
百倍提升7B模型推理能力!颜水成团队携手新加坡南洋理工大学发布Q*算法
百倍提升7B模型推理能力!颜水成团队携手新加坡南洋理工大学发布Q*算法近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。
来自主题: AI资讯
11954 点击 2024-06-26 10:57
 搜索
搜索
近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。
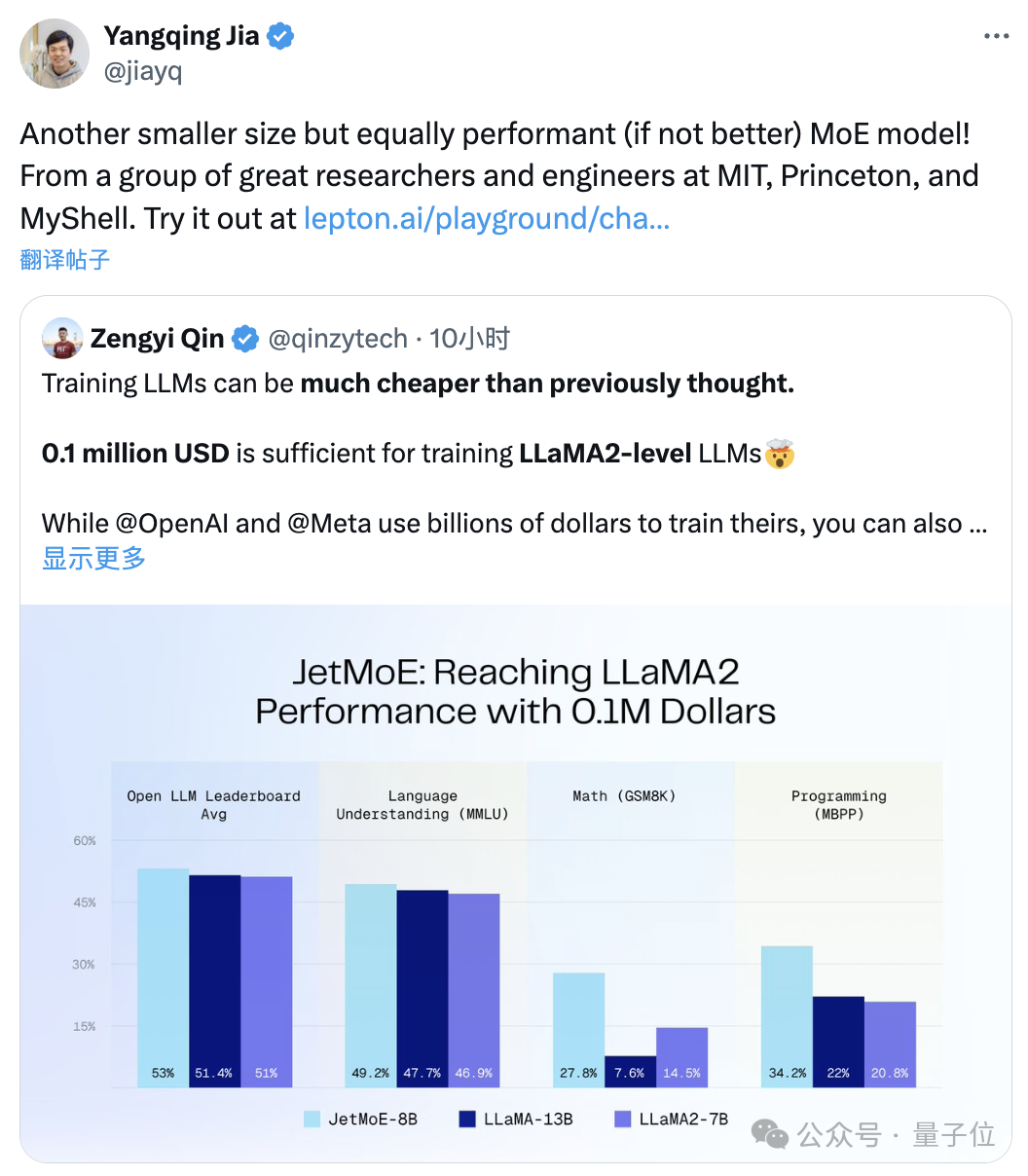
“只需”10万美元,训练Llama-2级别的大模型。尺寸更小但性能不减的MoE模型来了:它叫JetMoE,来自MIT、普林斯顿等研究机构。性能妥妥超过同等规模的Llama-2。

数学问题解决能力一直被视为衡量语言模型智能水平的重要指标。通常只有规模极大的模型或经过大量数学相关预训练的模型才能有机会在数学问题上表现出色。
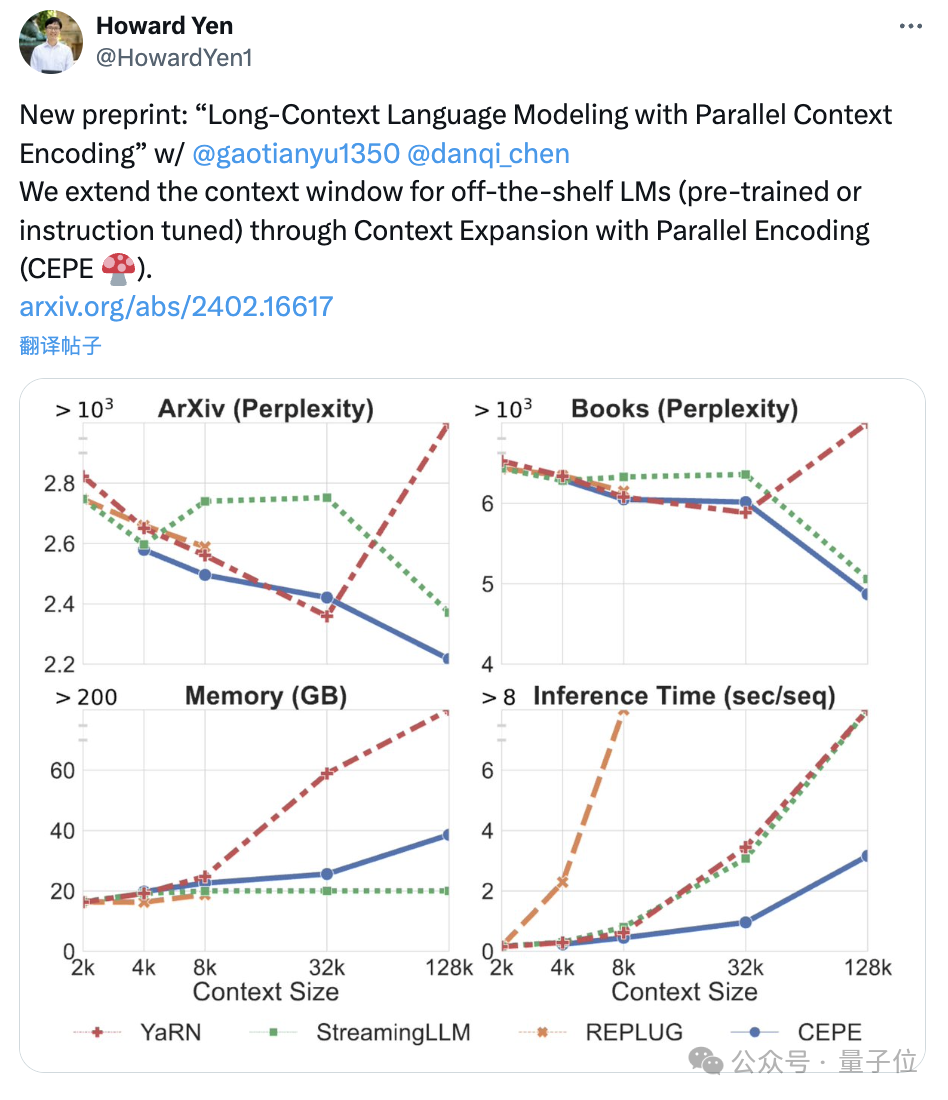
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。

删除权重矩阵的一些行和列,让 LLAMA-2 70B 的参数量减少 25%,模型还能保持 99% 的零样本任务性能,同时计算效率大大提升。这就是微软 SliceGPT 的威力。

融合多个异构大语言模型,中山大学、腾讯 AI Lab 推出 FuseLLM

微调LLM需谨慎,用良性数据、微调后角色扮演等都会破坏LLM对齐性能!学习调大了还会继续提高风险!