
我看错了Anthropic!骂了大半年,马斯克突然改口
我看错了Anthropic!骂了大半年,马斯克突然改口几个月前,马斯克还骂Anthropic「邪恶」,断言它「不可能赢」,如今突然改口称它是「当前AI最强」。 手握22万块GPU的他,为何没有趁机断供对手?
来自主题: AI资讯
7975 点击 2026-07-13 09:42
 搜索
搜索
几个月前,马斯克还骂Anthropic「邪恶」,断言它「不可能赢」,如今突然改口称它是「当前AI最强」。 手握22万块GPU的他,为何没有趁机断供对手?

就在这届Bilibili World上,英伟达首次面向大众玩家展示了搭载RTX Spark超级芯片的笔记本电脑。这款芯片专为个人智能体打造,不仅搭载了Blackwell RTX GPU,连CPU也是出自英伟达的Grace CPU。

37.7°C,干趴了一台国家级AI超算。6月底,英国遭遇有记录以来最热的六月。剑桥大学的Dawn——全英最快的AI超算之一——冷却系统当场热瘫,上千块GPU被迫休了一周多的高温假,350多个科研项目全线急刹。
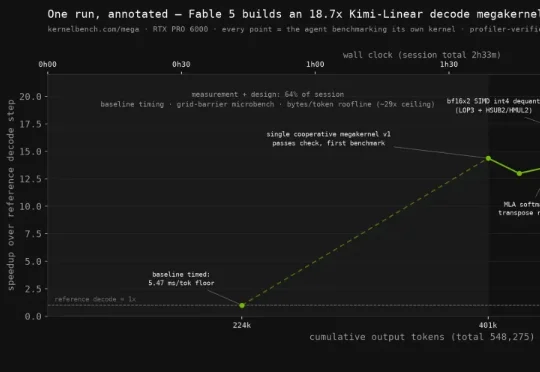
AI竟写出了,史上最快内核!在全新一轮GPU算子基准测试KernelBench-Mega中,Fable 5表现一骑绝尘。它在RTX PRO 6000,全程「纯手搓」CUDA,速度狂飙18.7倍。相比之下,强如Claude Opus 4.8也只跑出14.4倍,而GPT-5.5只有4.34倍。

AI 时代,面临传统电网和可再生能源的压力,科技巨头们争夺的资源已不仅仅是 GPU,而是稳定、低价、全天候不断电的清洁能源。现在,解决方案或许又多了一个新的选择。近日,美国核能初创公司 Ampera 称,已基于 3D 打印完成全球首个全尺寸核反应堆模块,旨在为 AI 数据中心、国防应用、工业设施和偏远地区等提供清洁电力。

AI新云赛道再现巨额融资。成立于2022年的AI新云(Neocloud)公司Together AI,于7月1日正式宣布完成8亿美元C轮融资,投后估值达到83亿美元。Together AI的核心业务是出租NVIDIA GPU集群及其他AI专用基础设施,为企业提供运行开源大模型的云平台。

刚刚,阿里达摩院联合中国人民大学高瓴人工智能学院、中国科学院大学等机构,发布了首个专攻超导材料发现的AI智能体“ElementsClaw”(元素虾)。只用了28个GPU小时,ElementsClaw就给已知的240万种稳定晶体统统海选了一遍,预测其中的6.8万种可能是超导体。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。
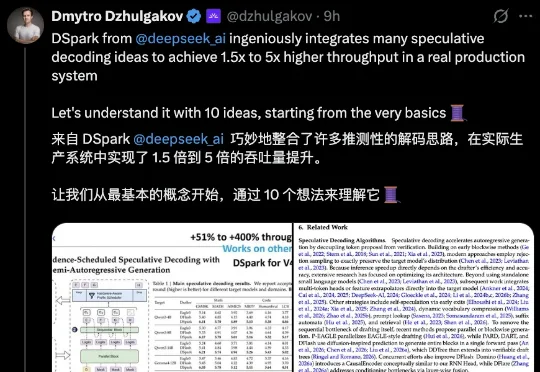
Fireworks AI的联合创始人兼CTO、PyTorch核心维护者Dmytro Dzhulgakov将整篇论文梳理成了10个概念,从最底层的GPU访存特性讲到最上层的在线自适应调度。DeepSeek这套方案真正的精髓在于系统工程和模型协同设计。
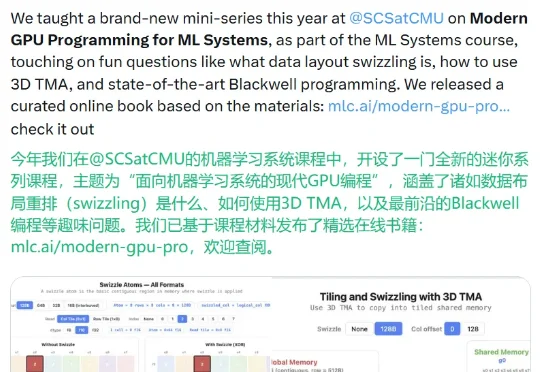
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。