
OpenAI突然宣布:GPT-5.6大幅降价,2折起售
OpenAI突然宣布:GPT-5.6大幅降价,2折起售今日,OpenAI宣布下调GPT-5.6系列模型API价格。其中,GPT-5.6 Luna价格下调80%,GPT-5.6 Terra价格下调20%,GPT-5.6 Sol则新增Fast模式,在保持模型能力不变的情况下,最高可实现2.5倍推理速度。
来自主题: AI资讯
8272 点击 2026-07-31 09:36
 搜索
搜索
今日,OpenAI宣布下调GPT-5.6系列模型API价格。其中,GPT-5.6 Luna价格下调80%,GPT-5.6 Terra价格下调20%,GPT-5.6 Sol则新增Fast模式,在保持模型能力不变的情况下,最高可实现2.5倍推理速度。
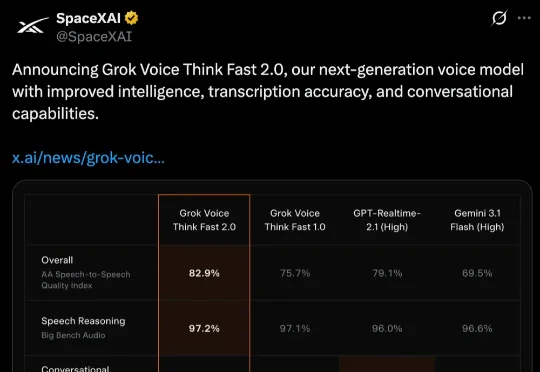
今日,马斯克旗下SpaceXAI宣布推出新一代语音模型Grok Voice Think Fast 2.0,这是该公司迄今能力最强的语音到语音(speech-to-speech)模型。马斯克连发两条推文,第一条宣布“Grok Voice现在在智能体性能方面排名第一”,第二条则直接喊话网友“试试新的Grok Voice”。

以 LeWorldModel(LeWM)为例,它在规划时有一个重要瓶颈:每评估一条候选动作序列,模型都要一步步自回归 rollout。也就是说,LeWM 先预测下一步 latent,再把预测出的 latent 输入 dynamics model,继续预测下一步:
做了一年 Agent 基础设施,踩了无数坑,我终于想明白了一件事:好的 Agent 架构不是把所有功能塞进一个进程,而是让每一层都能独立演化。

昨晚,字节新模型Seedance 2.0 Mini深夜来袭,该模型主打性价比,侧重于提供更低的价格以及更快的生成速度。Seedance 2.0 Mini虽然定价更低,但保留了核心能力参考生成,用户可以通过融合提示词与最多12个多种模态的参考素材(包括6张图片、3段音频、3段视频)来锁定人物一致性、精细化控制运动轨迹、卡准剧情节奏。
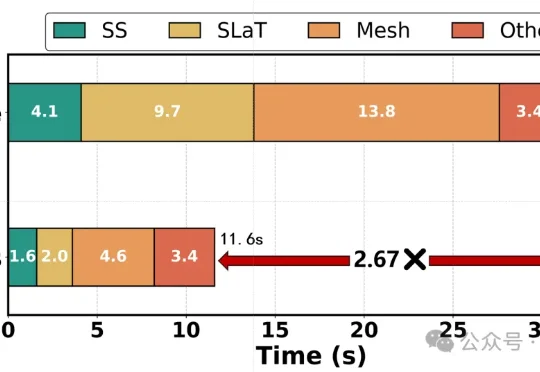
来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
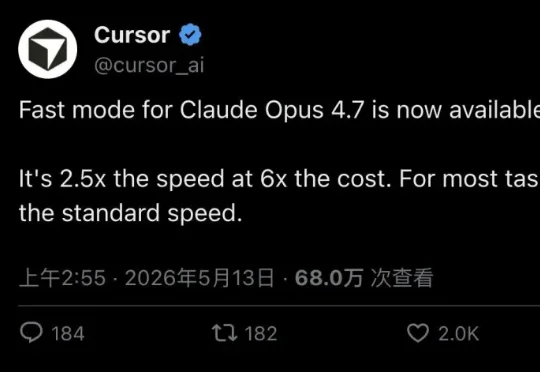
Cursor 正式接入 Claude Opus 4.7 Fast mode——同一个旗舰模型,拆出两个速度档。快 2.5 倍,贵 6 倍,输出价每百万 token 150 美元。最离谱的是,Cursor 官方在发布当天就建议:多数任务请用标准速度。
最近三个月,我用 Claude Code Vibe Coding 了几个项目,非常有意思,写篇文章记录一下。

刚刚,Anthropic神秘王炸Mythos的基准测试泄露了,多项跑分直接刷新纪录!另外,泄露源码中还曝光出卡皮巴拉的细节:代号capabara-v2-fast,支持1M上下文。