ICML 2025 | 长视频理解新SOTA!蚂蚁&人大开源ViLAMP-7B,单卡可处理3小时视频
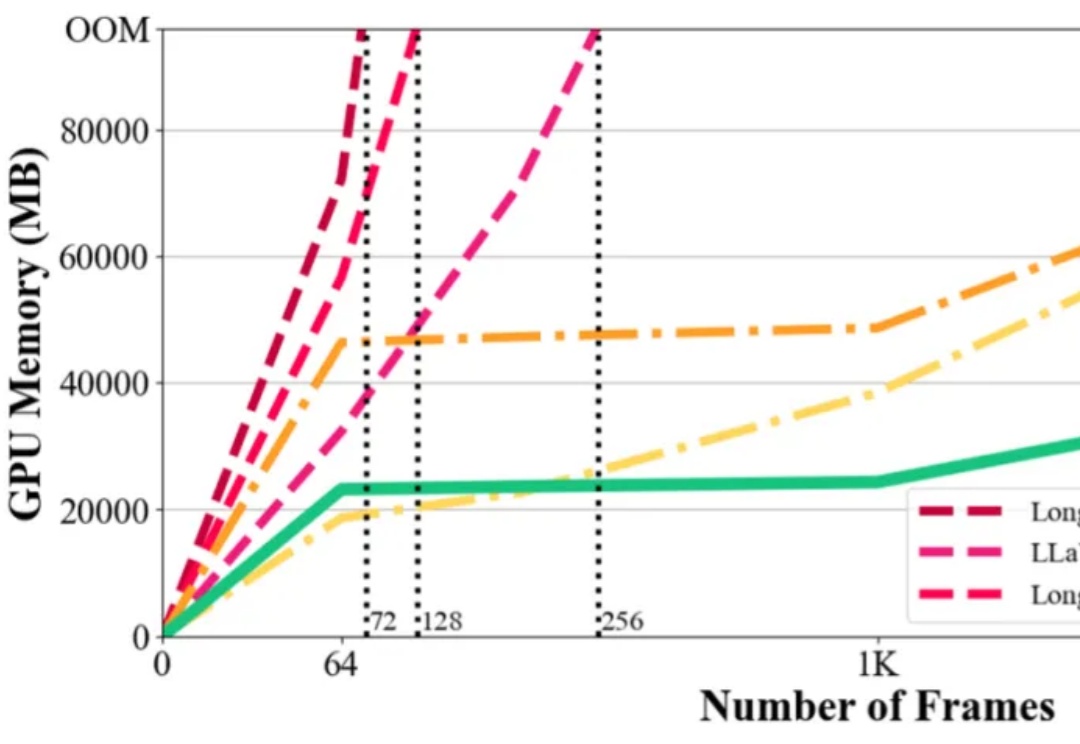
ICML 2025 | 长视频理解新SOTA!蚂蚁&人大开源ViLAMP-7B,单卡可处理3小时视频在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。
来自主题: AI技术研报
7680 点击 2025-05-13 08:54