PayPal黑帮成员下场重新创业:融资 2000 万美元,要用 AI Agent 干掉 Slack
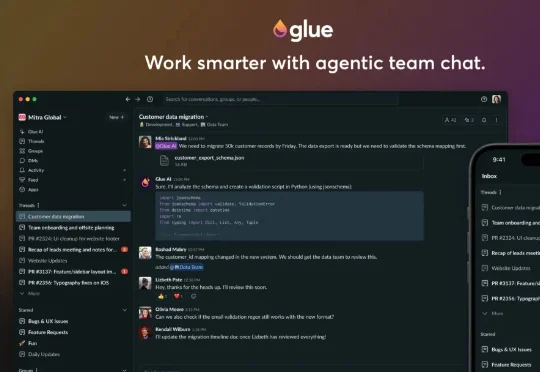
PayPal黑帮成员下场重新创业:融资 2000 万美元,要用 AI Agent 干掉 SlackDavid Sacks 最近带着他的新产品 Glue 正式走向市场,并刚刚完成了 2000 万美元的 A 轮融资。这个名字你可能很熟悉,他是 PayPal 黑帮成员之一,也是 Yammer 的创始人,更是 All-In 播客的联合主持人
来自主题: AI资讯
9559 点击 2025-12-13 11:36