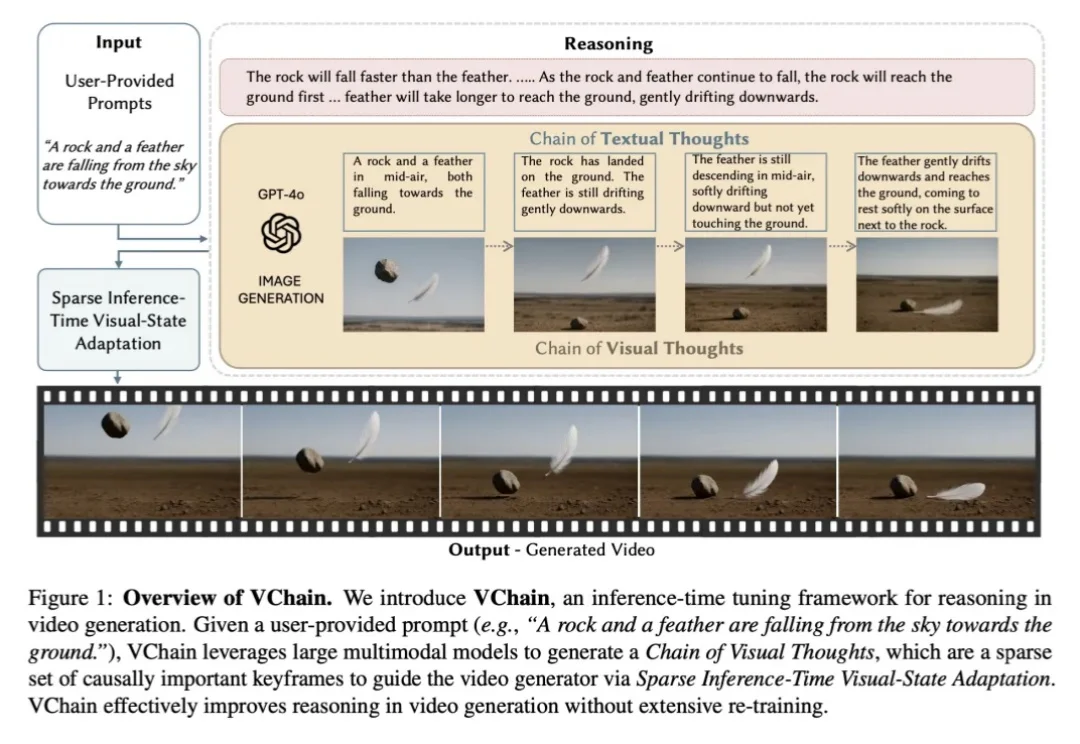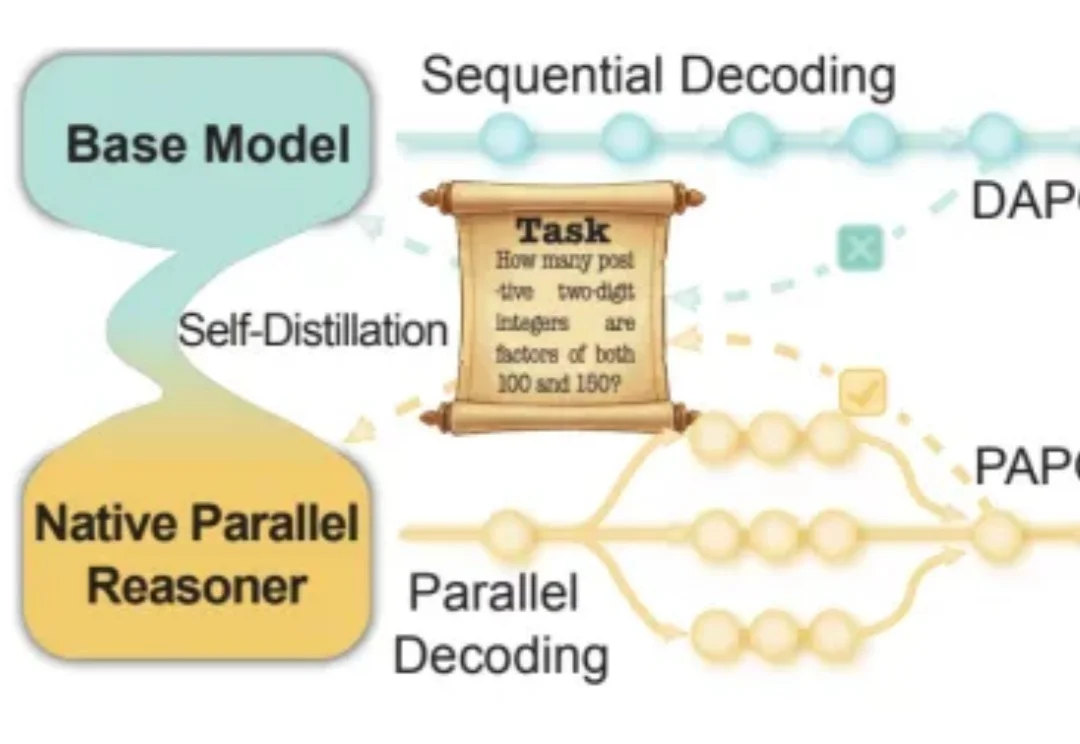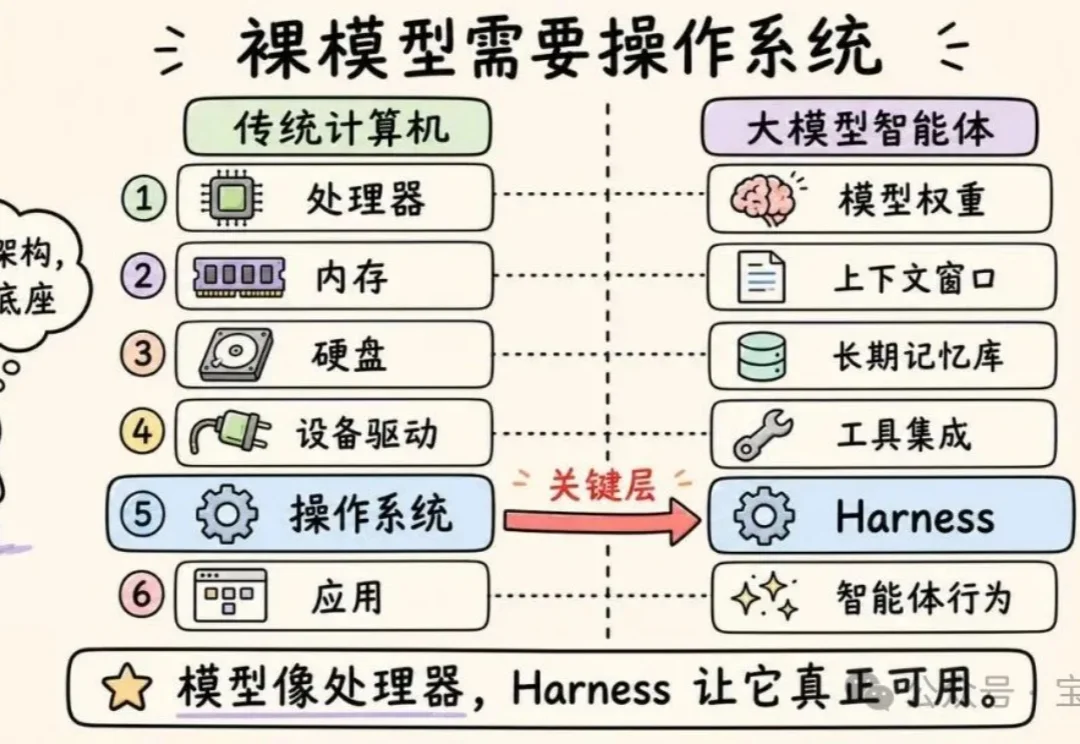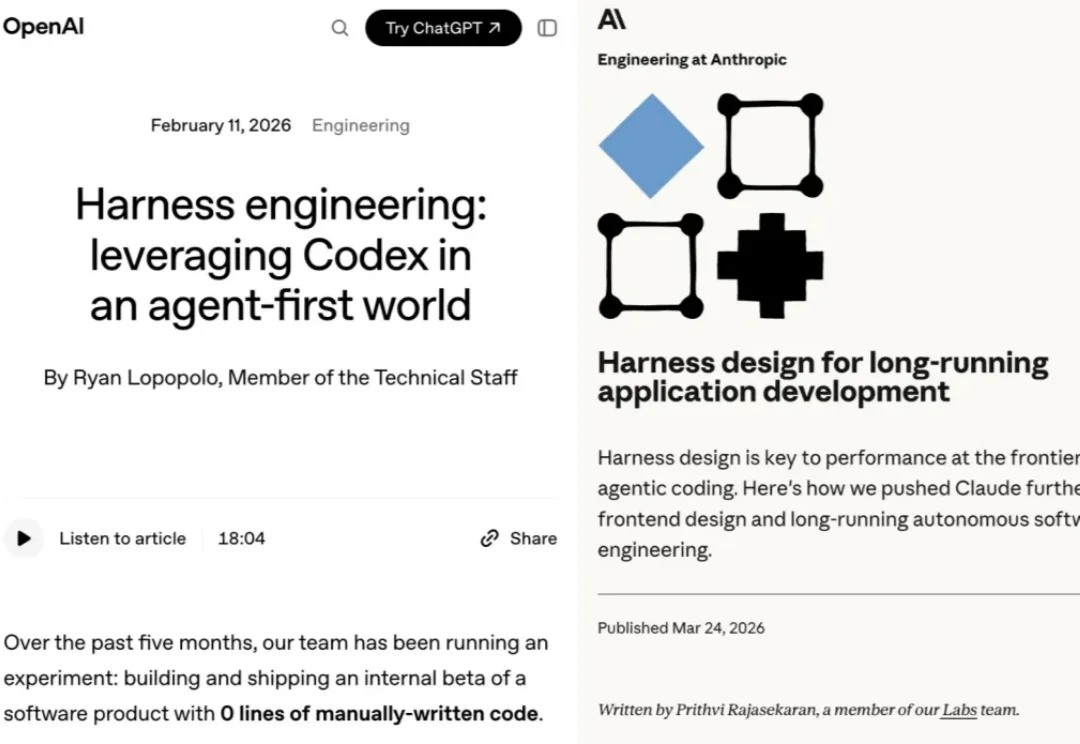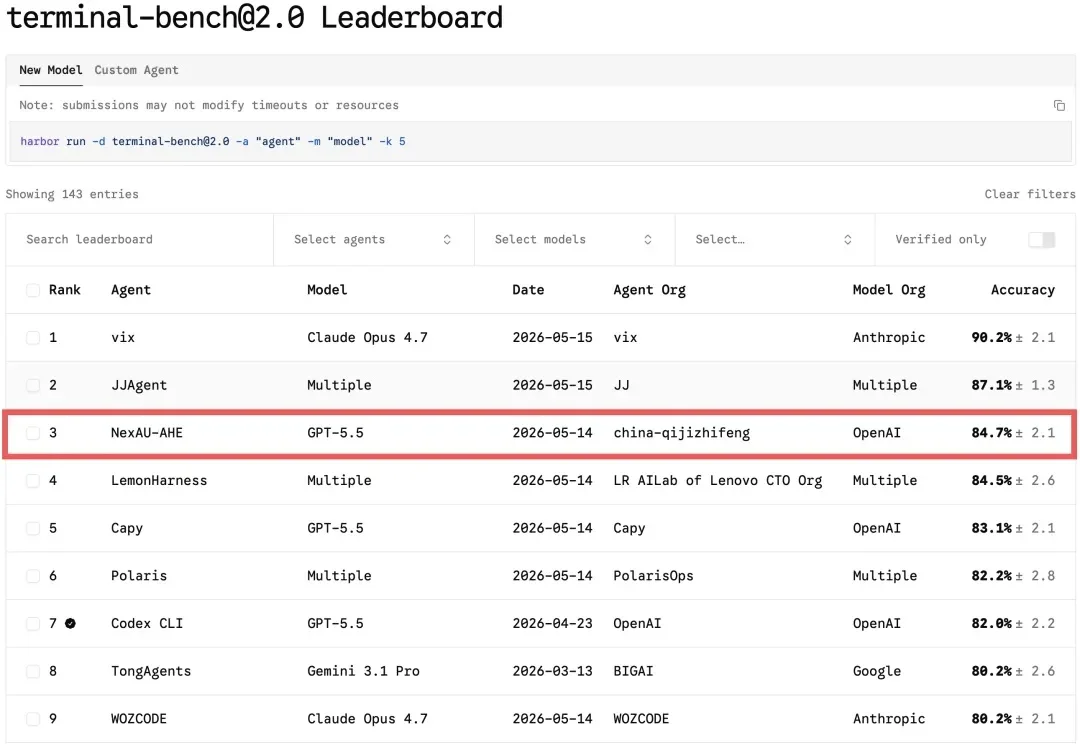
全球排名前三,复旦自进化Harness Engineering让GPT‑5.4再涨7个点
全球排名前三,复旦自进化Harness Engineering让GPT‑5.4再涨7个点2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
来自主题: AI技术研报
10065 点击 2026-05-21 10:13