
愚人节整真活!ChatGPT放开限制,不注册也能玩 | 最前线
愚人节整真活!ChatGPT放开限制,不注册也能玩 | 最前线OpenAI愚人节放大招!当地时间4月1日,OpenAI宣布,将让用户无需注册即可直接使用ChatGPT。
来自主题: AI资讯
7824 点击 2024-04-02 15:43
 搜索
搜索
OpenAI愚人节放大招!当地时间4月1日,OpenAI宣布,将让用户无需注册即可直接使用ChatGPT。
OpenAI狠狠地open了一把就在刚刚,OpenAI狠狠地open了一把:从今天起,ChatGPT打开即用,无需再注册帐号和登录了!

AI 智能体是去年很火的一个话题,但是 AI 智能体到底有多大的潜力,很多人可能没有概念。 最近,斯坦福大学教授吴恩达在演讲中提到,他们发现,基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。当然,基于 GPT-4 构建的智能体工作流效果更好。由此看来,AI 智能体工作流将在今年推动人工智能取得巨大进步,甚至可能超过下一代基础模型。这是一个值得所有人关注的趋势。

什么?谷歌成功偷家OpenAI,还窃取到了gpt-3.5-turbo关键信息???
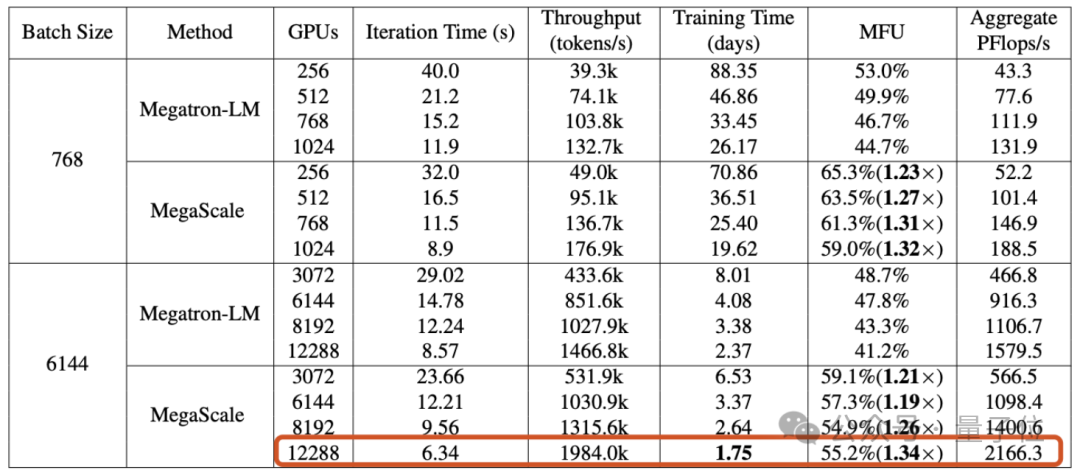
随着对Sora技术分析的展开,AI基础设施的重要性愈发凸显。
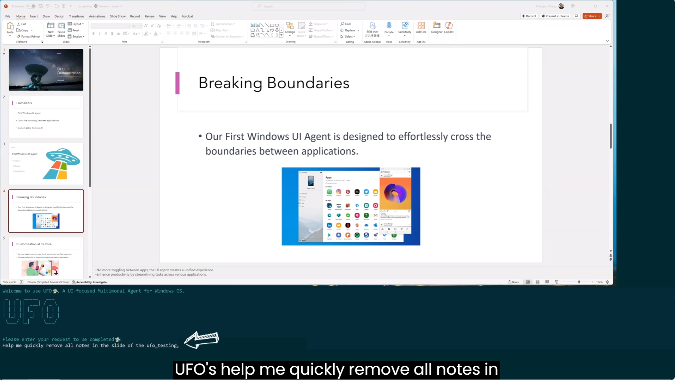
微软首个为Windows而设的智能体(Agent) 亮相:基于GPT-4V,一句话就可以在多个应用中无缝切换,完成复杂任务。整个过程无需人为干预,其执行成功率和效率是GPT-4的两倍,GPT-3.5的四倍。
该团队的新模型在多个基准测试中都与 Gemini Pro 、GPT-3.5 相媲美。
MoE(混合专家)作为当下最顶尖、最前沿的大模型技术方向,MoE能在不增加推理成本的前提下,为大模型带来性能激增。比如,在MoE的加持之下,GPT-4带来的用户体验较之GPT-3.5有着革命性的飞升。

2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。

全新GPT-4 Turbo预览模型据介绍,该模型能更完整彻底地完成代码生成等任务,以减少模型未完成任务的“惰性”情况。