
零GPU,世界第一超算!深圳制造改写游戏规则了
零GPU,世界第一超算!深圳制造改写游戏规则了全球最强超算,易主了!
来自主题: AI资讯
9535 点击 2026-06-24 16:35
 搜索
搜索
全球最强超算,易主了!

6月15日,燧原科技科创板IPO获上交所上市委审议通过。至此,"国产GPU四小龙"即将全部上岸——摩尔线程、沐曦股份早在2025年12月就登陆科创板,市值一度冲到4400亿;壁仞科技今年1月在港股上市,市值超1300亿港元。

刚刚被 SpaceX 宣布以 600 亿美元收购的 Cursor,发布大模型了。本周二,Cursor 宣布了一个新的 1.5 万亿 + 参数模型,该模型在超过 10 万块 GPU 上进行了预训练。消息是在旧金山举行的 Cursor Compile 上宣布的,这是 Cursor 举办的首届旗舰大会。
国产算力生态的难题,从此有了 AI 解。

近日,专注低功耗AI模型的初创公司Flourish Inc. 完成5亿美元融资。本次融资由GV、Lux Capital、Catalio Capital Management等知名投资机构及杰夫·贝索斯参与投资。本轮融资亦是2026年6月初全球规模最大的融资轮次之一。

最近的B300市场可以说是“冰火两重天”——群里叫卖得火热,实际成交却降至冰点。老美的出口管制如同悬在头顶的达摩克利斯之剑,彻底改变了顶级算力芯片的流通逻辑。 以下是基于近期一线实操、买卖双方博弈以及
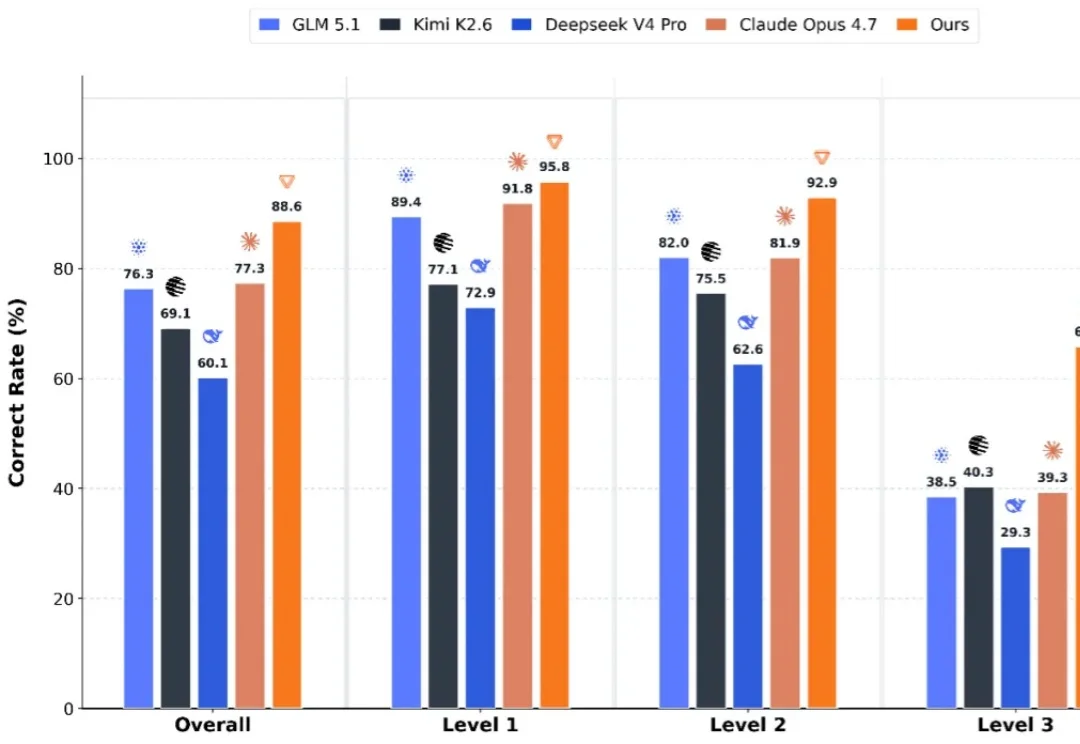
刚刚,田渊栋创业公司,交出了首个研究成果。田渊栋在X上宣布,其创立的Recursive,在NVIDIA官方的GPU kernel优化榜SOL-ExecBench上拿下了整体和四个子类别的SOTA。
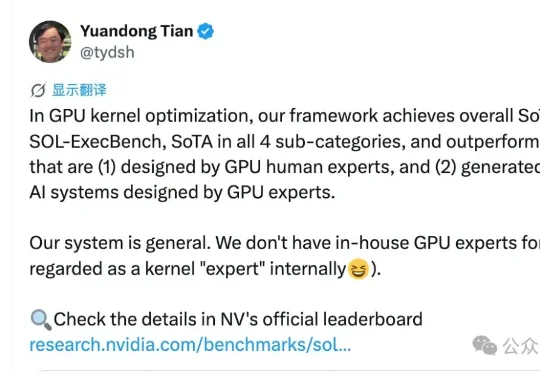
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。

复盘三年多的AI行情,就是一个不断找硬件瓶颈的过程:最开始涨GPU,后来涨服务器,再后来涨数据中心,然后涨电力,接着涨HBM存,现在又开始涨CPU、高速互联和ASIC。
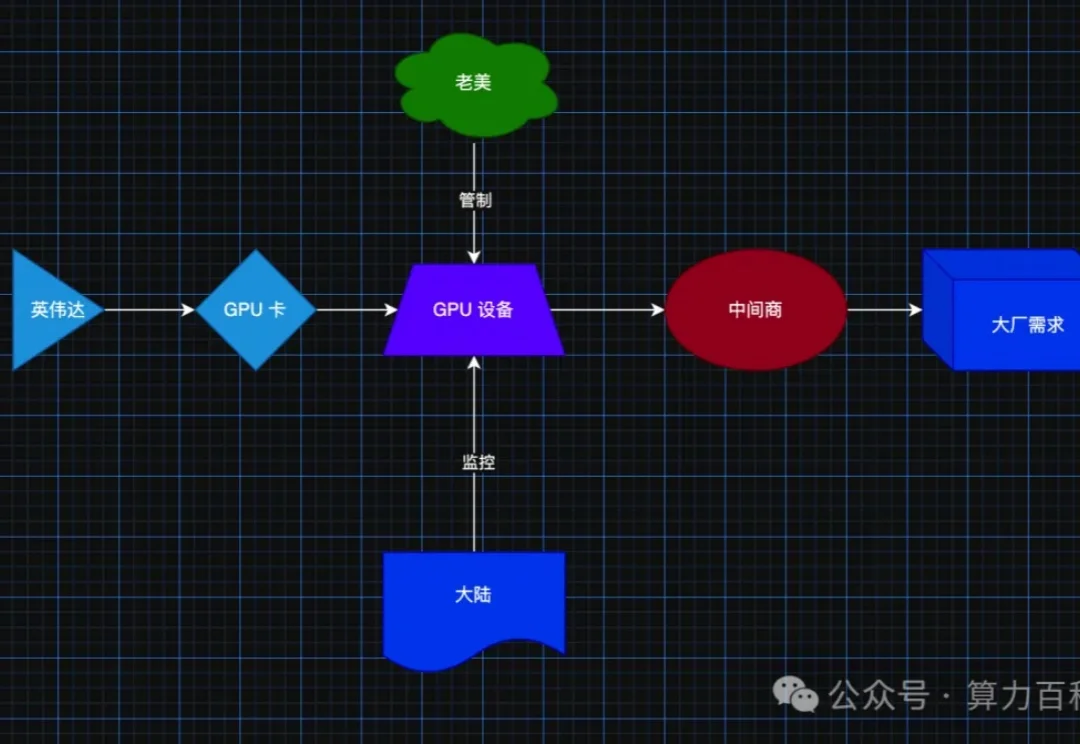
5 月份,非常非常多的人寄希望于两个大佬谈判之后的的 GPU管制放松,特别是上一代 hopper架构的顶配算力卡松绑,弥补内部的算力不足,但是结果事与愿违,双方在 GPU 算力领域抓紧了卡脖子竞赛,彼此相互掐。(不要抱幻想了,干就完了)