里程碑时刻!首个100B扩散语言模型来了,技术报告揭秘背后细节
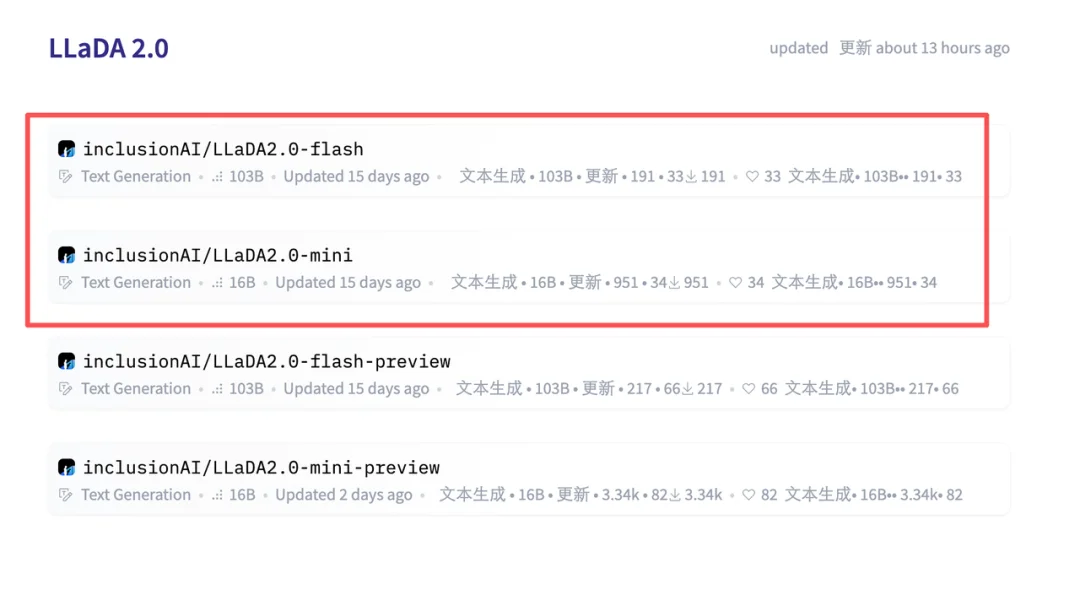
里程碑时刻!首个100B扩散语言模型来了,技术报告揭秘背后细节前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
来自主题: AI资讯
10773 点击 2025-12-12 16:08