ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制
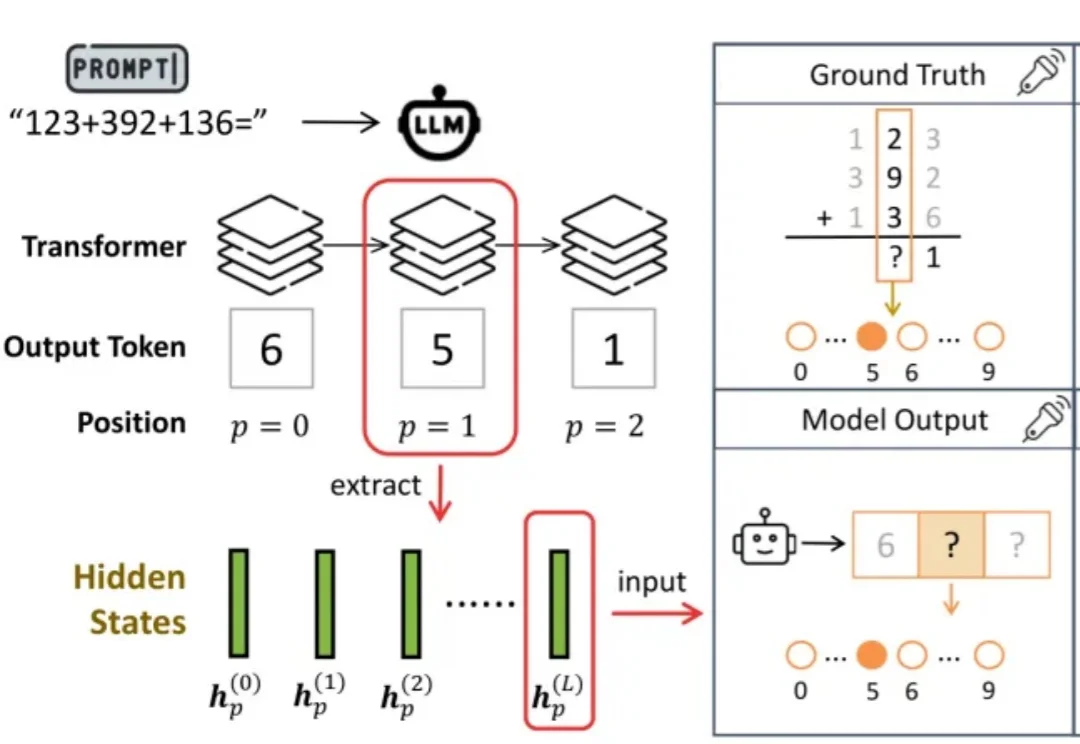
ICML 2026 | 大模型为什么算不对加法?南大团队提出等本位和轨迹,揭示LLM算术错误的几何机制尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
来自主题: AI技术研报
7366 点击 2026-06-17 14:05
 搜索
搜索
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。
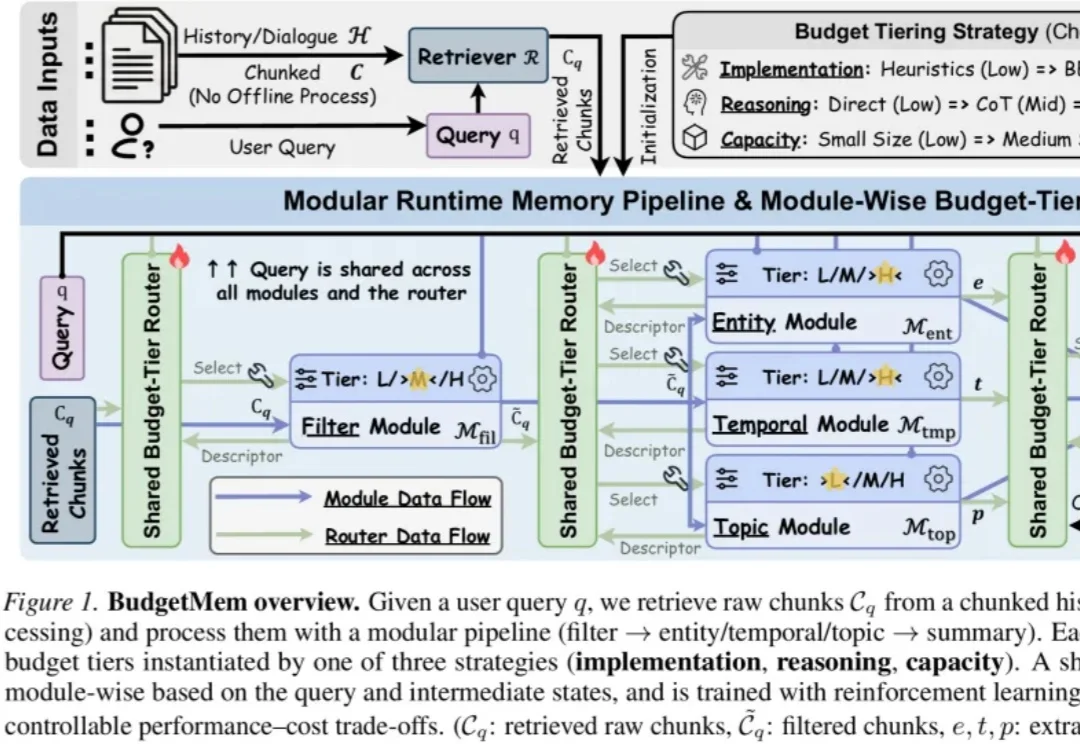
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

压力之下,刚刚,《连线》记者 Max Zeff 爆料称,Anthropic 正在撤销这一政策。该媒体从 Anthropic 获得了一份声明,其中写到:「我们正在调整 Fable 5 针对前沿 LLM 开发的安全限制,使其变得可见。」
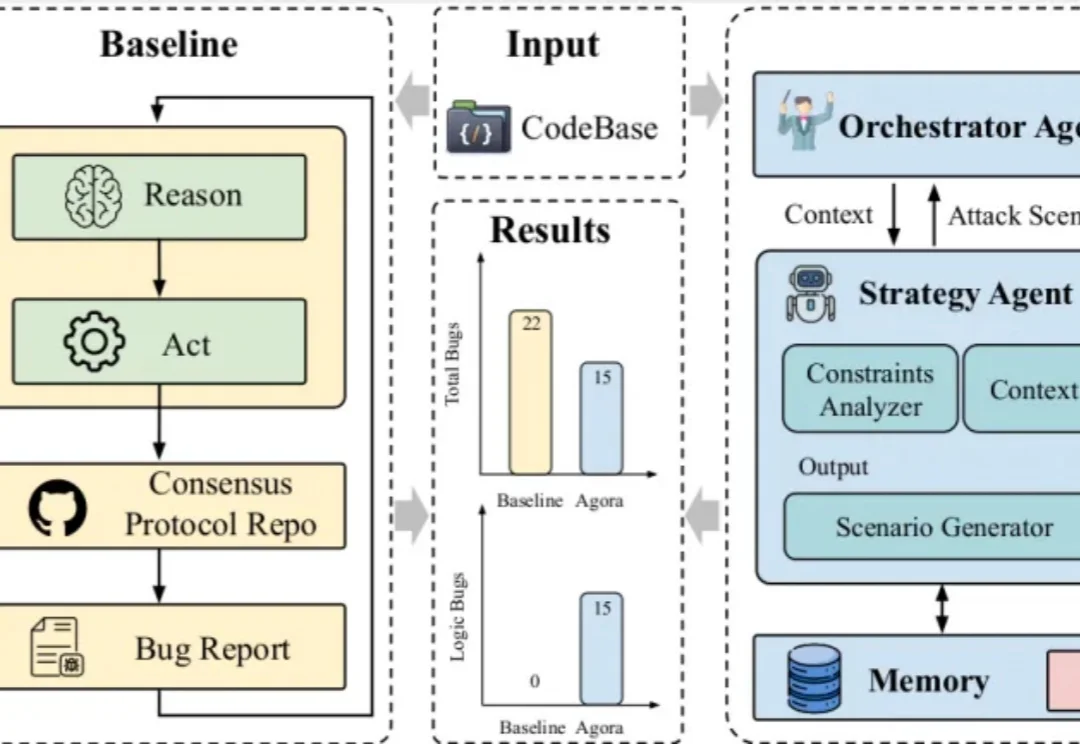
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。
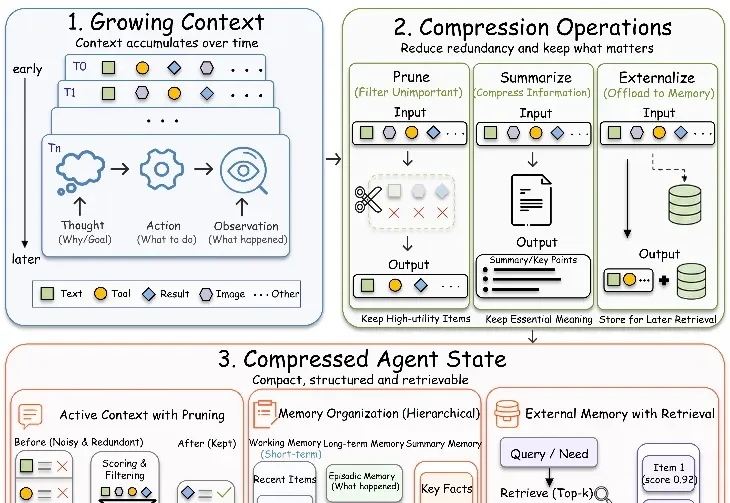
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。