的几件事。6 月 8 日的 WWDC 2026,苹果发布了全新的 Siri AI。Federighi 在台上的原话是,苹果要「带来下一代 Apple Intelligence,并推出 Siri AI,一个明显更聪明、更博学、也更能干的 Siri」。

搞AI绘画的Midjourney,要干上Spa了???
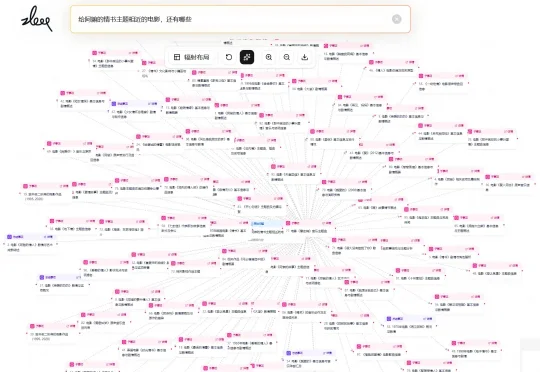
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。