多模态推理新范式!DiffThinker:用扩散模型「画」出推理和答案
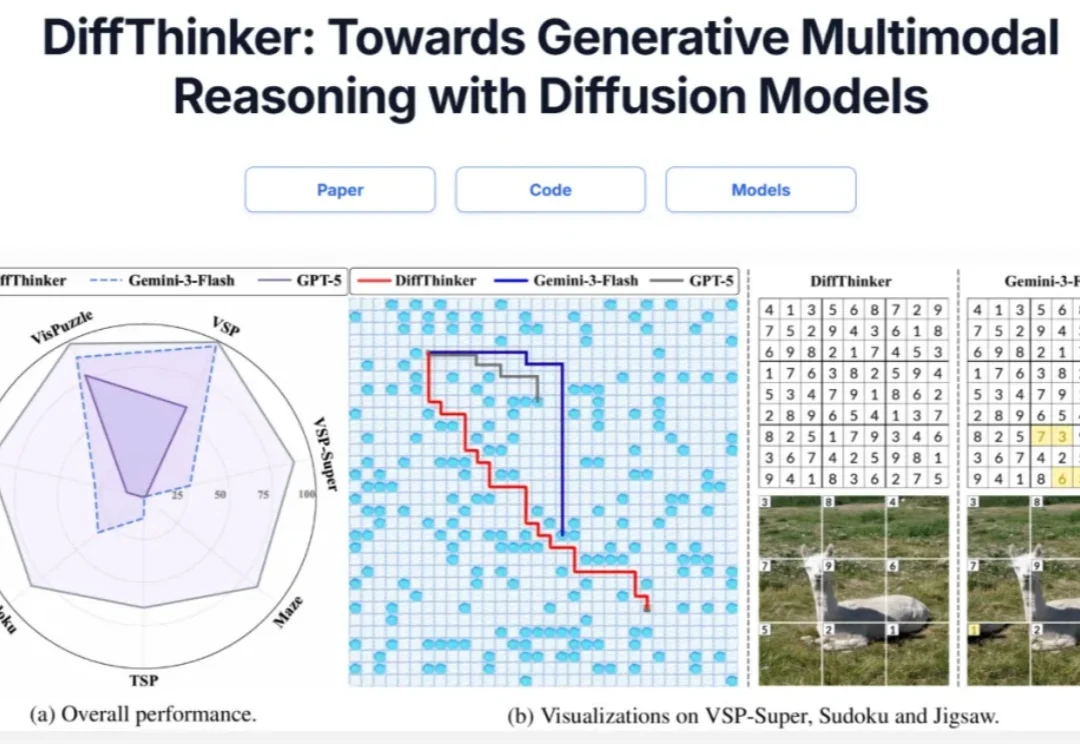
多模态推理新范式!DiffThinker:用扩散模型「画」出推理和答案在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
来自主题: AI技术研报
7735 点击 2026-01-08 15:20
 搜索
搜索
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。

您可能已经感受到了,从2025年开始到如今,全世界都在谈论Agentic AI或Agent(代理式AI)。从董事会到咨询公司,从更高级别的战略到街头巷尾,仿佛只要接入了大模型(LLM),所有的业务流程就能自动运转,效率就能翻倍。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。

近日,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model),这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。
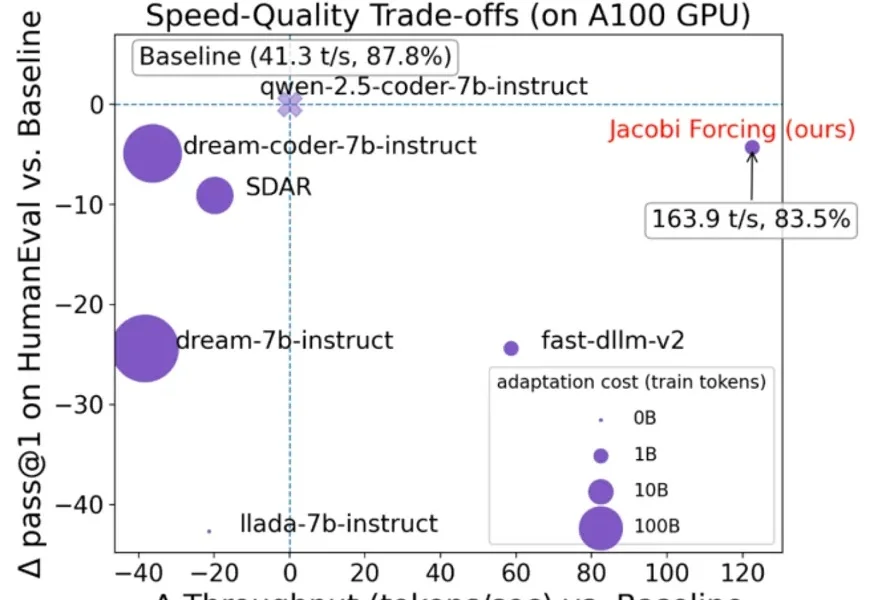
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面
在大模型智能体(LLM Agent)落地过程中,复杂工作流的高效执行、资源冲突、跨框架兼容、分布式部署等问题一直困扰着开发者。而一款名为Maze的分布式智能体工作流框架,正以任务级精细化管理、智能资源调度、多场景部署支持等核心优势,为这些痛点提供一站式解决方案。
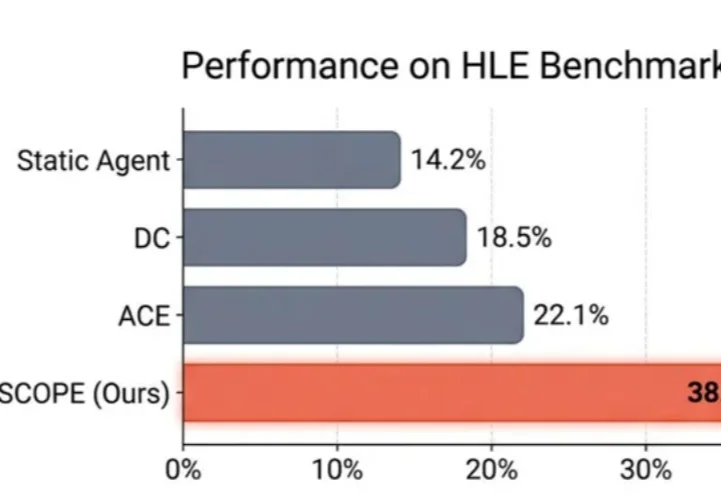
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。