登顶SuperCLUE DeepSearch,openPangu-R-72B深度搜索能力跃升
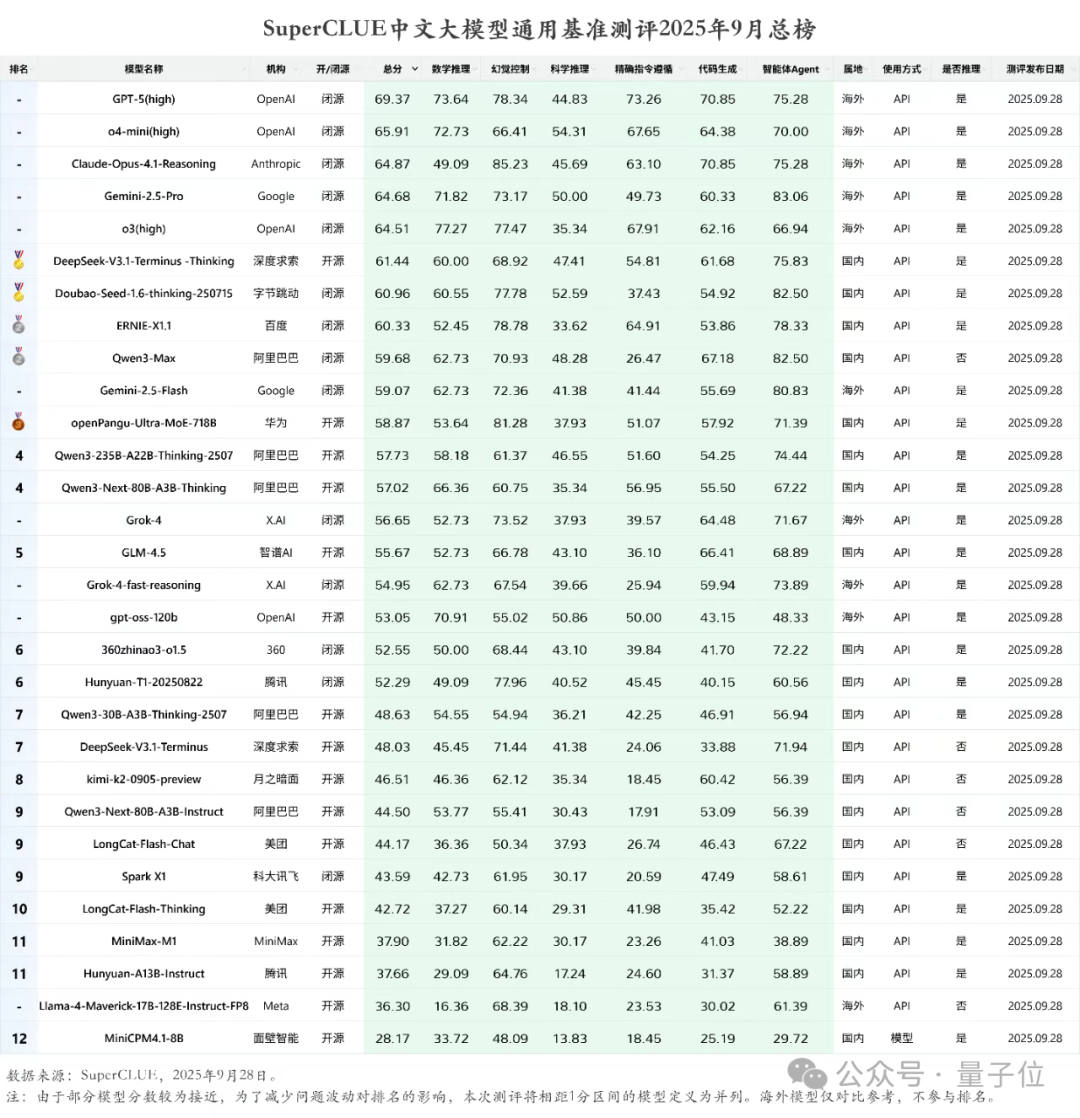
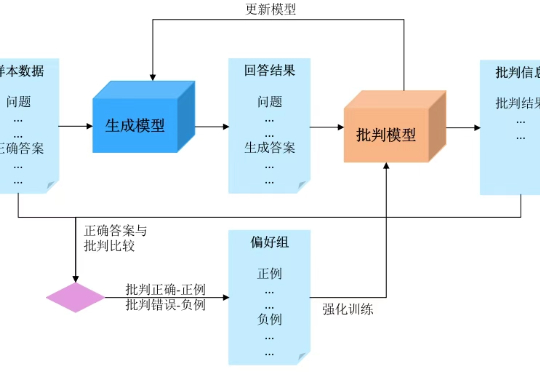
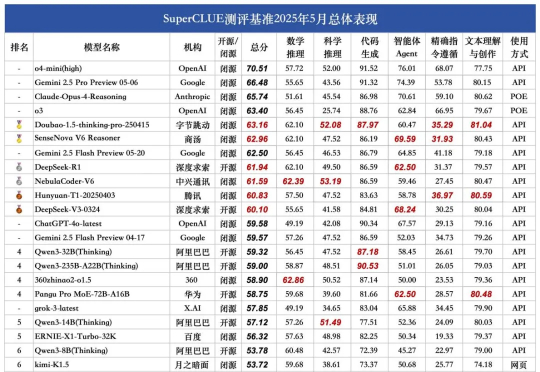
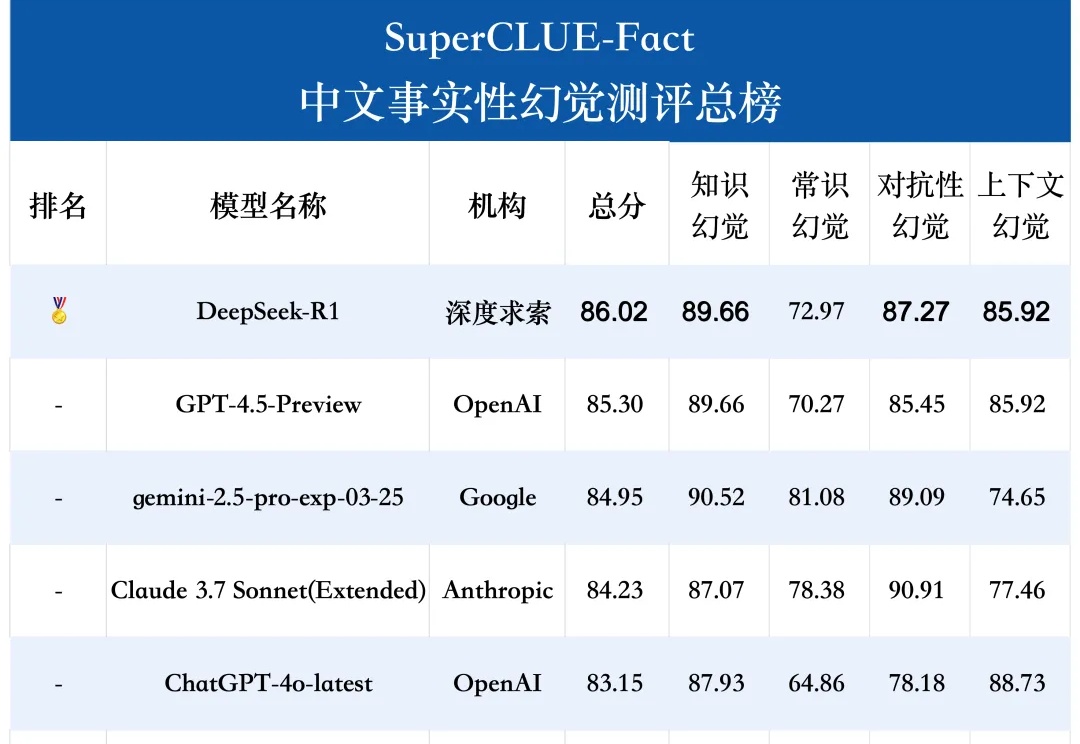
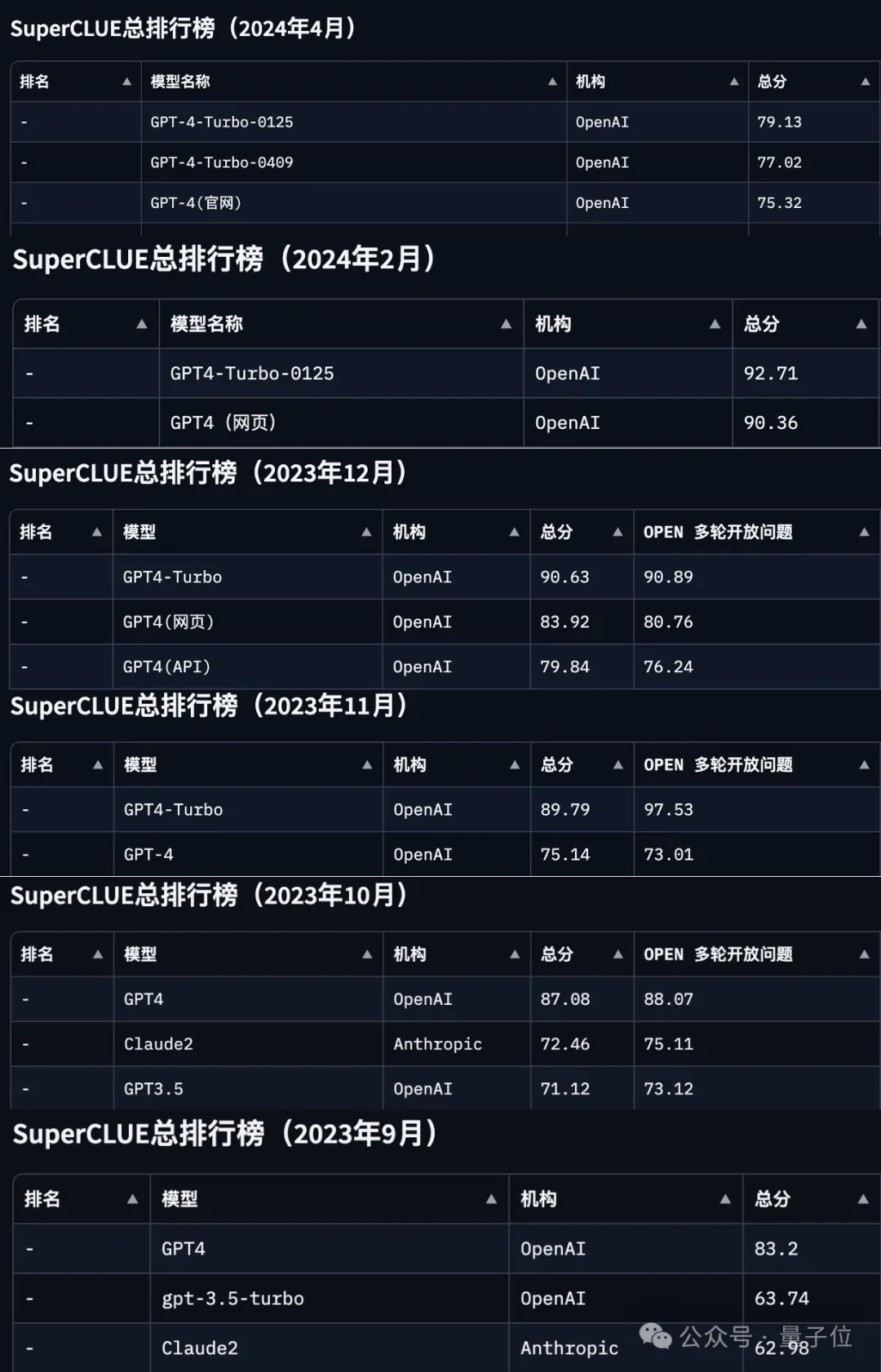
登顶SuperCLUE DeepSearch,openPangu-R-72B深度搜索能力跃升近日,第三方评测机构 SuperCLUE 发布 11 月 DeepSearch 评测报告,国产大模型 openPangu-R-72B 凭借在长链推理、复杂信息检索领域的卓越表现,在模型榜单中名列第一,体现了基于国产昇腾算力的大模型研发实力。
来自主题: AI资讯
9152 点击 2025-12-06 11:23