

因为GPT-5,这群人决定在Reddit上起义。
因为GPT-5,这群人决定在Reddit上起义。这个周末,对OpenAI的抗诉,好像从未如此热闹过。 起因自然还是因为GPT-5。 OpenAI上了GPT-5当天,做了一个非常神奇的操作,他们只保留了GPT-5,然后把GPT-4.5、GPT-4o、o3什么的,全都砍掉了。
来自主题: AI资讯
9049 点击 2025-08-11 11:51
这个周末,对OpenAI的抗诉,好像从未如此热闹过。 起因自然还是因为GPT-5。 OpenAI上了GPT-5当天,做了一个非常神奇的操作,他们只保留了GPT-5,然后把GPT-4.5、GPT-4o、o3什么的,全都砍掉了。

谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
在全球 AI 人才争夺战愈演愈烈的今天,许多技术人却不得不面对一种无力的现实。最近,OpenAI 的一位核心研究员 Kai Chen,因绿卡申请被拒,不得不离开美国,这一消息在科技圈引发了广泛关注。
近日,GPT-4.5核心开发者之一的Kai Chen因绿卡申请被拒,面临被迫离开美国的困境。与此同时,1700多名国际学生和研究人员因签证审查受阻,Nature调查显示75%的美国科学家正考虑逃离。这种人才流失或将影响美国在全球AI领域的领先地位。
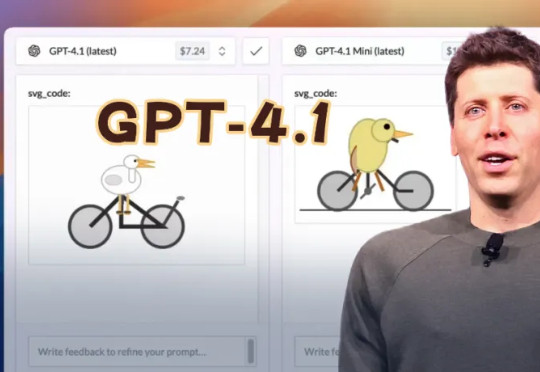
两个月后就号称要淘汰GPT-4.5的GPT-4.1,实力究竟如何?在众多实测中,它的表现的确可圈可点,但却依然打不过Gemini 2.5 Pro和Claude 3.7 Sonnet。那么问题来了,OpenAI为何要发布一个远远落后于谷歌的模型?

今天凌晨,OpenAI 发布了新模型 GPT-4.1,相对比 4o,GPT-4.1 在编程和指令遵循方面的能力显著提升,同时还宣布 GPT-4.5 将会在几个月后下线。不少人吐槽 OpenAI 让人迷惑的产品发布逻辑——GPT-4.1 晚于 4.5 发布,以及混乱的模型命名,这些问题,都能在 OpenAI CPO Kevin Weil 最近的一期播客访谈中得到解答。

OpenAI重磅发布的GPT-4.1系列模型,带来了编程、指令跟随和长上下文处理能力的全面飞跃!由中科大校友Jiahui Yu领衔的团队打造。与此同时,备受争议的GPT-4.5将在三个月后停用,GPT-4.1 nano则以最小、最快、最便宜的姿态强势登场。
GPT-4.5比GPT-4聪明10倍!其背后的研发故事却鲜为人知。奥特曼携OpenAI团队首次敞开心扉,分享了幕后细节。从海量算力引发的「基础设施危机」,到「torch.sum bug」带来的意外突破,团队讲述了在挑战中实现智能飞跃。