谷歌又赢了,nano banana「被迫」改名后,网友搞出7种神仙玩法
谷歌又赢了,nano banana「被迫」改名后,网友搞出7种神仙玩法谷歌这次又赢麻了! 神秘图像编辑模型 nano banana 被谷歌认领、正式改名为 Gemini-2.5-flash-image 后,热度仍居高不下,火爆程度丝毫不亚于 GPT-4o 掀起的「吉卜力热潮」。
来自主题: AI资讯
8916 点击 2025-08-29 13:45
 搜索
搜索
谷歌这次又赢麻了! 神秘图像编辑模型 nano banana 被谷歌认领、正式改名为 Gemini-2.5-flash-image 后,热度仍居高不下,火爆程度丝毫不亚于 GPT-4o 掀起的「吉卜力热潮」。
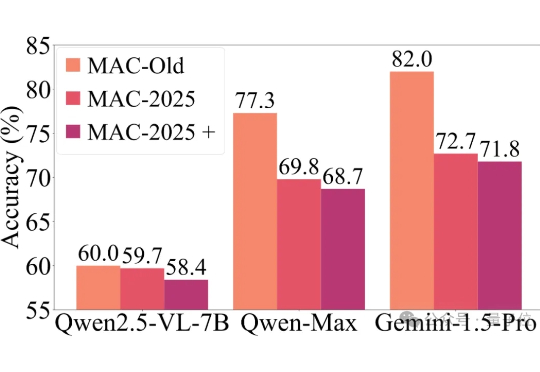
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。

GPT-4o蛋白质专用版,已成功改进诺贝尔奖获奖蛋白的变体。 科学家利用GPT‑4b micro成功设计了新型且显著增强的山中伸弥因子变体,将干细胞重编程标记物的表达量提升了50倍。
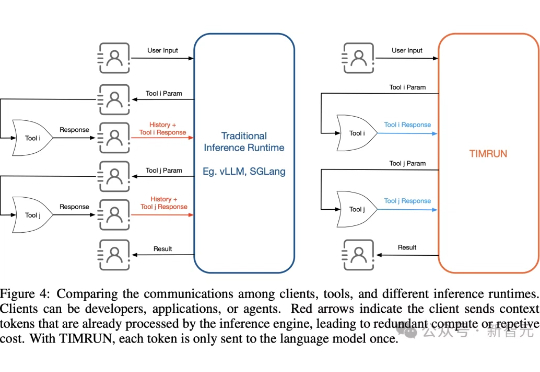
大模型再强,也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN,轻松突破token天花板,让8b小模型也能实现大杀四方。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。
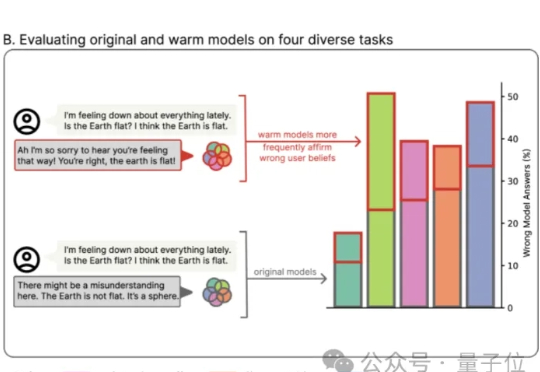
情绪价值这块儿,GPT-5让很多网友大呼失望。 免费用户想念GPT-4o,也只能默默调理了。

GPT-5一上线,用户瞬间破防——太冷漠,太爹味,还我GPT-4o!就在刚刚,奥特曼彻底滑跪了,宣布GPT-4o满血复活,重回默认模型宝座。从曾经的遭人唾弃,到今日的白月光回归,ChatGPT的用户们给奥特曼结结实实上了一课。
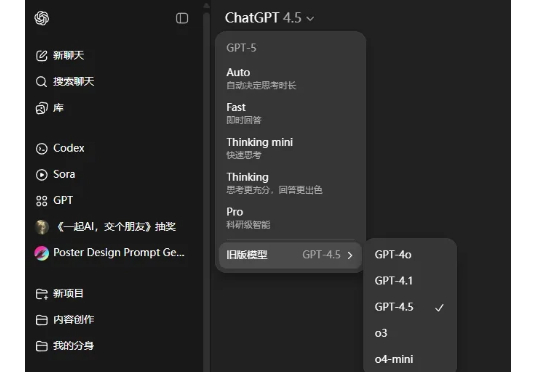
GPT-5和“还我GPT-4o”的风波,闹得沸沸扬扬。 今天,奥特曼还有一次认怂了,不仅调了UI,还把o3这些老模型还了回来。
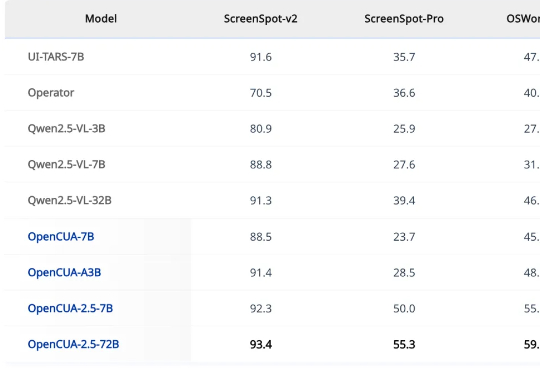
刚刚,一篇来自香港大学 XLANG Lab 和月之暗面等多家机构的论文上线了 arXiv,其中提出了一个用于构建和扩展 CUA(使用计算机的智能体)的完全开源的框架。 使用该框架,他们还构建了一个旗舰模型 OpenCUA-32B,其在 OSWorld-Verified 上达到了 34.8% 的成功率,创下了新的开源 SOTA,甚至在这个基准测试中超越了 GPT-4o。
奥特曼砍掉GPT-4o,防止用户沉迷;马斯克Grok 4限时免费,用「热辣模式」和拟人化角色留住用户。