# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。
在最近的一篇论文中,研究者提出了一种专为 AI 应用设计的多模态模型,引入了「functional token」的概念。
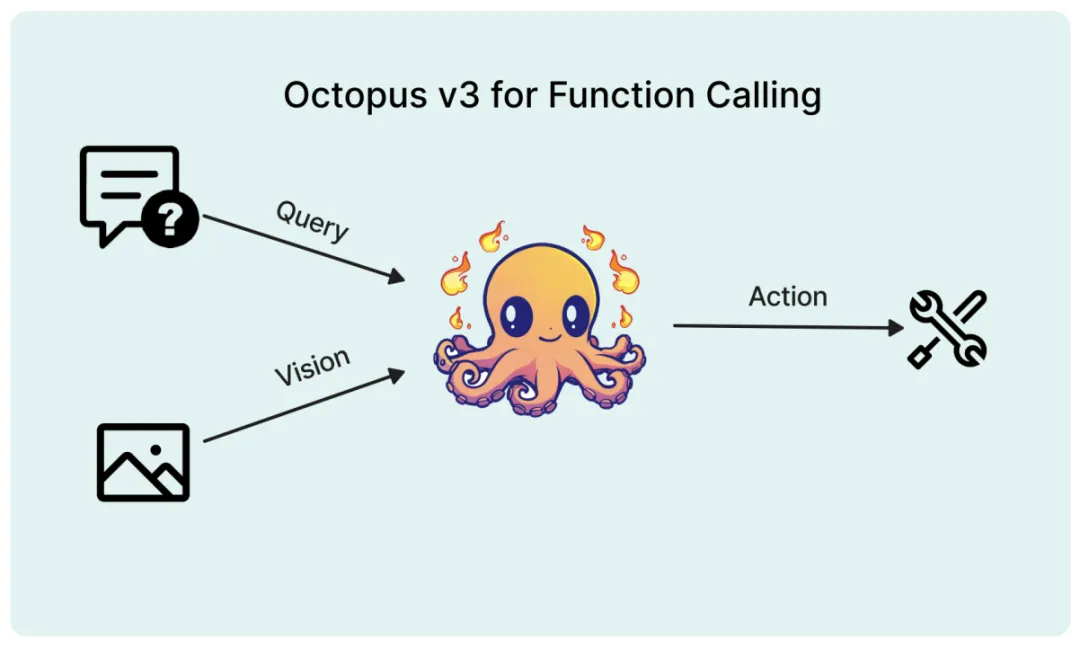
为确保该模型能兼容边缘设备,研究者将其参数量优化至 10 亿以内。与 GPT-4 类似,该模型能同时处理英文和中文。实验表明,该模型能在包括树莓派等各类资源受限的终端设备上高效运行。
人工智能技术的飞速发展彻底改变了人机交互的方式,催生出一批能够根据自然语言 \ 视觉等多种形式的输入执行复杂任务、做出决策的智能 AI 系统。这些系统有望实现从图像识别、语言翻译等简单任务到医疗诊断、自动驾驶等复杂应用的自动化。多模态语言模型是这些智能系统的核心,使其能够通过处理整合文本、图像乃至音视频等多模态数据,理解和生成近乎人类的回复。相较于主要关注文本处理和生成的传统语言模型,多模态语言模型是一大飞跃。通过纳入视觉信息,这些模型能够更好地理解输入数据的语境和语义,从而给出更加准确、相关的输出。例如,一个在图文匹配数据上训练的多模态语言模型,相比单纯的文本模型,能够为新图生成更具描述性、更符合上下文的文字说明。处理和整合多模态数据的能力,对于开发多模态 AI 系统至关重要,使其能完成需要同时理解语言和视觉信息的任务,如视觉问答、图像导航、多模态情感分析等。
开发多模态语言模型的一大挑战在于,如何将视觉信息有效地编码为模型可处理的格式。这通常借助卷积神经网络 (CNN) 或 transformer 等架构来实现,如视觉 transformer (ViT) 。CNN 凭借从图像中提取层次化特征的能力,在计算机视觉任务中得到广泛应用,使模型能够学习到输入数据越来越复杂的表示。另一方面,ViT 等基于 transformer 的架构由于能捕捉长距离依赖、建模全局上下文,在理解图像中物体间关系方面优势突出,近年来备受青睐。这些架构使模型能够从输入图像中提取有意义的特征,并将其转化为可与文本输入整合的向量表示。
编码视觉信息的另一种方法是图像符号化 (tokenization), 即将图像分割为更小的离散单元或 token。这种方法让模型能以类似处理文本的方式来处理图像,实现两种模态的更无缝融合。图像 token 信息可与文本输入一同送入模型,使其能同时关注两种模态并生成更准确、更契合上下文的输出。例如,OpenAI 开发的 DALL-E 模型采用 VQ-VAE (向量量化变分自编码器) 的变体对图像做符号化,使模型能根据文本描述生成新颖图像。开发出能够根据用户提供的查询和图像采取行动的小型高效模型,对 AI 系统的未来发展影响深远。这些模型可部署于智能手机、物联网设备等资源受限的设备上,扩大其应用范围和场景。借助多模态语言模型的威力,这些小型系统能以更自然、直观的方式理解和回应用户的问询,同时考虑用户提供的视觉语境。这为实现更具吸引力、个性化的人机互动开启了可能,如根据用户喜好提供视觉推荐的虚拟助手,或根据用户面部表情调节设置的智能家居设备。
此外,多模态 AI 系统的发展有望实现人工智能技术的民主化,让更广泛的用户和行业受益。更小巧高效的模型可在算力较弱的硬件上训练,降低部署所需的计算资源和能耗。这可能带来 AI 系统在医疗、教育、娱乐、电商等各个领域的广泛应用,最终改变人们的生活和工作方式。
多模态模型由于能够处理和学习文本、图像、音频等多种数据类型而备受关注。这类模型能捕捉不同模态间复杂的交互,并利用它们的互补信息来提升各类任务的性能。视觉 - 语言预训练 (VLP) 模型如 ViLBERT、LXMERT、VisualBERT 等,通过跨模态注意力学习视觉和文本特征的对齐,生成丰富的多模态表征。多模态 transformer 架构如 MMT、ViLT 等则对 transformer 做了改进,以高效处理多种模态。研究者还尝试将音频、面部表情等其他模态纳入模型,如多模态情感分析 (MSA) 模型、多模态情绪识别 (MER) 模型等。通过利用不同模态的互补信息,多模态模型相比单模态方法取得了更优的性能和泛化能力。
终端语言模型定义为参数量少于 70 亿的模型,因为研究者发现即使采用量化,在边缘设备上运行 130 亿参数的模型也非常困难。这一领域近期的进展包括 Google 的 Gemma 2B 和 7B、Stable Diffusion 的 Stable Code 3B 以及 Meta 的 Llama 7B。有趣的是,Meta 的研究表明,与大型语言模型不同,小型语言模型采用深而窄的架构会有更好的表现。其他对终端模型有益的技术还包括 MobileLLM 中提出的 embedding 共享、分组 query 注意力以及即时分块权重共享等。这些发现凸显了在开发终端应用的小型语言模型时,需要考虑不同于大模型的优化方法和设计策略。
Octopus v3 模型开发中采用的主要技术。多模态模型开发的两个关键方面是:将图像信息与文本输入相整合,以及优化模型预测动作的能力。
视觉信息编码
图像处理中存在多种视觉信息编码方法,常用隐藏层的 embedding。例如,VGG-16 模型的隐藏层 embedding 被用于风格迁移任务。OpenAI 的 CLIP 模型展示了对齐文本和图像 embedding 的能力,利用其图像编码器来嵌入图像。ViT 等方法则采用了图像 tokenization 等更先进的技术。研究者评估了多种图像编码技术,发现 CLIP 模型的方法最为有效。因此,本文采用基于 CLIP 的模型进行图像编码。
Functional token
与应用于自然语言和图像的 tokenization 类似,特定 function 也可封装为 functional token。研究者为这些 token 引入了一种训练策略,借鉴了自然语言模型处理未见词的技术。这一方法与 word2vec 类似,通过 token 的上下文环境来丰富其语义。例如,高级语言模型最初可能难以应对 PEGylation 和 Endosomal Escape 等复杂化学术语。但通过因果语言建模,尤其是在包含这些术语的数据集上训练,模型能够习得这些术语。类似地,functional token 也可通过并行策略习得,其中 Octopus v2 模型可为此类学习过程提供强大的平台。研究表明,functional token 的定义空间是无限的,从而能够将任意特定 function 表示为 token。
多阶段训练
为开发出高性能的多模态 AI 系统,研究者采用了集成因果语言模型和图像编码器的模型架构。该模型的训练过程分为多个阶段。首先,因果语言模型和图像编码器分别训练,建立基础模型。随后,将这两个部件合并,并进行对齐训练以同步图像和文本处理能力。在此基础上,借鉴 Octopus v2 的方法来促进 functional token 的学习。最后一个训练阶段中,这些能够与环境交互的 functional token 提供反馈,用于进一步优化模型。因此,最后阶段研究者采用强化学习,并选择另一个大型语言模型作为奖励模型。这种迭代训练方式增强了模型处理和整合多模态信息的能力。
本节介绍模型的实验结果,并与集成 GPT-4V 和 GPT-4 模型的效果进行对比。在对比实验中,研究者首先采用 GPT-4V (gpt-4-turbo) 处理图像信息。然后将提取的数据输入 GPT-4 框架 (gpt-4-turbo-preview), 将所有 function 描述纳入上下文并应用小样本学习以提升性能。在演示中,研究者将 10 个常用的智能手机 API 转化为 functional token 并评估其表现,详见后续小节。
值得注意的是,虽然本文仅展示了 10 个 functional token, 但该模型可以训练更多 token 以创建更通用的 AI 系统。研究者发现,对于选定的 API, 参数量不到 10 亿的模型作为多模态 AI 表现可与 GPT-4V 和 GPT-4 的组合相媲美。
此外,本文模型的可扩展性允许纳入广泛的 functional token, 从而能够打造高度专业化的 AI 系统,适用于特定领域或场景。这种适应性使本文方法在医疗、金融、客户服务等行业尤为有价值,这些领域中 AI 驱动的解决方案可显著提升效率和用户体验。
在下面的所有 function 名称中,Octopus 仅输出 functional token 如 < nexa_0>,...,<nexa_N>, 研究者将 functional token 替换为相应的函数名称以便更好地演示。以下所有结果都是直接生成的,无需任何输出解析器。Octopus v3 是一个单一模型,可同时处理中文和英文,这意味着无需专门训练另一个中文模型。
发送邮件

发送短信

Google 搜索

亚马逊购物

智能回收

失物招领

室内设计

Instacart 购物

DoorDash 外卖

宠物护理

在 Octopus v2 的基础上,更新后的模型纳入了文本和视觉信息,从其前身纯文本方法迈出了重要一步。这一显著进展实现了视觉和自然语言数据的同步处理,为更广泛的应用铺平了道路。Octopus v2 引入的 functional token 可适应多个领域,如医疗和汽车行业。随着视觉数据的加入,functional token 的潜力进一步扩展到自动驾驶、机器人等领域。此外,本文的多模态模型让树莓派等设备实际转化为 Rabbit R1 、Humane AI Pin 之类的智能硬件成为可能,它采用终端模型而非基于云的方案。
Functional token 目前已获得授权,研究者鼓励开发者参与本文框架,在遵守许可协议的前提下自由创新。在未来的研究中,研究者旨在开发一个能够容纳音频、视频等额外数据模态的训练框架。此外,研究者发现视觉输入可能带来相当大的延迟,目前正在优化推理速度。
本文来自微信公众号“机器之心”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
