
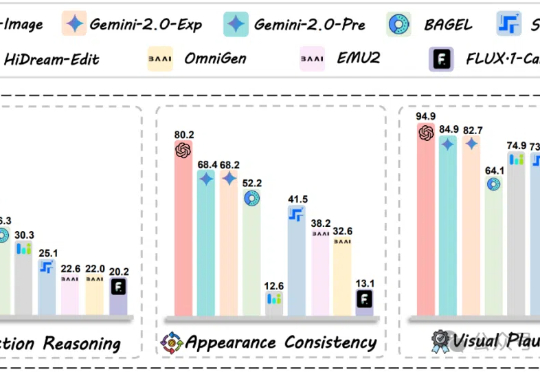
GPT-4o-Image仅完成28.9%任务!上海AI实验室等发布图像编辑新基准,360道人类专家严选难题
GPT-4o-Image仅完成28.9%任务!上海AI实验室等发布图像编辑新基准,360道人类专家严选难题GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。
来自主题: AI技术研报
10248 点击 2025-05-31 14:37
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

FLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。

在人类的认知过程中,视觉思维(Visual Thinking)扮演着不可替代的核心角色,这一现象贯穿于各个专业领域和日常生活的方方面面。

今年,Google算是打了个翻身仗。

今夜,谷歌彻底杀疯!2小时发布会,Gemini提及95次点亮全场。Gemini 2.5家族全系升级,Pro深度思考模型正刷榜。全新Imagen 4生成细节超逼真,Veo 3首次实现音视频融合。

刚刚,鹅厂把文生图卷出了新高度——发布混元图像2.0模型(Hunyuan Image 2.0),首次实现毫秒级响应,边说边画,实时生成!用户一边描述,它紧跟着绘制,整个过程那叫一个丝滑。不用等待,专治各种没有耐心。

OpenAI推出图像生成API,低至0.02美元/张,支持多模态定制。
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ——gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。
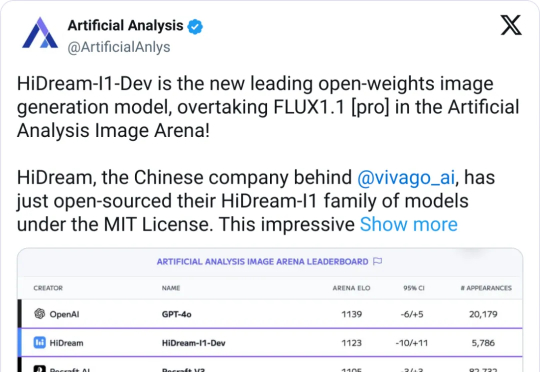
刚出道的 HiDream-I1,拿下了 Hugging Face 趋势榜第二(图像榜第一),Artificial Analysis 文生图第二,排在Midjourney、Google Imagen、FLUX、SDXL 之前,仅次于 GPT-4o 。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。