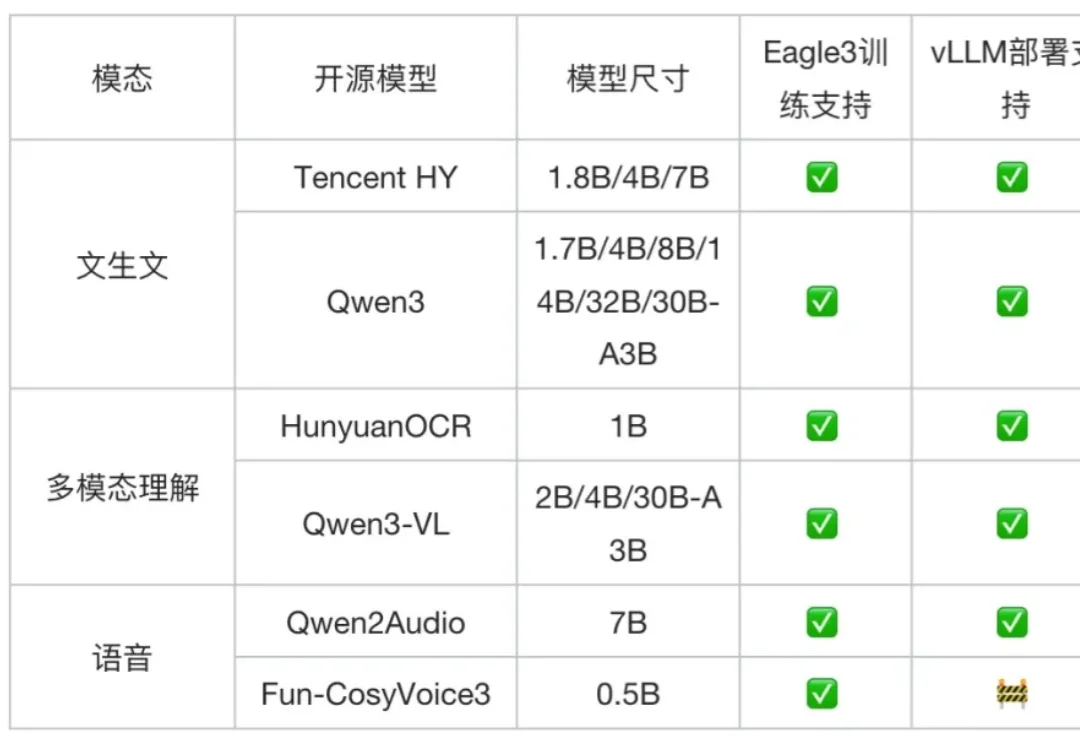
腾讯AngelSlim升级,首个集LLM、VLM及语音多模态为一体的投机采样训练框架,推理速度飙升1.8倍
腾讯AngelSlim升级,首个集LLM、VLM及语音多模态为一体的投机采样训练框架,推理速度飙升1.8倍随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。
来自主题: AI技术研报
11023 点击 2026-01-19 08:54