
中科大团队放大招:8B小模型碾压GPT-5.2和Claude,Agent工具调用的「基建革命」来了!
中科大团队放大招:8B小模型碾压GPT-5.2和Claude,Agent工具调用的「基建革命」来了!先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
来自主题: AI资讯
10917 点击 2026-04-22 09:12
 搜索
搜索
先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
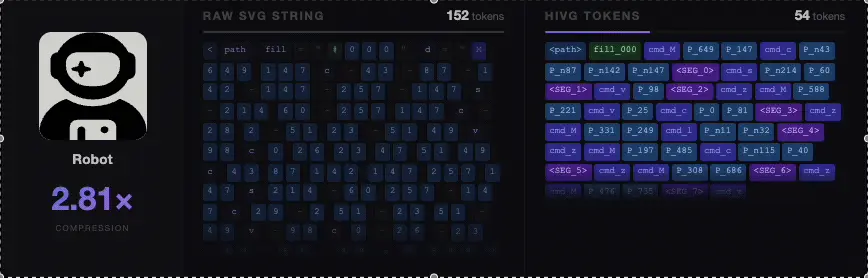
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。
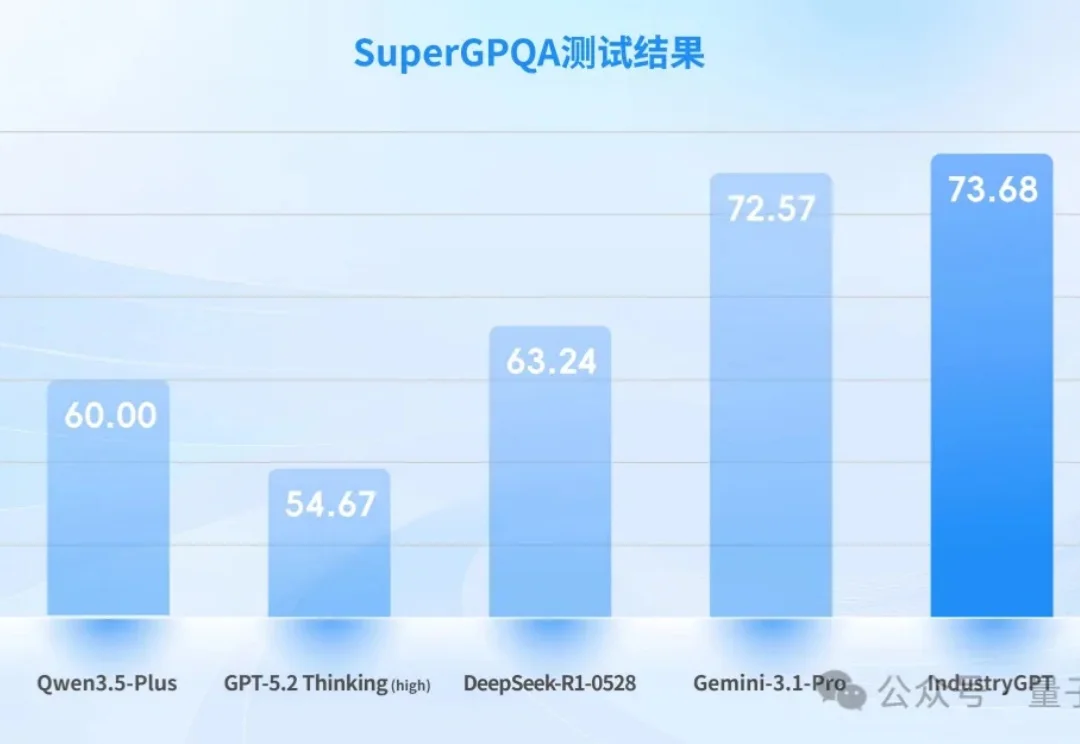
最近,一批顶级通用大模型参加了三场特殊的“工业执业考试”。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
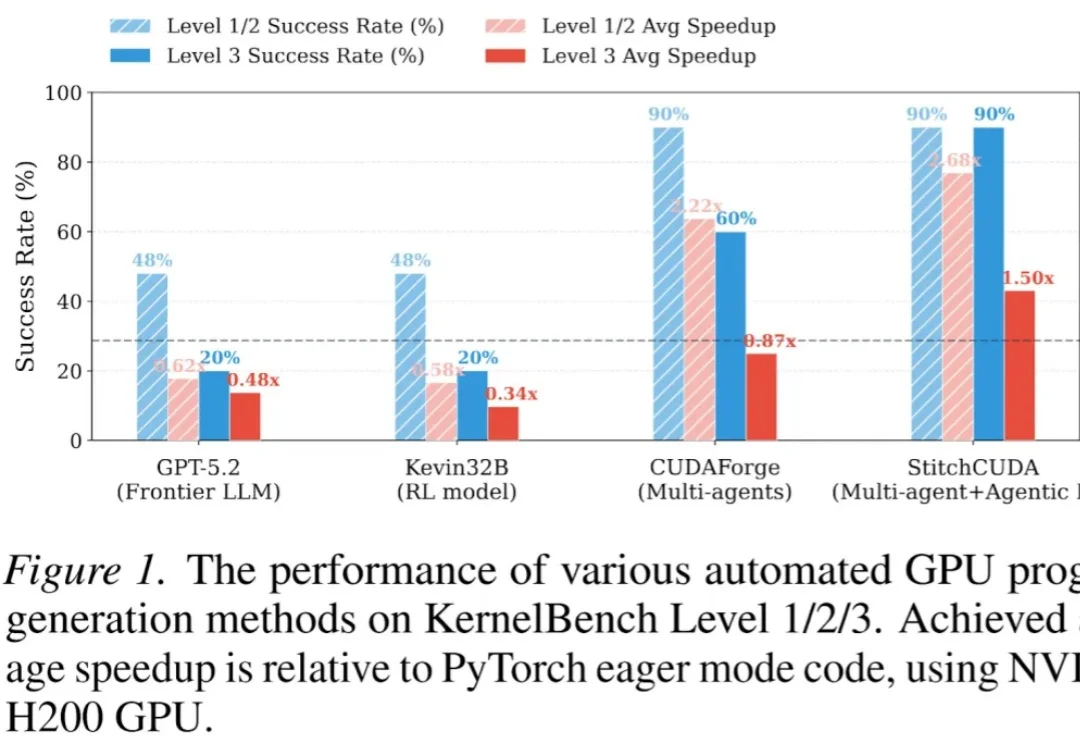
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
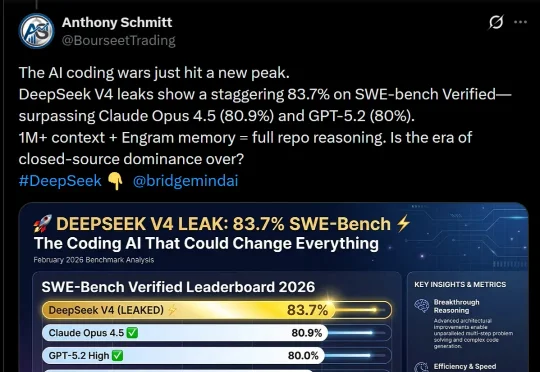
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!

粒子物理教科书几十年的结论被推翻,GPT-5.2干的。这已经是GPT-5.2在基础科学领域做出原创贡献的第三个公开案例。 此前GPT-5独立证明了一道存在45年的埃尔德什数论猜想,还在非线性量子力学与相对论兼容性的理论物理论文中提出了核心方法论框架。
ChatGPT 最近明显又有点焦虑。
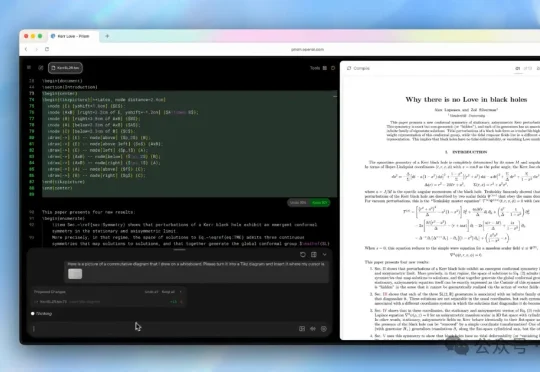
就在今天,OpenAI给肝论文的科研党送上了一份大礼——免费的科研写作平台Prism。 它把GPT-5.2模型深度集成到了在线LaTeX编辑器中,能够直接理解论文的完整结构、公式推导与参考文献。

深夜,OpenAI正式祭出新一代科研利器——Prism,由GPT-5.2加持,专为写作和协作而生。它是一个基于云的「AI原生」LaTeX工作区,不限项目和协作的人数。