
多语言大模型新SOTA!Cohere最新开源Aya-23:支持23种语言,8B/35B可选
多语言大模型新SOTA!Cohere最新开源Aya-23:支持23种语言,8B/35B可选Aya23在模型性能和语言种类覆盖度上达到了平衡,其中最大的35B参数量模型在所有评估任务和涵盖的语言中取得了最好成绩。
来自主题: AI技术研报
10520 点击 2024-05-31 18:18
 搜索
搜索
Aya23在模型性能和语言种类覆盖度上达到了平衡,其中最大的35B参数量模型在所有评估任务和涵盖的语言中取得了最好成绩。

在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。

斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。
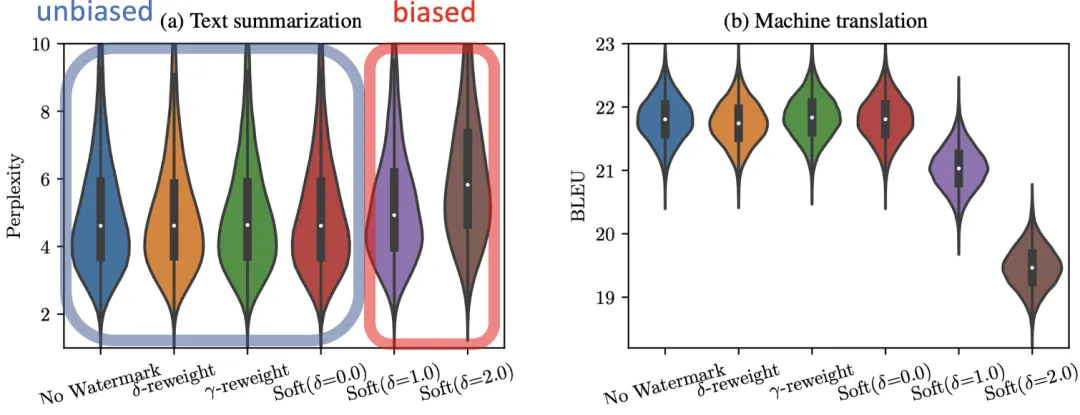
随着大语言模型(LLM)的快速发展,其在文本生成、翻译、总结等任务中的应用日益广泛。如微软前段时间发布的Copilot+PC允许使用者利用生成式AI进行团队内部实时协同合作,通过内嵌大模型应用,文本内容可能会在多个专业团队内部快速流转,对此,为保证内容的高度专业性和传达效率,同时平衡内容追溯、保证文本质量的LLM水印方法显得极为重要。

AI 智能体的宣传很好,现实不太妙。

当火山引擎要在阿里的腹地与其贴脸开打,还有一场场硬仗等待着他。

经济观察报注意到,目前降低的只是调用大模型应用程序编程接口(API)的费用。与这一费用相比,客户使用云服务后,付费环节更多、付费额度更高。

当前,多模态大模型 (MLLM)在多项视觉任务上展现出了强大的认知理解能力。 然而大部分多模态大模型局限于单向的图像理解,难以将理解的内容映射回图像上。 比如,模型能轻易说出图中有哪些物体,但无法将物体在图中准确标识出来。 定位能力的缺失直接限制了多模态大模型在图像编辑,自动驾驶,机器人控制等下游领域的应用。针对这一问题,港大和字节跳动商业化团队的研究人员提出了一种新范式Groma

Jason Wei 是思维链提出者,并和 Yi Tay、Jeff Dean 等人合著了关于大模型涌现能力的论文。目前他正在 OpenAI 进行工作。
ChemLLM系列模型是由上海人工智能实验室开发的首个兼备推理、对话等通用能力和化学专业能力的开源大模型。相比于现有的其他大模型,ChemLLM对化学空间进行了有效建模,在产物预测、名称转化和化学性质预测等核心化学任务上表现优异。ChemLLM系列模型已经发布到了始智AI wisemodel.cn开源社区,并且无需任何代码,两步即可完成模型的在线体验。