刚刚,Claude爆改语音!11种语言,就是没中文
刚刚,Claude爆改语音!11种语言,就是没中文刚刚,Anthropic和OpenAI同时放出了语音模式大升级!Claude这边,从只能跑Haiku升级到Opus 4.8和Sonnet 5全系列,不仅能在对话里调Gmail、日历、Slack,还扩增到11种语言,但没有中文。
来自主题: AI资讯
8119 点击 2026-07-24 15:55
 搜索
搜索
刚刚,Anthropic和OpenAI同时放出了语音模式大升级!Claude这边,从只能跑Haiku升级到Opus 4.8和Sonnet 5全系列,不仅能在对话里调Gmail、日历、Slack,还扩增到11种语言,但没有中文。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
7月14日,旧金山,设计人工智能模型以发现新分子的Chai Discovery宣布完成4亿美元的C轮融资,以进一步加快进展。本轮融资对该公司的估值为38亿美元,由Index Ventures、凯鹏华盈

今年四月,吴明泽因为"装龙虾"认识了一位货代公司老板。说来也巧。那位朋友在物流行业干了整整十年,四月正好是龙虾进口旺季,就顺手给吴明泽介绍了这位年营收过亿的老板。吴明泽是谁?哈佛设计工程硕士、斯坦福HAI(人工智能实验室)科研助理。他还在阿里、腾讯、MiniMax做过工程师
如果你的日常任务里包含编程,今天给大家介绍一个特别适合团队用的AI开发平台「MonkeyCode」,目前在GitHub已狂揽3.4k Star,开源免费。开源地址:github.com/chaitin/MonkeyCode

近期,在 LangChain 举办的智能体大会 Interrupt 上,吴恩达与 LangChain 创始人 Harrison Chase 进行了一场关于 AI Agent 的对谈。整场交流的核心并不是简单讨论 Agent 有多强,而是围绕一个更现实的问题展开:当 AI Agent 让软件开发变快之后,真正的瓶颈会转移到哪里?
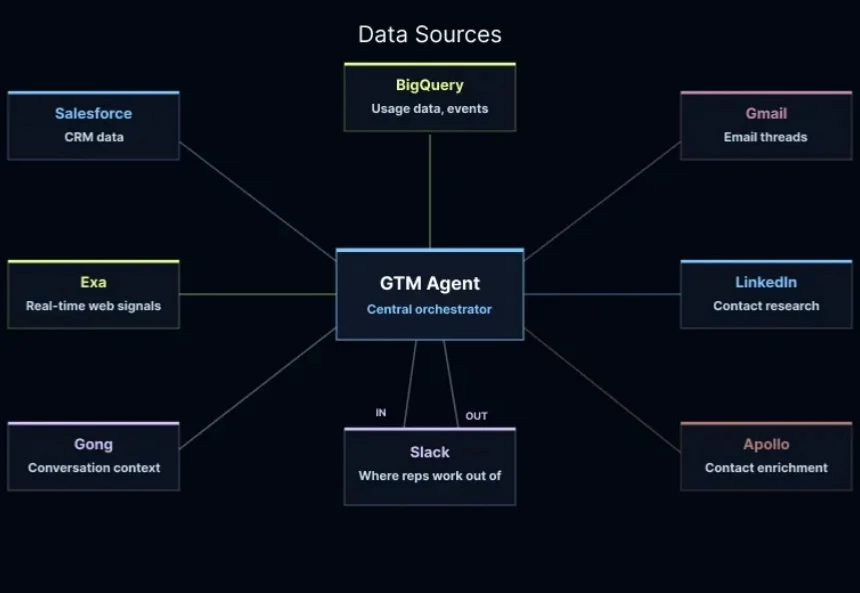
你有没有想过,销售这件事可能会被彻底重新定义?不是那种换个 CRM 系统或者学几个销售话术的小改进,而是从根本上改变销售人员的日常工作方式。
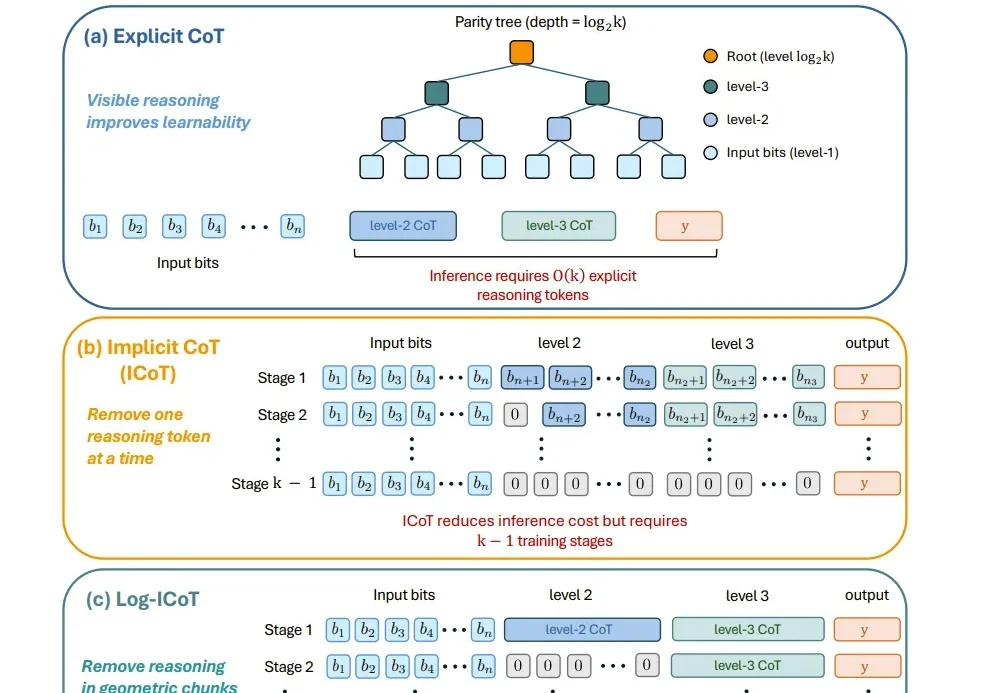
过去一年,AI 推理模型的使用成本让不少开发者叫苦。

近日,AI制药独角兽Chai Discovery宣布与制药巨头辉瑞达成许合作许可。合作后辉瑞将获得Chai Discovery首次曝光的新一代模型Chai-3的优先访问权限,以及利用辉瑞专有数据、量身定制的定制模型。
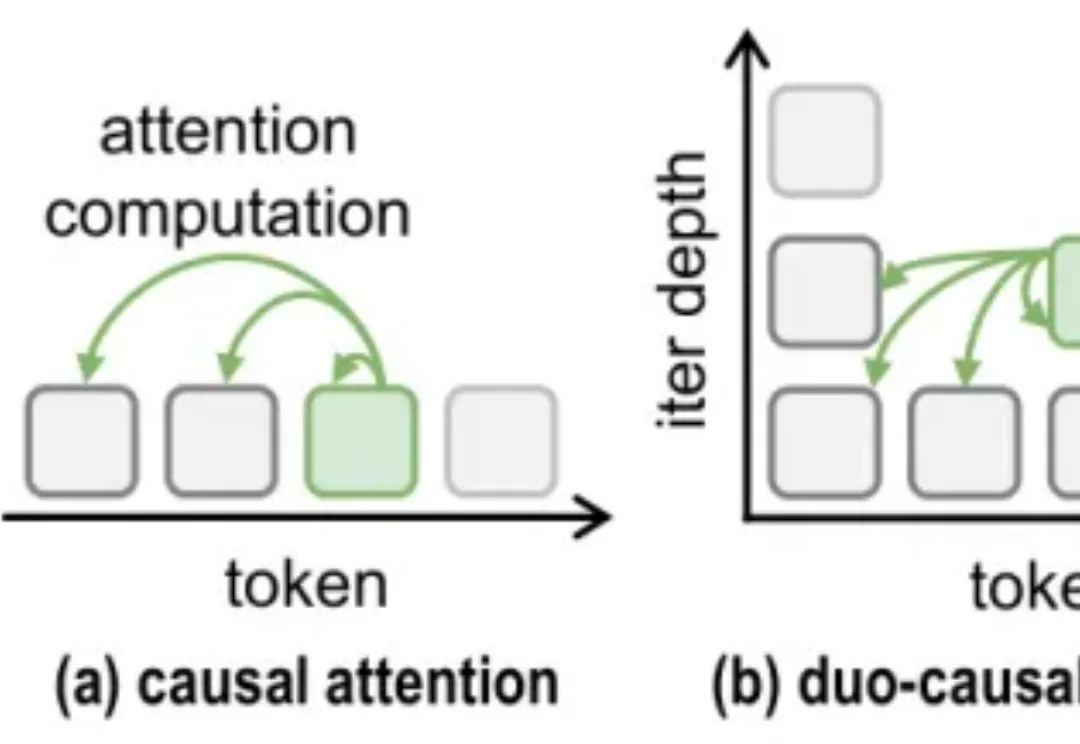
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。