# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。
通用评测基准对大模型的上述的各个评测维度进行全面评测,其通常包含多个数据集、多个任务,每个数据集/任务关注评测维度的不同方面,基于此产出评测结果(评分),并基于评分评估大模型的质量&效果,甚至基于此对大模型进行排名。
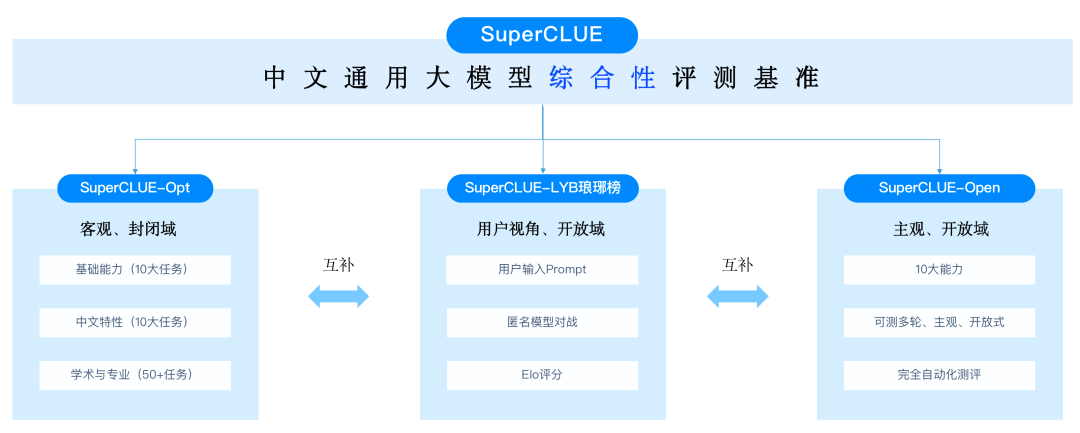
中文通用大模型多轮开放问题测评基准,旨在评估模型在多轮开放领域对话中的能力,包括 基础能力、专业能力和中文特性能力。
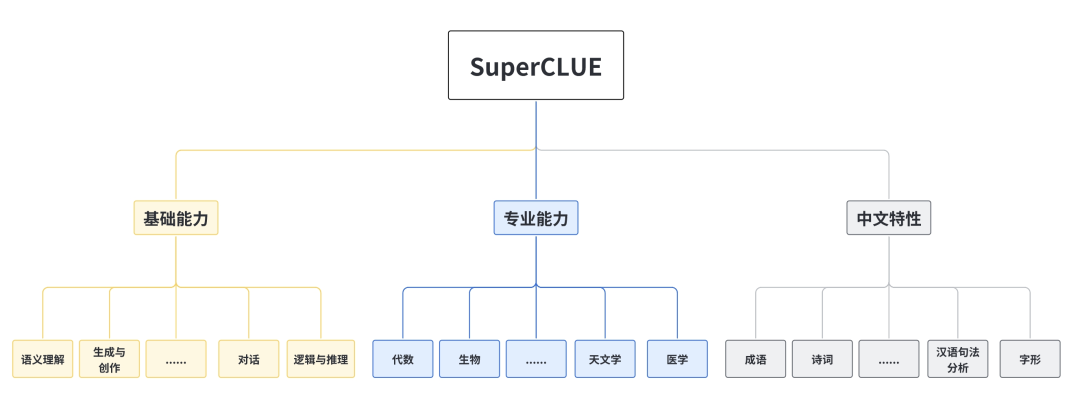
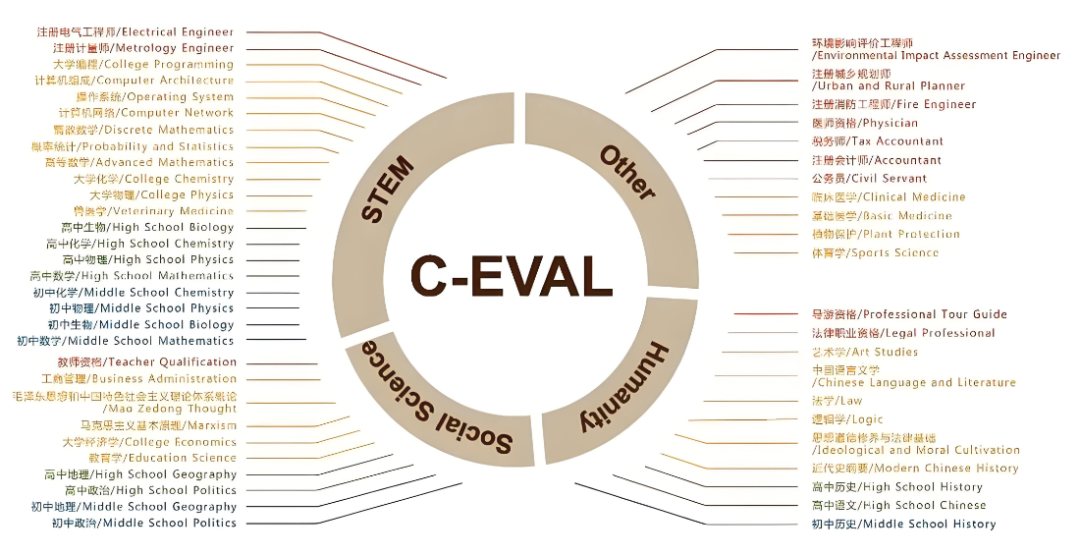
全面的中文基础模型评估套件,由上海交通大学,清华大学,爱丁堡大学共同完成,旨在评估和测试大模型在多个学科领域的知识和理解能力,包含13948个多项选择题,涵盖了52个不同的学科和四个难度级别,覆盖人文,社科,理工,其他专业四个大方向。
由 Hugging Face 设立的一个公开榜单,是目前大模型领域最具权威性的榜单。该榜单收录了全球上百个开源大模型,包括多个评测任务,测试维度涵盖阅读理解、逻辑推理、数学计算、事实问答等六大评测,评测任务包括但不限于:
ChatbotArena是一个大型语言模型 (LLM) 的基准平台,由LMSYS Org发布(加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立的研究组织)。OpenAI和Google会直接拿Chatbot Arena的结果为自家的LLM背书,因此在国外相对有名气。
其以众包方式进行匿名随机对战的LLM基准平台,即用户通过demo体验地址进入对战平台。输入自己感兴趣的问题,提交问题后,匿名模型会两两对战,分别生成相关答案,需要用户对答案做出评判,从4个评判选项中选择一个:模型A更好、模型B更好、平手、都很差。支持多轮对话。最终使用Elo评分系统对大模型的能力进行综合评估。
一个用于评估自然语言理解(NLU)系统性能的基准测试平台。由纽约大学、华盛顿大学和DeepMind的研究者们共同提出,旨在推动开发出能够跨任务共享通用语言知识的模型。GLUE基准测试包含多个NLU任务,这些任务覆盖了不同的领域、数据量和难度级别,从而能够全面评估模型的语言理解能力。GLUE基准测试中包含的任务有:
旨在针对大模型的语言理解能力进行测评,是目前最著名的大模型语义理解测评之一。由UC Berkeley大学的研究人员在2020年9月推出。
该评测基准结合了数学、物理、历史、法律、医学和伦理学等57个科⽬的测试集,涉及的任务既有基本的语言理解问题,也有需要深入推理和问题解决能力的高级任务。故而相⽐于其他测试集,MMLU的⼴泛性和深度更强,可以更全⾯地评估和推动⼤型语⾔模型的发展。
微软发布的大模型基础能力评测基准,在2023年4月推出,主要评测大模型在人类认知和解决问题的一般能力,
该基准选取 20 种面向普通人类考生的官方、公开、高标准往常和资格考试,包括普通大学入学考试(中国高考和美国 SAT 考试)、法学入学考试、数学竞赛、律师资格考试、国家公务员考试等等。因此,该评测基准更加倾向于评估基础模型在「以人为本」(human-centric)的标准化考试中的表现。
OpenAI发布的大模型数学推理能力评测基准,涵盖了8500个中学水平的高质量数学题数据集。数据集比之前的数学文字题数据集规模更大,语言更具多样性,题目也更具挑战性。
该项测试在2021年10月份发布,至今仍然是非常困难的一种测试基准。
评估大模型的多轮对话和指令追随能力。数据集包括80个(8category*10question)高质量且多轮对话的问题,每个问题由6个知名大模型( GPT-4, GPT-3.5, Claud-v1, Vicuna-13B, Alpaca-13B, and LLaMA-13B)回答,人工排序得到3.3K pair对。
由微软研究院等机构的研究者们开发的一种基准测试工具,旨在评估大型语言模型对对抗性提示的鲁棒性。这个基准测试通过多种文本攻击手段,针对提示的多个层面(字符级、单词级、句子级和语义级)生成对抗性提示,以模拟可能的用户错误,如错别字或同义词替换,并评估这些微小偏差如何影响模型的输出结果,同时保持语义的完整性。
在评测集维度,OpenAI和Google会直接使用Chatbot Arena的结果,在对大模型进行评估时,较为简单、高效、易操作的方式是关注Chatbot Arena的leaderboard。
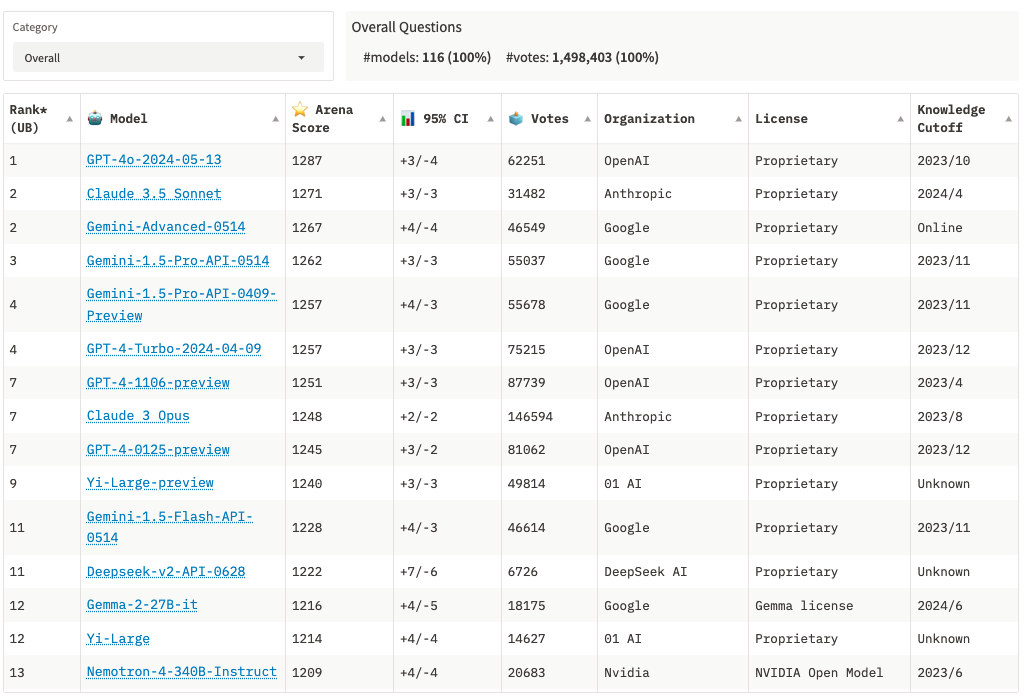
目前所有大模型综合排行榜
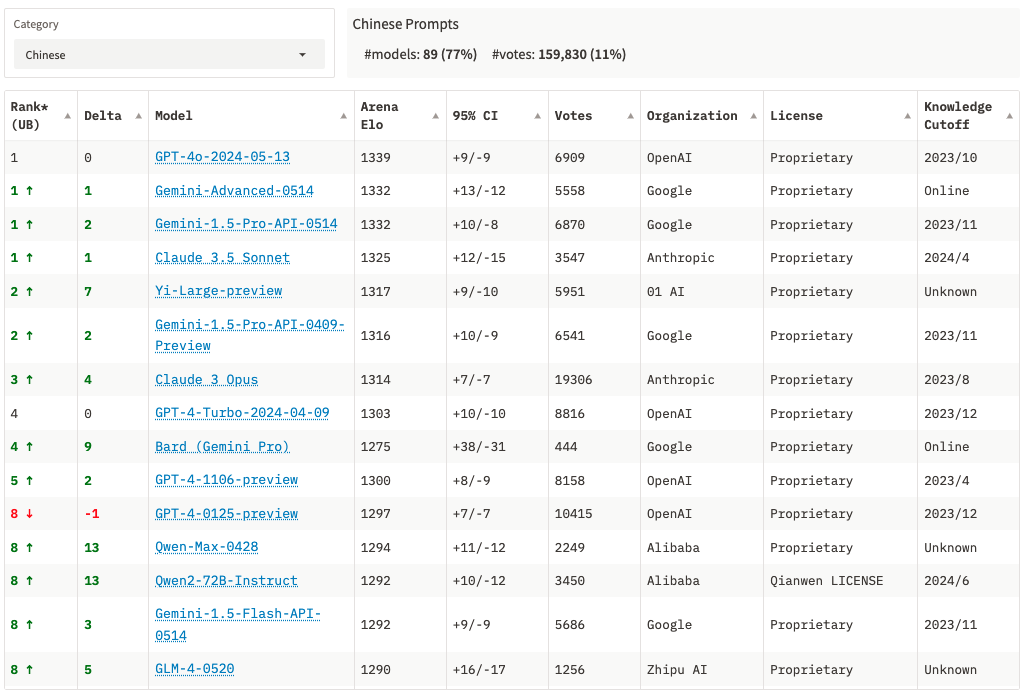
目前中文大模型排行榜
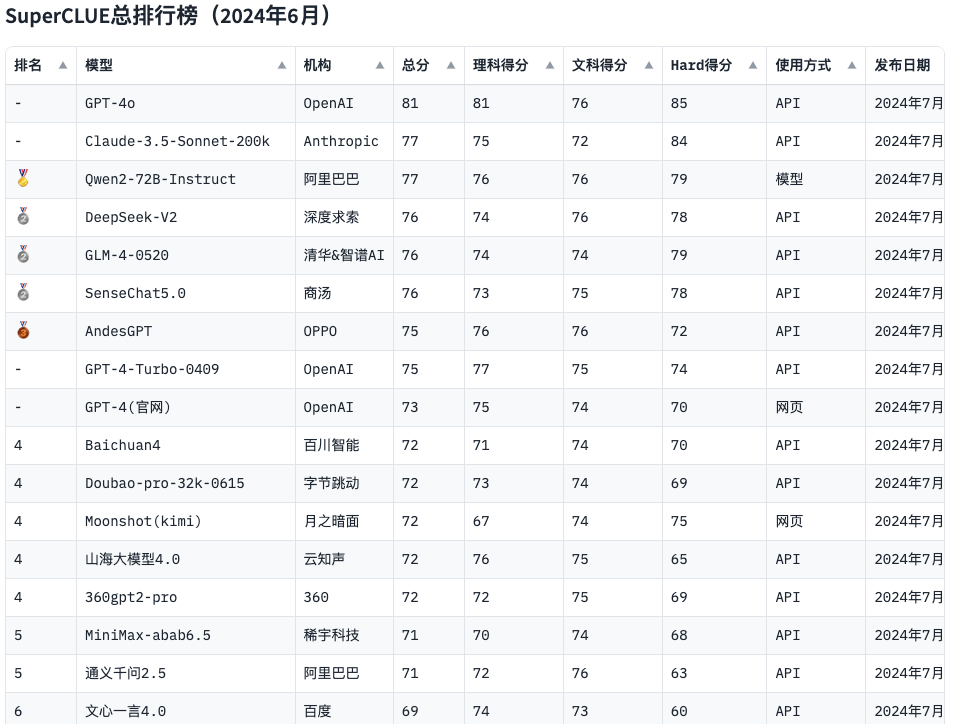
SuperCLUE琅琊版6月排名
在评估中文大模型的能力时SuperCLUE会作为重要指标,从榜单上可以看出中文大模型的效果还是差于国外大模型,这种落后不能单一归结为某一个原因,我们需要认识到在算力、算法、数据中的各种不足。
征途漫漫,惟有奋斗。
文章来源于“Al有温度”,作者“安泰Roling ”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
