
FP8模型不再挑卡!DeepSeek推理成本减半速度翻番,清华团队开源「赤兔」推理引擎
FP8模型不再挑卡!DeepSeek推理成本减半速度翻番,清华团队开源「赤兔」推理引擎「国产大模型 + 国产引擎 + 国产芯片」的完整技术闭环正在加速形成。
来自主题: AI资讯
10666 点击 2025-03-14 15:45
 搜索
搜索
「国产大模型 + 国产引擎 + 国产芯片」的完整技术闭环正在加速形成。
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。
DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。
DeepSeek开源第二弹如期而至。这一次,他们把MoE模型内核库开源了,支持FP8专为Hopper GPU设计,低延迟超高速训练推理。

DeepSeek开源第二弹如期而至。这一次,他们把MoE训推EP通信库DeepEP开源了,支持FP8专为Hopper GPU设计,低延迟超高速训练推理。
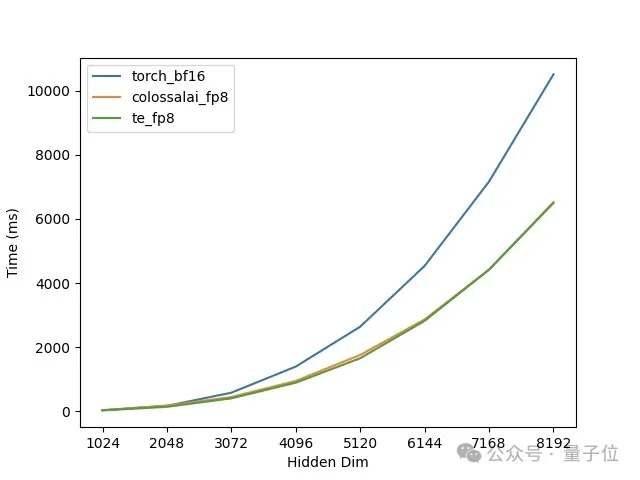
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。
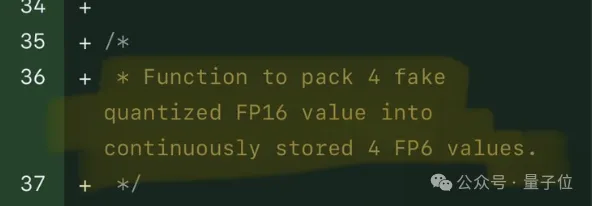
FP8和更低的浮点数量化精度,不再是H100的“专利”了!

今年GTC大会上,英伟达推出了地表最强Blackwell计算平台、NIM推理微服务、Omniverse Cloud API等惊喜新品。其中Blackwell GPU具有2080亿个晶体管,AI算力直接暴涨30倍。单芯片训练性能(FP8)是Hopper架构的2.5 倍,推理性能(FP4)是Hopper架构的5倍。具有第5代NVLink互连,并且可扩展至576个GPU。