
二元成功率已经过时!PRM-as-a-Judge才是你需要的具身操作评测框架
二元成功率已经过时!PRM-as-a-Judge才是你需要的具身操作评测框架随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。
来自主题: AI技术研报
9021 点击 2026-04-14 14:57
 搜索
搜索
随着机器人操作从短程、单步技能逐步走向长程、富接触、需要持续协调与恢复能力的复杂任务,传统以二元成功率为核心的评测方式开始暴露出明显局限。它能够回答 “任务是否完成”,却难以回答 “策略推进到了哪里”“执行过程是否高效稳定”“失败究竟发生在什么阶段”。
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。
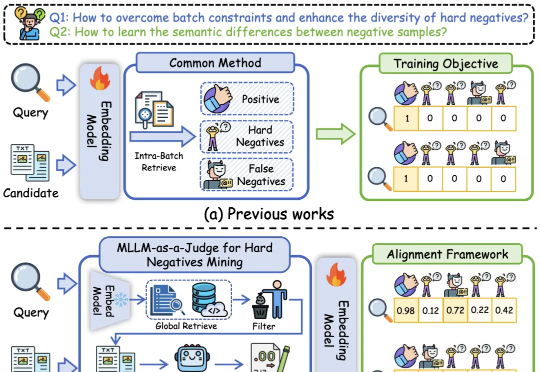
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。
让LMM作为Judge,从对模型的性能评估到数据标注再到模型的训练和对齐流程,让AI来评判AI,这种模式几乎已经是当前学术界和工业界的常态。
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
文生图 or 图生文?不必纠结了!
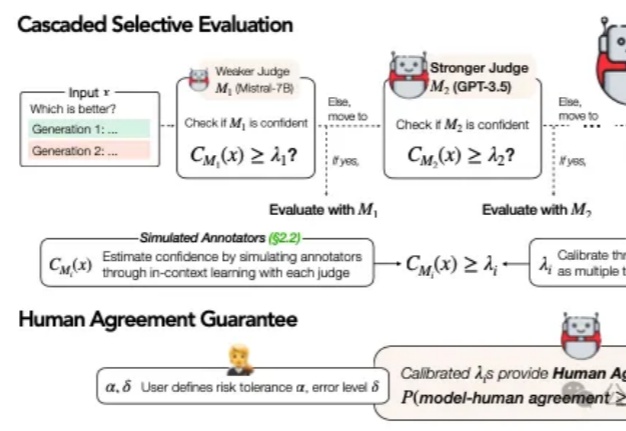
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。
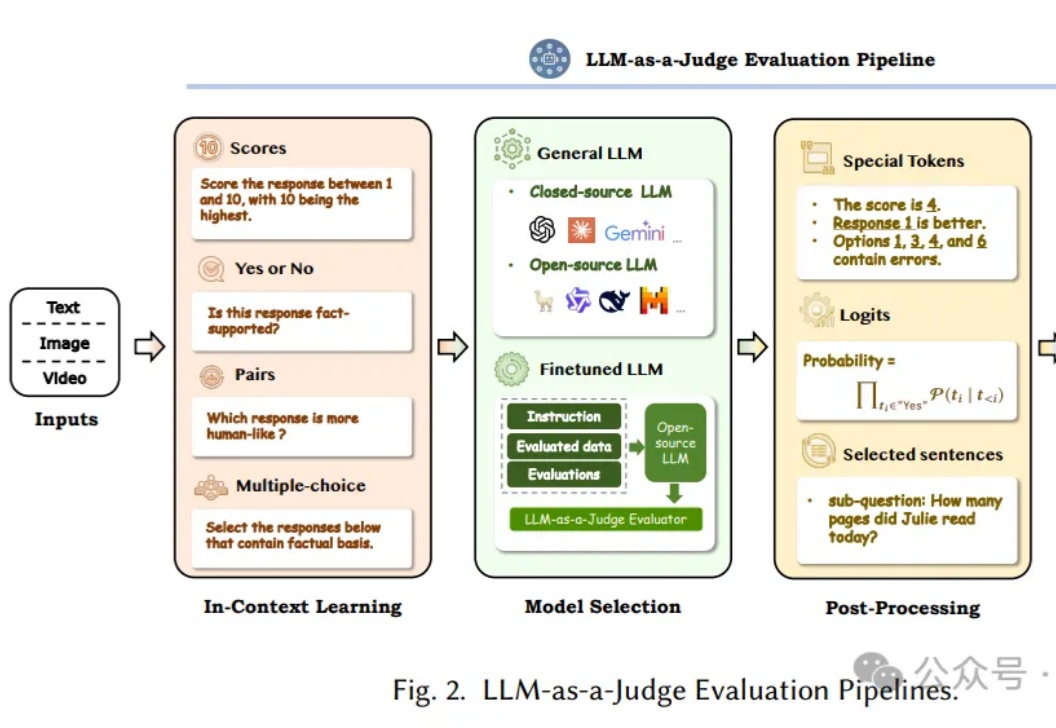
让AI来评判AI,即利用大语言模型(LLM)作为评判者,已经成为近半年的Prompt热点领域。这个方向不仅代表了AI评估领域的重要突破,更为正在开发AI产品的工程师们提供了一个全新的思路。

AI评估AI可靠吗?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。