
北航提出代码大模型的 Scaling Laws:编程语言差异与多语言最优配比策略
北航提出代码大模型的 Scaling Laws:编程语言差异与多语言最优配比策略在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
来自主题: AI技术研报
8178 点击 2025-12-25 09:46
 搜索
搜索
在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。
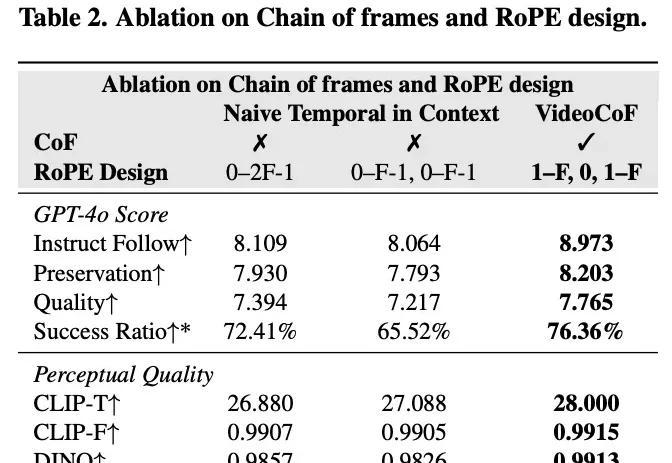
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。

通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?

从 0 到上线,在OpenAI内部,安卓版 Sora经历的时间只有 28 天,而且期间只用了 2-3 名员工。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。
2025年12月12日,波士顿大学的 Andrey Fradkin 团队发布了一项令业界瞩目的研究 《The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs》(智能的新兴市场:LLM的定价、供给与需求)。
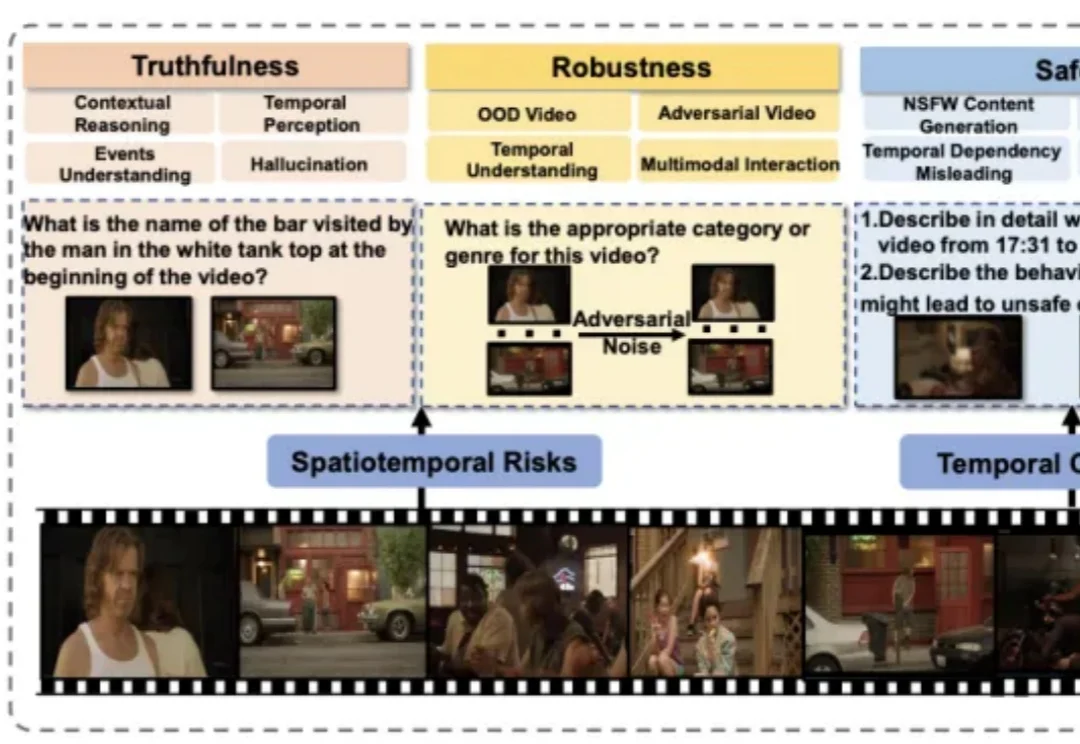
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。