
【独家】小米正搭建GPU万卡集群,将对AI大模型大力投入
【独家】小米正搭建GPU万卡集群,将对AI大模型大力投入12月26日,界面新闻独家获悉,小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。小米大模型团队在成立时已有6500张GPU资源。
来自主题: AI资讯
9712 点击 2024-12-26 15:52
 搜索
搜索
12月26日,界面新闻独家获悉,小米正在着手搭建自己的GPU万卡集群,将对AI大模型大力投入。小米大模型团队在成立时已有6500张GPU资源。

着实有点Amazing啊。
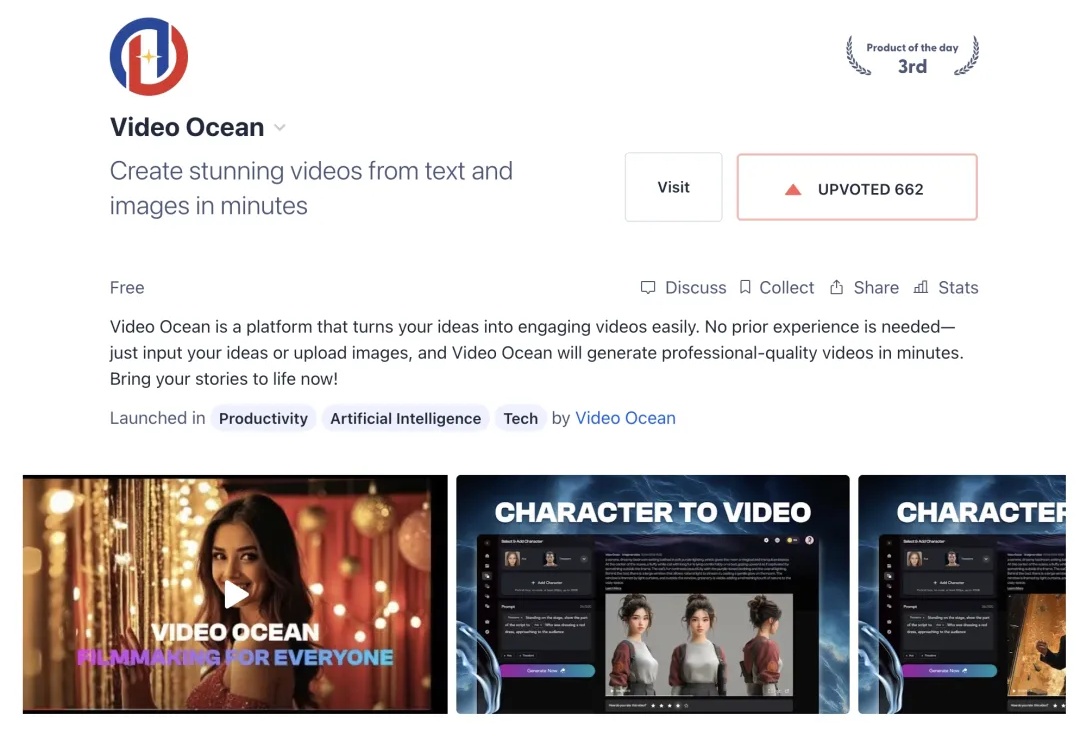
随着Sora震撼发布,视频生成技术成为了AI领域新风口。不过,高昂的开发成本是一大瓶颈。国产平台Video Ocean不仅成功登上全球热榜第三,还将视频生成模型开发成本降低50%。而且,模型构建和性能优化方案现已开源,还能免费获得500元GPU算力。

联想第六代“海神”液冷技术,已实现支持多类型GPU、CPU,散热效率可达98%,PUE最佳可降至1.1,极大降低了数据中心的能耗水平。

许多没有任何GPU背景、算力行业经验的上市公司,将智算中心当做他们发展第二曲线的抓手,筹谋向AI领域转型——比如,生产味精的公司(莲花控股)、造染料的公司(锦鸡股份)、甚至还有博彩行业的玩家(鸿博股份)等等。 但到2024年年底,情况出现了逆转。

2024年英伟达GPU全球最大买家,竟是微软?购买总量将近50万块,超所有竞争对手近两倍。xAI已开心晒出首批发货的GB200 NVL72,喜滋滋的像是提前过年了。囤的GPU越多,模型就会越好吗?来不及解释了,赶紧上车,车门焊死!

明年的国际消费类电子产品展览会(CES 2025)将在北京时间 1 月 8 日至 11 日举行,包括英特尔、英伟达和 AMD 在内的各大 CPU、GPU 厂商将带着自家最新产品闪亮登场。
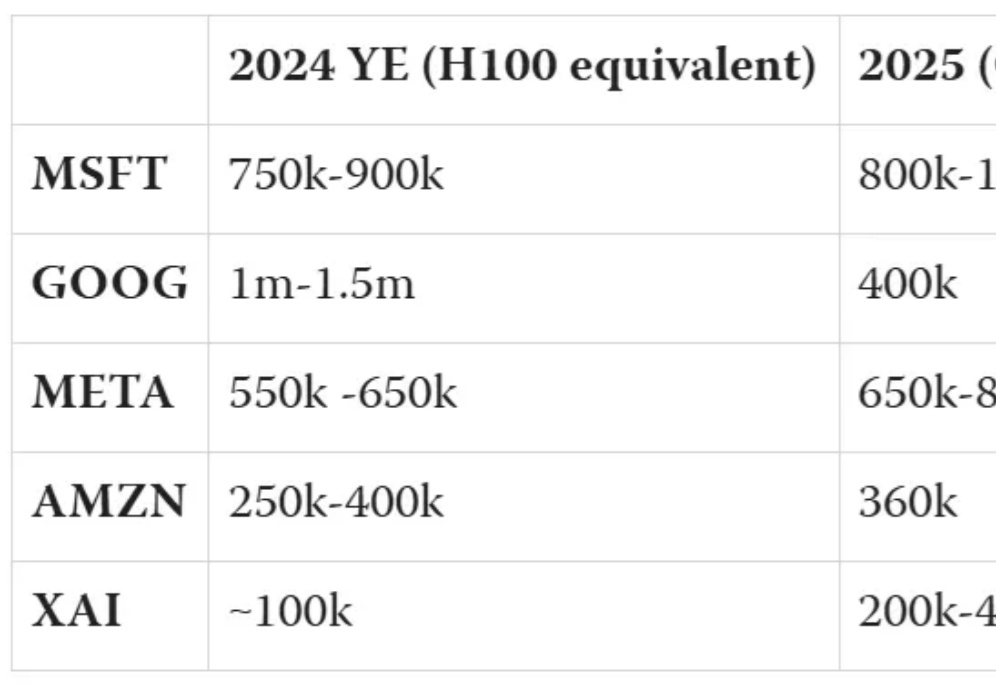
AI巨头的芯片之争,谷歌微软目前分列一二。而xAI作为新入局者,正迅速崛起。这场竞争中,谁会成为最后赢家?
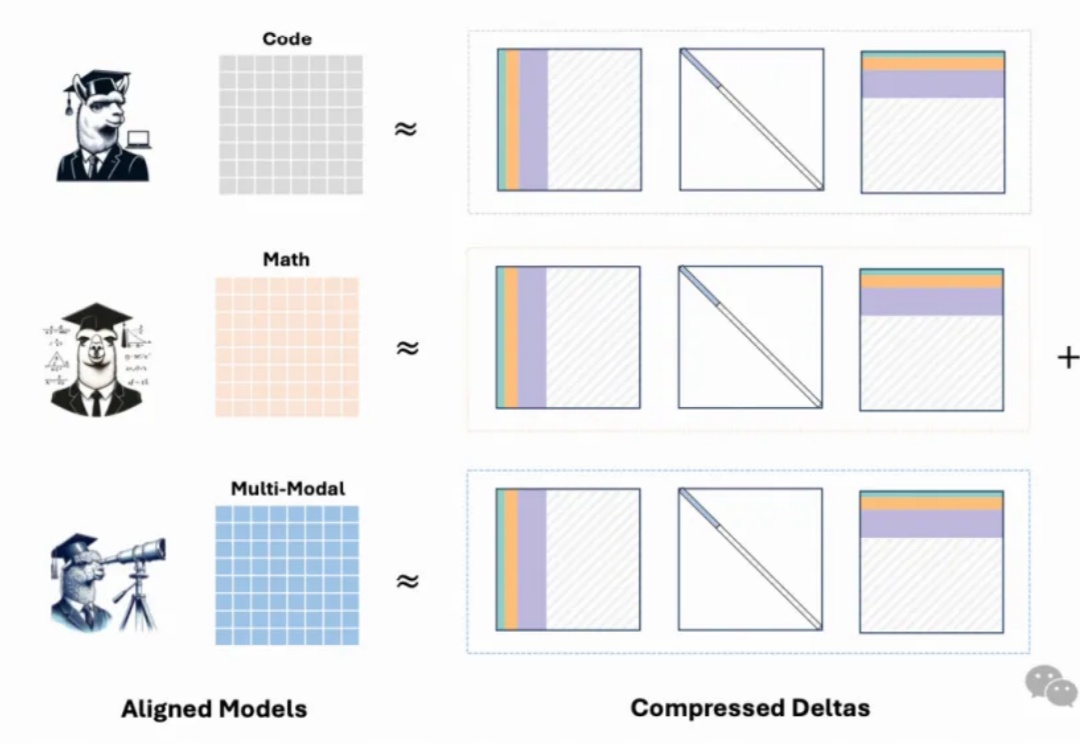
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。
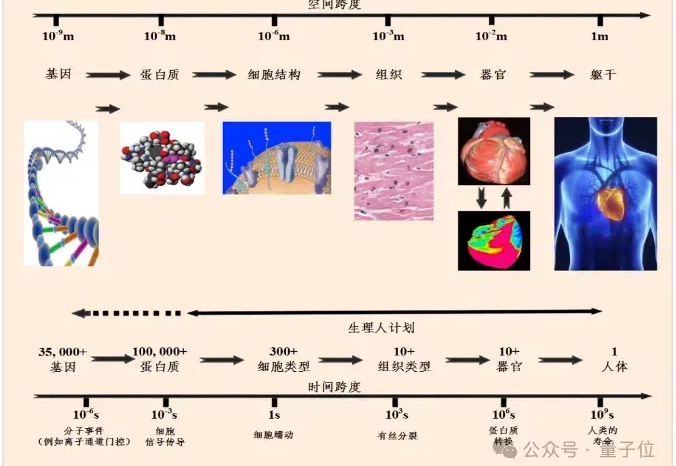
超实时计算!智源模拟心脏,实现了生物时间与计算时间比为1:0.84。 一般来说,仿真时间与生物时间比达到1:1,就已经算是实时计算了。而在此之前的虚拟心脏仿真系统还没有实现过,如今,在更大规模和更高复杂度的心脏模型上实现了180倍的速度提升。