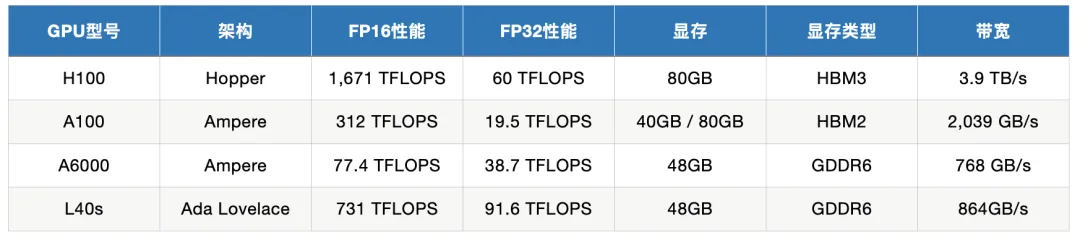
深度|NVIDIA旗舰GPU对比:H100、A6000、L40S、A100在训练与推理中的应用
深度|NVIDIA旗舰GPU对比:H100、A6000、L40S、A100在训练与推理中的应用通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。
来自主题: AI资讯
10876 点击 2024-10-31 11:55
 搜索
搜索
通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。

最近有一篇题为《2美元的H100:GPU泡沫是如何破灭的?》的文章异常火热,甚至投资人都认为英伟达坚挺的股价就是被这一篇文章所摧毁。

人类已知最大的素数,被GPU发现了!英伟达前员工Luke Durant发现的2136279841-1,比前一个纪录保持者多出1600万位,由A100计算,H100确认。为此,小哥搭了数千个GPU的「云超算」,分布在17个国家。
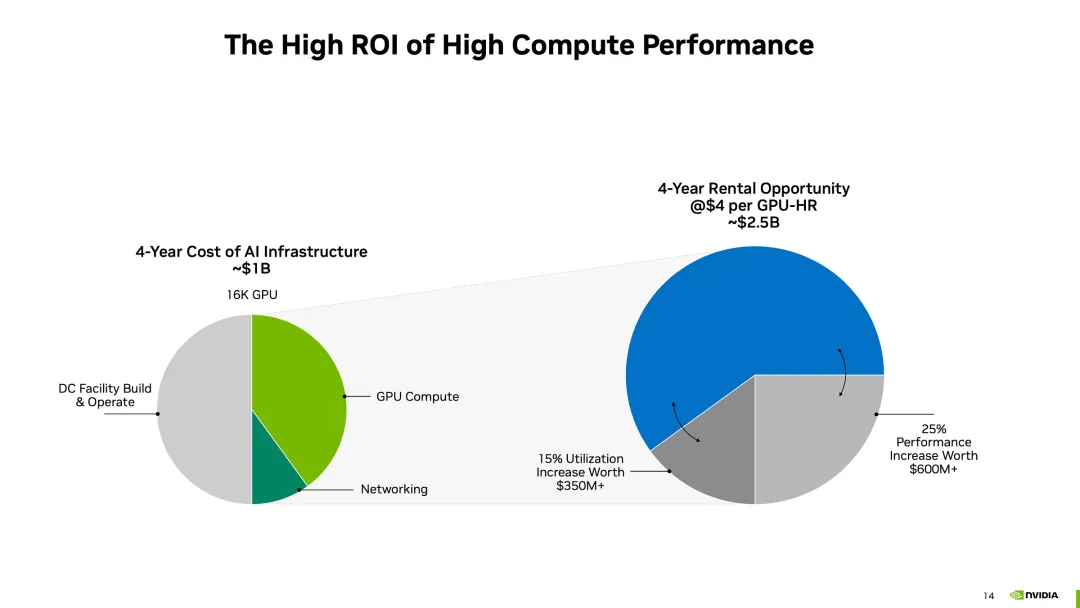
红杉资本的报告曾指出,AI产业的年产值超过6000亿美元,才够支付数据中心、加速GPU卡等AI基础设施费用。而现在一种普遍说法认为,基础模型训练的资本支出是“历史上贬值最快的资产”,但关于GPU基础设施支出的判定仍未出炉,GPU土豪战争仍在进行。

H100租赁价格下跌,真的能和“GPU泡沫破灭”画上等号吗? 一则有关“2美元/小时出租H100:GPU泡沫破灭前夜”的报道引发国内市场高度关注。

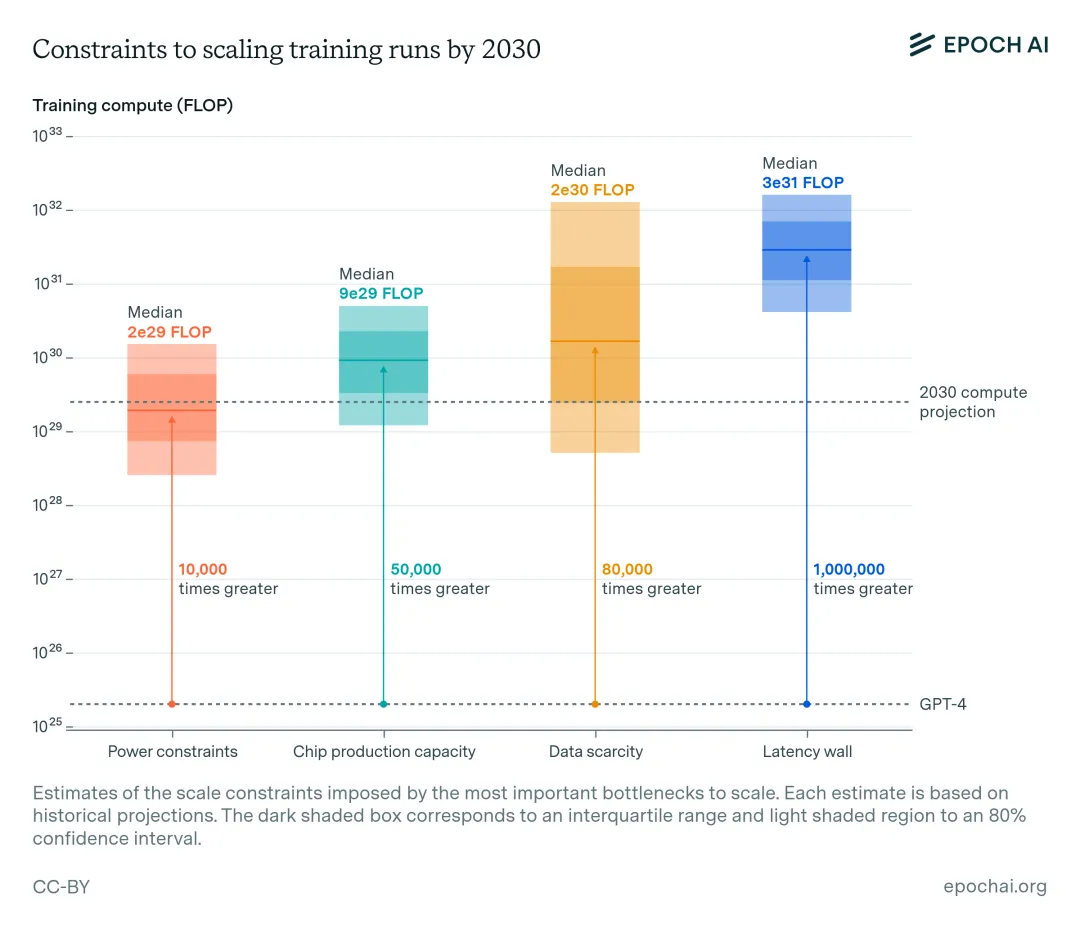
随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。
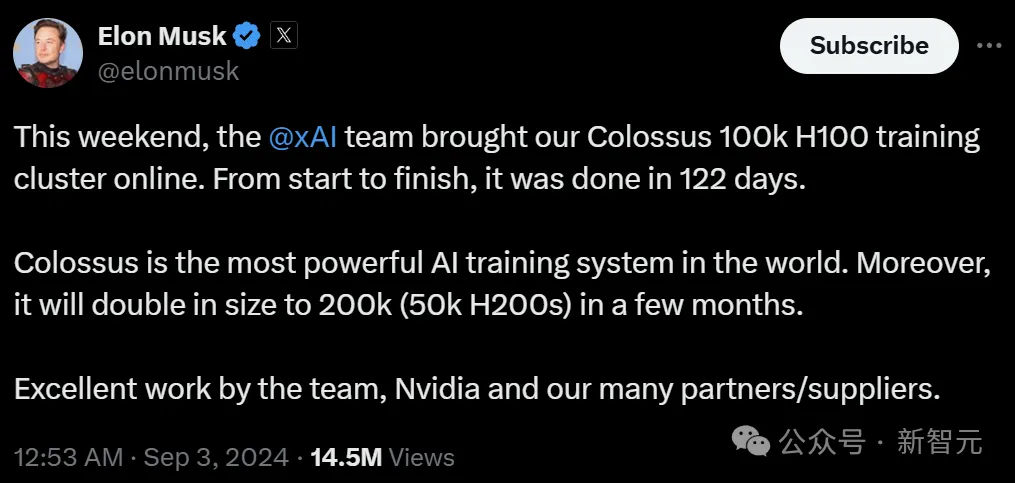
两天前,马斯克得意自曝:团队仅用122天,就建成了10万张H100的Colossus集群,未来还会扩展到15万张H100和5万张H200。此消息一出,奥特曼都被吓到了:xAI的算力已经超过OpenAI了,还给员工承诺了价值2亿期权,这是要上天?
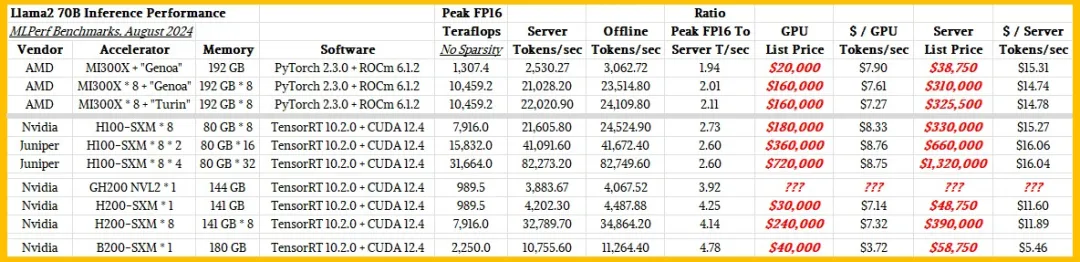
都很贵。

大摩认为,GPU供应仍然比较紧张,需求继续超过供应。过去6个月中H100租赁价格有所下降,但价格的绝对水平表明硬件的投资回报率非常高,回本期在一年以内。