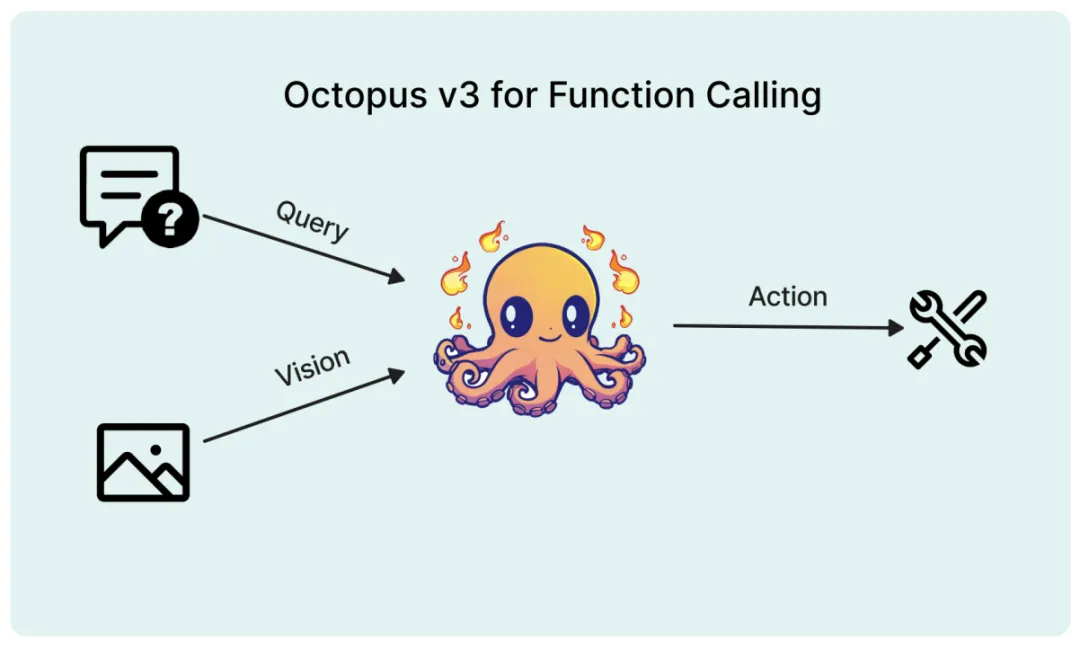
参数量不到10亿的OctopusV3,如何媲美GPT-4V和GPT-4?
参数量不到10亿的OctopusV3,如何媲美GPT-4V和GPT-4?多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。
来自主题: AI技术研报
10232 点击 2024-05-01 19:35
 搜索
搜索
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。

自从 2023 年 11 月 Grok 首次亮相以来,马斯克的 xAI 正在大模型领域不断取得进步,向 OpenAI 等先行者发起进攻。在 Grok-1 开源后不到一个月,xAI 的首个多模态模型就问世了。

大语言模型的效率,正在被这家「清华系」创业公司发展到新高度。

一句话Siri就能帮忙打开美团外卖下订单的日子看来不远啦!

GPT-4V 的推出引爆了多模态大模型的研究。GPT-4V 在包括多模态问答、推理、交互在内的多个领域都展现了出色的能力,成为如今最领先的多模态大模型。
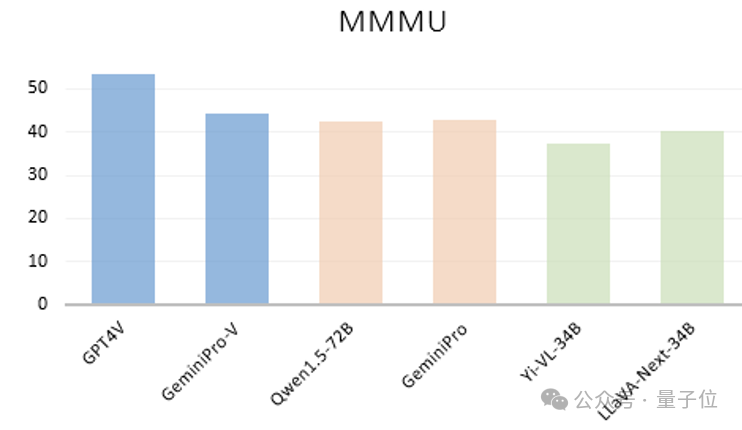
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。
国产大模型独角兽送福利来了,千万token免费用!最近,零一万物API正式开放,三款模型都非常能打,开发者们赶快来开箱吧。零一万物API开放平台,正式向开发者开放了!

我们接连被谷歌的多模态模型 Gemini 1.5 以及 OpenAI 的视频生成模型 Sora 所震撼到,前者可以处理的上下文窗口达百万级别,而后者生成的视频能够理解运动中的物理世界,被很多人称为「世界模型」。
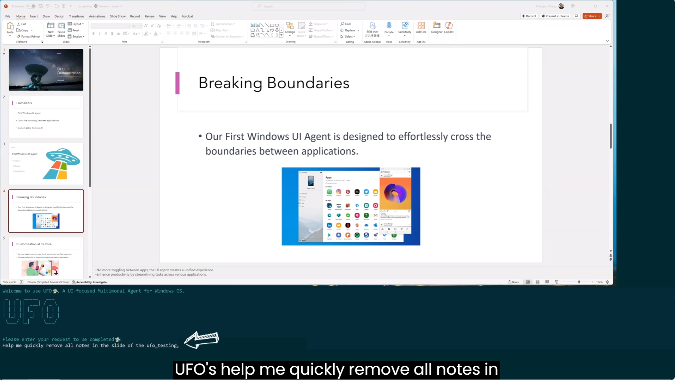
微软首个为Windows而设的智能体(Agent) 亮相:基于GPT-4V,一句话就可以在多个应用中无缝切换,完成复杂任务。整个过程无需人为干预,其执行成功率和效率是GPT-4的两倍,GPT-3.5的四倍。

华中科技大学联合华南理工大学、北京科技大学等机构的研究人员对14个主流多模态大模型进行了全面测评,涵盖5个任务,27个数据集。